Terminal AI Agents 2026 — Claude Code vs Codex CLI vs Gemini CLI
A side-by-side comparison of Claude Code, Codex CLI, and Gemini CLI on SWE-bench, output pricing, token efficiency, context size, and autonomy design. April 2026 numbers, with recommendations by scenario.
목차 (11)
- The three terminal AI agents — what each one is
- SWE-bench performance — the real score gap
- Pricing and free tiers
- Context windows and model versions
- Autonomy design — approval, sandbox, autonomous
- Open-source tooling and customization
- Full comparison table
- Which one for which situation
- Combining two — parallel workflows
- FAQ
- Wrap-up
April 2026 · AI News
Terminal-based AI coding agents settled into a three-way race in 2026. Anthropic's Claude Code, OpenAI's Codex CLI, and Google's Gemini CLI. All three run in the shell, not an IDE — a single command lets you read, modify, and commit files.
The real question is "which one?" SWE-bench scores cluster around 80% across all three, and pricing flips depending on the workload. Free tiers, context size, autonomy design, and token efficiency all shift the answer.
Short version: pick Claude Code if accuracy comes first, Codex CLI if you're chasing token efficiency, Gemini CLI if you want to start for free. Figures below are cross-checked against official pricing pages, benchmarks, and docs as of April 2026.
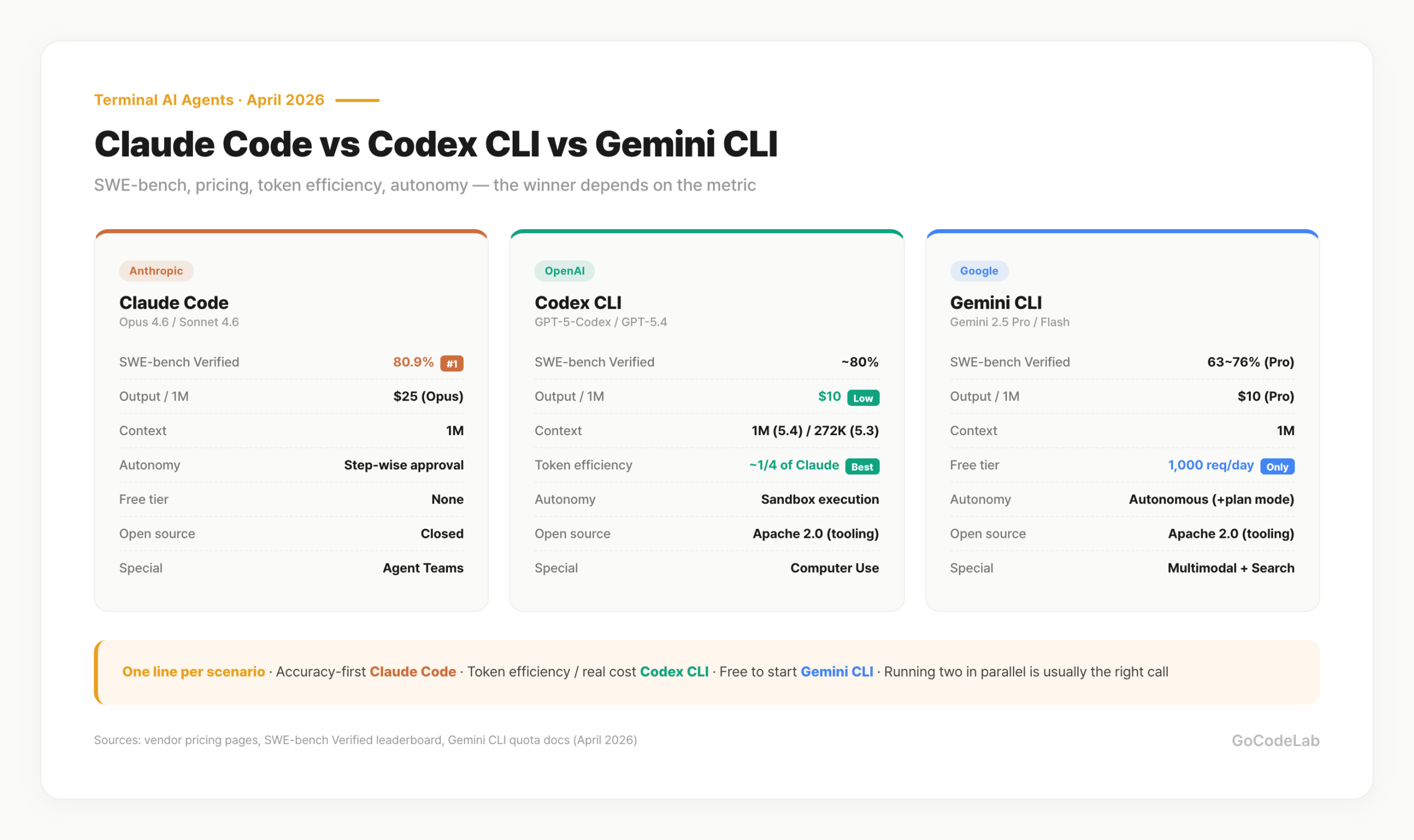
- Claude Code: SWE-bench Verified 80.9%, $25/1M output, closed tooling
- Codex CLI: Terminal-Bench 2.0 77.3% / SWE-bench ~80%, $10/1M output, Apache 2.0
- Gemini CLI: 1,000 req/day free with Google account auth, $10/1M output, Apache 2.0
- Token efficiency: Codex CLI uses roughly 1/4 the tokens vs Claude — real cost can flip
- 1M context: Claude Opus 4.6 / Gemini 2.5 Pro standard, Codex CLI from GPT-5.4 up
- Autonomy: Claude step-wise approval / Codex sandbox / Gemini autonomous execution
- The three terminal AI agents — what each one is
- SWE-bench performance — the real score gap
- Pricing and free tiers
- Context windows and model versions
- Autonomy design — approval, sandbox, autonomous
- Open-source tooling and customization
- Full comparison table
- Which one for which situation
- Combining two — parallel workflows
The three terminal AI agents — what each one is
Claude Code is Anthropic's agentic CLI, launched in 2025. It runs on Opus 4.6 / Sonnet 4.6. Default flow is "propose changes → user approves → execute." Step-wise approval keeps control in the developer's hands. Single-product ARR crossed $2.5B as of February 2026, putting it ahead of the pack in market adoption.
Codex CLI is OpenAI's open-source terminal agent from 2025. Apache 2.0 — the tooling source is public, and it defaults to the GPT-5-Codex model. Execution happens inside a sandbox, so you can inspect results in an isolated environment before writing to the real file system. GPT-5.4's Computer Use capability was folded into Codex CLI in March 2026.
Gemini CLI is Google's Apache 2.0 open-source tool, released in June 2025. It runs on Gemini 2.5 Pro / Flash. Google-account auth unlocks a free tier, and it ships with Google Search grounding, multimodal input, MCP, and plan mode built in. Taking screenshots or PDFs as input is unique to Gemini CLI among the three.
SWE-bench performance — the real score gap
SWE-bench Verified hands the AI real GitHub issues and asks it to resolve them as PRs. Autocompletion isn't enough — the agent has to analyze the issue, navigate the codebase, patch, and pass tests. As of April 2026:
- Claude Code (Opus 4.6): SWE-bench Verified 80.9% — #1 on stable models
- Codex CLI (GPT-5.4): SWE-bench roughly 80%, Terminal-Bench 2.0 77.3%
- Gemini CLI (Gemini 2.5 Pro): stable model 63~76%, 3.1 Preview reported at 80.6%
Claude Code and Codex CLI are in a statistical tie. Blind quality comparisons reported Claude Code winning 67% of head-to-head matchups — read as: Claude pulls ahead on code consistency, edge cases, and following project conventions. Codex CLI wins on response speed and token efficiency.
Express.js refactor benchmark (same task, no human intervention): Claude Code finished in 1h 17m with no fixups, Codex CLI 1h 41m no fixups, Gemini CLI 2h 4m needing 3 fixups. Real workloads preserve the stable-model SWE-bench ordering.
Pricing and free tiers
Pricing is per-token. Input and output tokens bill separately, and output is much pricier. Numbers below are from each vendor's April 2026 public pricing page.
| Model | Input / 1M | Output / 1M | Free Tier |
|---|---|---|---|
| Claude Opus 4.6 | $5 | $25 | None |
| Claude Sonnet 4.6 | $3 | $15 | None |
| GPT-5-Codex (Codex CLI) | $1.25 | $10 | None |
| GPT-5.4 (standard) | $2.50 | $15 | None |
| Gemini 2.5 Pro | $1 | $10 | Google account: 1,000 req/day |
| Gemini 2.5 Flash | $0.3 | $2.5 | 250 req/day (API key) |
On sticker price, Gemini 2.5 Pro and GPT-5-Codex tie at $10/1M output — under half of Claude Opus 4.6's $25/1M. But token efficiency flips the math. On the same task, Codex CLI has been repeatedly measured at roughly 1/4 the tokens Claude consumes. Even with a $25 vs $10 gap, a 4x token ratio reverses the real bill.
Gemini CLI's free tier hinges on how you authenticate. Google account (Gemini Code Assist) auth gets you 1,000 requests/day with 1M context. Switch to API key auth and you drop to Flash only, capped at 250 requests/day. Under heavy load, Pro requests also auto-downgrade to Flash — worth knowing before you depend on it.
Claude API offers up to 90% off via prompt caching and 50% off via batch processing. For repetitive coding-agent workloads, the real cost drops noticeably. Codex CLI and Gemini CLI have caching options too. The table is list price — the invoice reflects caching and batch usage.
Context windows and model versions
The context window is how many tokens the model processes in one shot. For large refactors or legacy analysis, you want the whole project to fit in one read so patterns are visible. April 2026 upper bounds:
- Claude Code: 1M tokens on both Opus 4.6 and Sonnet 4.6 (included in standard pricing since Feb 2026)
- Codex CLI: 1M on GPT-5.4 — GPT-5.3 is 272K, so verify the version
- Gemini CLI: 1M standard on Gemini 2.5 Pro
On stable models, 1M context is most battle-tested on Claude Opus 4.6 and Gemini 2.5 Pro. Codex CLI handles 1M on GPT-5.4, but some existing scripts still default to GPT-5.3. Before you throw it at a large codebase, pin the version with codex --model.
For small feature work, any of the three is fine. Context size only moves the needle on legacy analysis, multi-file refactors, or whole-test-suite reviews — when you need to scan tens of thousands of lines at once.
Autonomy design — approval, sandbox, autonomous
All three call themselves "agents," but how they actually run code differs. This is where the real-world experience diverges most.
Claude Code — step-wise approval. Asks for confirmation before writing files, running commands, or committing. Shows you a diff and says "apply this?" Not great for unattended automation, but it defaults to blocking bad edits from landing in production code. Agent Teams supports parallel work.
Codex CLI — sandbox execution. Runs inside an isolated sandbox, shows the result, then you decide whether to apply. The flow is "try first, judge from the outcome." Computer Use extends it into browser and GUI operations. Good for experimental work and large-refactor first drafts.
Gemini CLI — autonomous execution. Default minimizes approval prompts and runs to completion. Fast iteration, but for production code the recommended workflow is to plan first via --plan, then execute. Under traffic pressure, Pro auto-downgrades to Flash and output quality can wobble.
Open-source tooling and customization
Codex CLI and Gemini CLI both release their tooling as Apache 2.0 open source. You can modify and redistribute. In enterprise settings where you need to integrate with internal systems or add capabilities, this license difference can be decisive.
The models themselves aren't open source. GPT-5-Codex and Gemini 2.5 Pro remain proprietary to their vendors. Only the tooling layer is open — keep that distinction in mind. Claude Code's tooling is also closed; it calls the Anthropic API, so internal modification isn't really an option.
For personal use, open source doesn't change much. It matters in three scenarios: on-prem or air-gapped environments that need tooling changes; internal CI integrations where you wire in custom hooks; audit requirements that demand tooling source review. Claude Code drops out of the shortlist for all three.
Full comparison table
| Dimension | Claude Code | Codex CLI | Gemini CLI |
|---|---|---|---|
| SWE-bench Verified | 80.9% | ~80% / TB 77.3% | 63~76% (Pro) / 80.6% (3.1 Preview) |
| Output / 1M | $25 (Opus) / $15 (Sonnet) | $10 (GPT-5-Codex) | $10 (Pro) / $2.5 (Flash) |
| Free tier | None | None | Google account 1,000 req/day |
| Context | 1M (Opus 4.6) | 1M (GPT-5.4) / 272K (5.3) | 1M (Pro) |
| Token efficiency | baseline | ~1/4 of Claude | similar~slightly more |
| Autonomy | step-wise approval | sandbox execution | autonomous (plan mode optional) |
| Open source | closed | Apache 2.0 (tooling) | Apache 2.0 (tooling) |
| Special features | Agent Teams, extended thinking | Computer Use, sandbox | Search grounding, multimodal, plan mode |
| Company | Anthropic | OpenAI |
Which one for which situation
There isn't one selection criterion. The answer for cost-first differs from accuracy-first. By scenario:
| Scenario | Pick | Why |
|---|---|---|
| Accuracy-first coding | Claude Code | #1 on SWE-bench 80.9%, 67% blind-quality win rate |
| Token efficiency / real-cost savings | Codex CLI | $10/1M + ~1/4 token usage on same task |
| Free to start | Gemini CLI | Google account 1,000 req/day, 1M context |
| Large codebase refactor | Claude Code / Gemini 2.5 Pro | Stable 1M context, multi-file consistency |
| Experimental work / sandbox checks | Codex CLI | Isolated execution + diff review, Computer Use |
| Customization / on-prem | Codex CLI / Gemini CLI | Apache 2.0 tooling, internal modifications |
| Screenshot / PDF input needed | Gemini CLI | Multimodal input — unique among the three |
| Prefer step-wise review | Claude Code | Approval-before-write as default |
There's no absolute winner. Start from what you do most often. Accuracy-first → Claude Code. Cost-sensitive → Codex CLI. Want a free runway → Gemini CLI.
Combining two — parallel workflows
You don't have to pick one. Separating draft / review / execute across tools buys you speed, accuracy, and cost all at once. A realistic split:
gemini "Add email validation to src/components/Form.tsx"
# Step 2: Claude Code for code review and security check
claude "Review the Form.tsx changes and fix any security issues"
# Step 3: Large refactors in the Codex CLI sandbox
codex --model gpt-5-codex "Normalize all API routes to a RESTful pattern"
# → Inspect sandbox result, then decide whether to apply
From a cost-instinct angle: push repetitive queries (search, summaries, first-draft refactors) to Gemini CLI's free tier, keep quality review and security checks on Claude Code (paid), and route experimental automation and Computer Use through Codex CLI. Splitting like this often lands cheaper than staying on one tool.
No need to run all three. The right moment to add a second tool is when the first one starts hitting a wall. Example: if Claude Code's token cost starts hurting, branch off to Gemini CLI's free tier or Codex CLI's token efficiency.
FAQ
Q. Which of the three is free to use?
Gemini CLI is the only one with a meaningful free tier. Google-account auth (Gemini Code Assist) unlocks 1,000 requests/day and 1M context. Under traffic, Pro calls may auto-downgrade to Flash. API key auth drops you to Flash only at 250 requests/day.
Q. Which one tops SWE-bench?
Claude Code at SWE-bench Verified 80.9% — #1 on stable models. Codex CLI on GPT-5.4 sits at about 80% (statistical tie). Stable Gemini CLI models are in the 63~76% range; the 3.1 Preview reported 80.6%. On blind quality comparisons, Claude held a 67% win rate.
Q. Which is the cheapest?
By sticker price, GPT-5-Codex and Gemini 2.5 Pro tie at $10/1M output. Claude Opus 4.6 is $25/1M — about 2.5x more. Factor in token efficiency and Codex CLI often wins in real spend: repeated measurements show it finishes the same task at roughly 1/4 of Claude's tokens.
Q. Which one is open-source and customizable?
Codex CLI and Gemini CLI ship their tooling under Apache 2.0 — source modification and redistribution allowed. The models themselves stay proprietary; only the tooling layer is yours to modify. Claude Code's tooling is closed.
Q. Which handles large codebases best?
Claude Code Opus 4.6 and Gemini 2.5 Pro — both solid on 1M context. Codex CLI hits 1M on GPT-5.4, but scripts pinned to GPT-5.3 fall back to 272K. Pin the model with --model before big runs.
Wrap-up
The three tools keep shipping updates. Numbers here are April 2026 baseline — benchmarks and pricing shift as model versions change. For now: start free with Gemini CLI, pick Claude Code if accuracy is primary, pick Codex CLI to lower real spend.
Running two in parallel is almost mandatory. Drafts on Gemini CLI free tier, quality review on Claude Code, experimental automation on Codex CLI — the split nets you speed, accuracy, and cost all at once. Get comfortable with one first, then add the second.
on a real project
Pricing and benchmark figures in this article are based on April 2026 data. Services update frequently — check the official docs for the latest numbers.
GoCodeLab has no affiliate relationship with any of the services covered.