I Built a SaaS in 7 Days
I Built a SaaS in 7 Days
On this page (10)
April 2026 · Lazy Developer EP.04
After building Apsity in EP.02, feedback from 12 apps started pouring in. Emails, reviews, DMs. At first I organized them in a spreadsheet. But “please add dark mode” and “my eyes hurt at night” are the same request, just written by different people in different words. Grouping similar requests, assigning priorities, notifying when they’re resolved. All manual. The spreadsheet kept growing but never got organized.
There’s a service called Canny. It does exactly this. Feedback collection, voting, roadmap. But the pricing starts at $79/month. Similar services aren’t much better. Nolt is $29, UserVoice is far more expensive. Too much for an indie developer. Same thing happened when I built Apsity. If existing tools are too expensive or don’t fit, I build my own. I decided to do the same this time.
I decided to build a SaaS with everything: feedback collection, AI auto-classification, public roadmap, changelog, voting, and email notifications. Named it FeedMission. This post is the record of how it started.
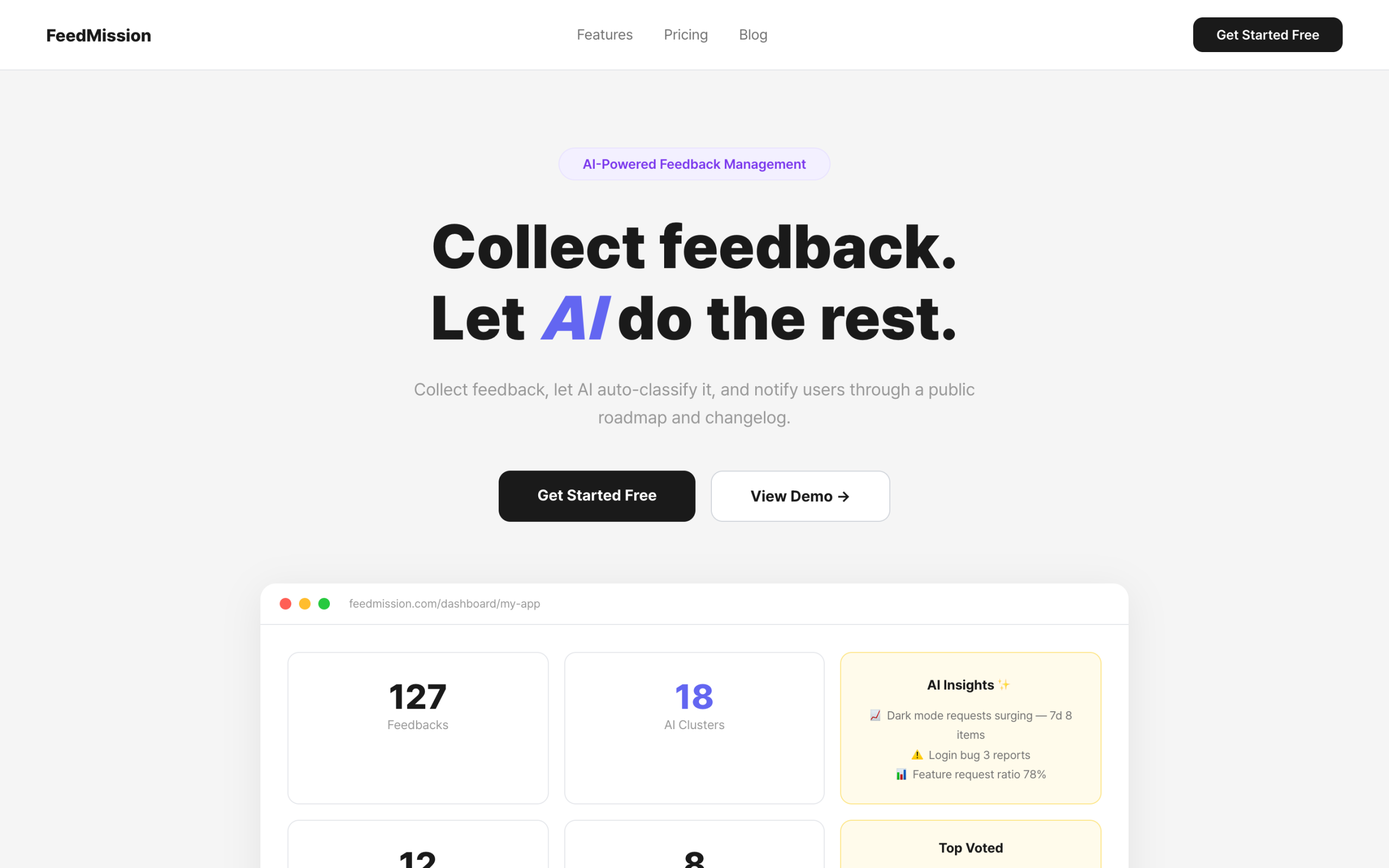
– Canny at $79/mo → too expensive for indie devs → decided to build it myself
– Designed AI clustering on top of the Next.js + Supabase stack I learned from Apsity
– Handed Claude a structured spec → MVP of 10,742 lines in 52 minutes
– 9 DB models, 12 APIs, 8 dashboard pages, widget, AI pipeline — all in one commit
– The real work came after the MVP — structural changes, performance, and security took far more time
I defined what I was building
I didn’t just tell Claude “make me a feedback tool.” I had the Apsity experience. I knew that specific requirements produce specific results. The CLAUDE.md automation from EP.01 worked on the same principle. First, I had to define what I actually wanted.
I signed up for Canny, Nolt, and Fider and used them myself. Features they all shared: feedback boards, voting, roadmap, changelog. That’s the baseline. But I wanted one more thing. When feedback piles up, I wanted it to automatically group similar items together. Doing it manually becomes practically impossible past 50 feedback items. Even Canny didn’t have this feature.
Here’s the summary.
Core: Feedback collection widget + public board + voting
Management: Roadmap kanban + changelog + email notifications
AI: Auto-classify similar feedback (embeddings + clustering)
AI: Sentiment analysis + auto-generated insights
Revenue: FREE / STARTER $9 / PRO $19 plans
Platforms: Script + React + iOS + Android + iframe + GTM
AI clustering was the key differentiator. Existing tools collect and display feedback. “Grouping similar items together” had to be built from scratch. The approach: convert feedback text into an array of numbers (embeddings), then automatically group items with similar number patterns. I’ll cover this in detail in the next episode.
I handed Claude the spec
Same approach as when I built Apsity. Opened a Claude session, pasted in the organized requirements. Got an architecture proposal first, and if it looked good, started implementation.
I based the stack on the combination I learned from Apsity. Next.js + Supabase + Vercel. On top of that, I needed a few additions.
Next.js — a framework I was already comfortable with
Supabase — auth + DB in one place. Seoul region
Vercel — deployment + Cron. Already knew the timeout workaround from EP.02
// New additions
Prisma — DB model management. Define a schema, types come out automatically
pgvector — vector search in PostgreSQL. Core of AI clustering
Voyage AI — converts text into 1024 numbers (embeddings)
LemonSqueezy — payments. Simpler tax handling than Stripe
Resend — email delivery. Used it in EP.03
The Apsity experience was huge. When to split Server Components and Client Components in Next.js, how to set up Supabase Auth middleware, how to bypass Vercel Cron timeouts with after(). Things I learned by hitting walls in EP.02, I could apply directly here.
The new things I had to learn were pgvector (vector search) and LemonSqueezy (payment integration). I worked through both of these with Claude.
The MVP came out in 52 minutes
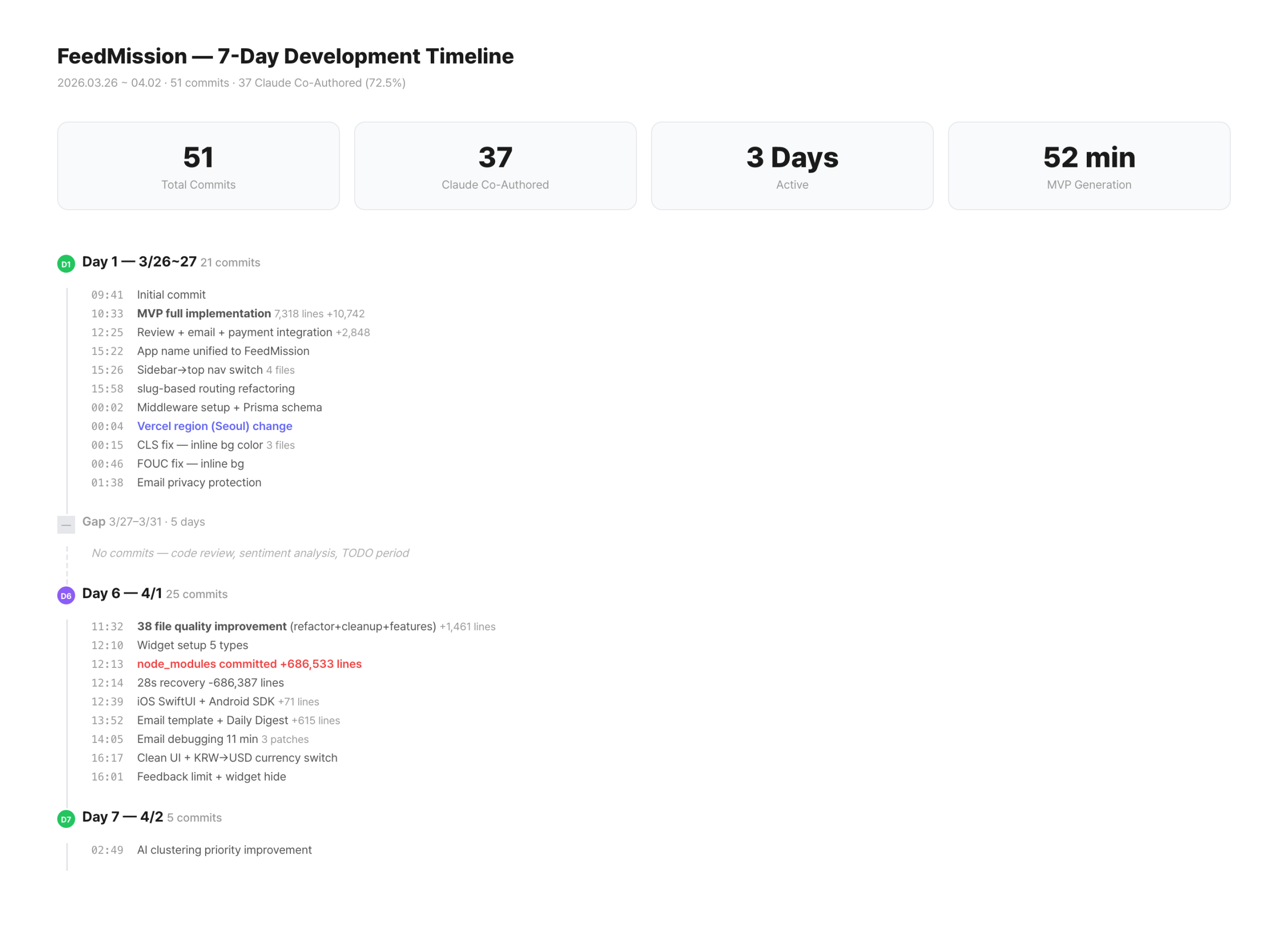
March 26, 9:41 AM. Started the project with create-next-app. Fed Claude the organized requirements and started building. DB model definitions, API routes, dashboard pages, public board, widget script, AI pipeline.
10:33 AM. Pushed the commit.
73 files changed, 10742 insertions(+)
52 minutes. 73 files. 10,742 lines. Faster than the Apsity MVP. Vibe coding is fast, but the reason isn’t “Claude wrote the code” — it’s “I knew exactly what I was building.” When requirements are clear, Claude’s output is precise. Conversely, if you throw a vague request like “make me a feedback tool,” you get a structure you didn’t want, and it actually takes longer.
Same thing happened in EP.02. “An indie developer running multiple iOS apps wants to see all revenue on one screen” was just two lines. But before writing those two lines, there was time spent figuring out what I actually wanted. The real speed of vibe coding comes from decision speed, not code generation.
What was inside the MVP
Opening the code that came out in 52 minutes, here’s the structure.
User, Project, Feedback, Cluster, RoadmapItem,
Changelog, Vote, NotificationLog, Subscription
// 12 API routes
/api/feedback — feedback CRUD + widget CORS
/api/clusters — AI cluster view/edit
/api/roadmap — roadmap kanban CRUD
/api/changelog — changelog + auto email on publish
/api/dashboard — stats aggregation (8 queries in parallel)
/api/insights — AI insight card generation
…
// 8 dashboard pages
Overview, Feedback, Clusters, Roadmap,
Changelog, Notifications, Widget, Settings
// 3 AI pipeline files
clustering.ts — feedback → embedding → cluster assignment
embeddings.ts — Voyage AI vector generation + Claude sentiment analysis
summaries.ts — Claude generates cluster titles/summaries + insights
The Feedback model has an embedding vector(1024) column. Feedback text gets converted into 1024 numbers via Voyage AI and stored. pgvector handles similarity search on these numbers. “Please add dark mode” and “my eyes hurt at night” end up with similar number patterns and automatically get grouped together. That’s the core feature.
When feedback comes in, the user gets an immediate “received” response. Embedding generation and clustering run in the background using the after() pattern from EP.02. Same convenience-store analogy. The checkout is done instantly, and the receipt prints in the background.
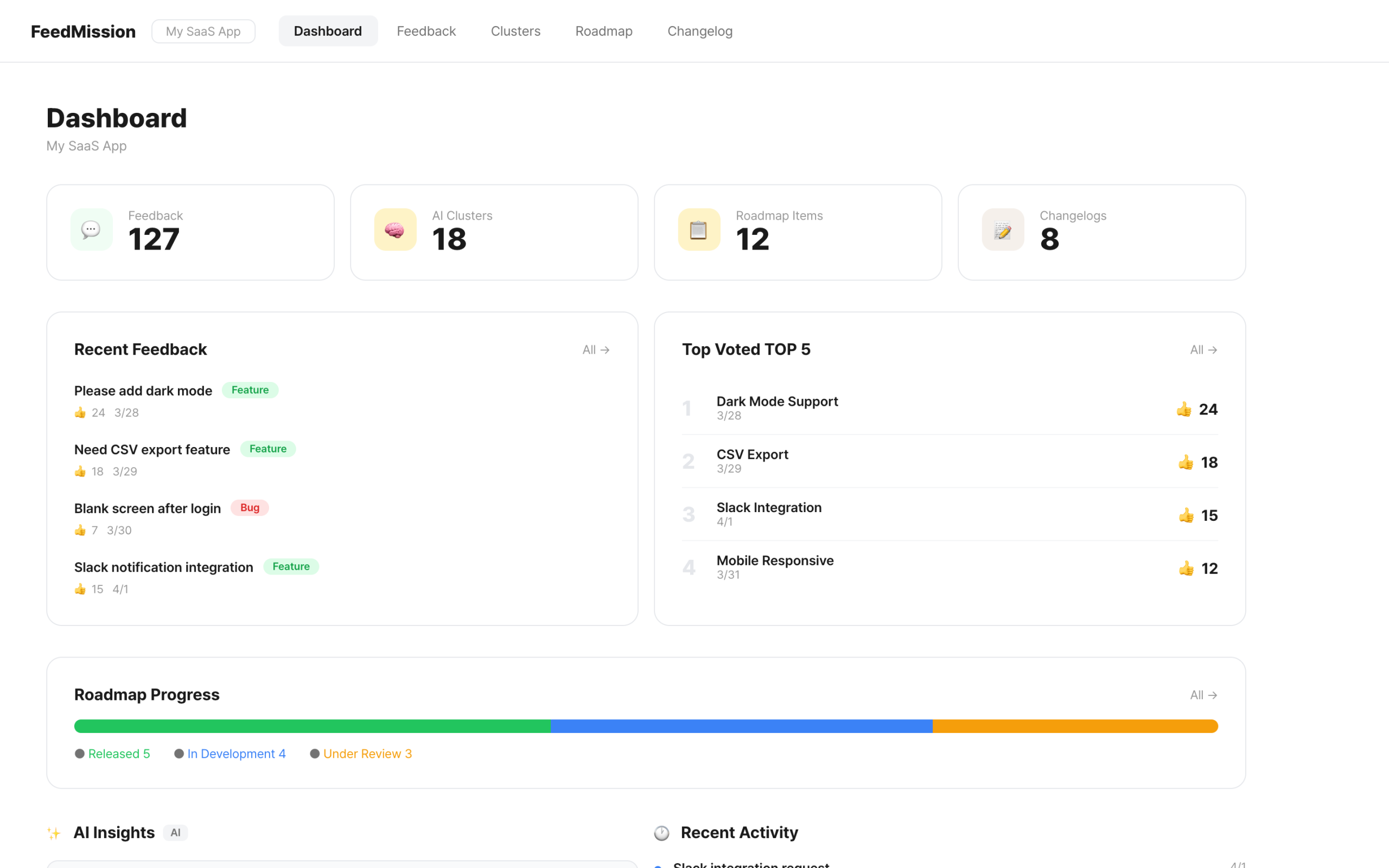
The gap between “working code” and “product”
It built successfully. No type errors either. But the moment I actually used it, things to fix started piling up.
First. The sidebar was eating too much screen space. Switching to a top navigation took 4 minutes. Second. UUIDs were baked into the URLs, producing addresses like /dashboard/clx7abc123def/feedback. I decided to refactor to slug-based routing. I thought it’d be just renaming folders, but 13 files were referencing params.projectId. Tracking them all down and fixing them took 30 minutes. Third. After deploying to production, it was slow. The Vercel Function was running in the US, while the Supabase DB was in Seoul. Every query was crossing the Pacific Ocean.
AI-generated code doesn’t catch these things. Between “working code” and “usable product,” there are layers of judgment calls like these. Same pattern as when I built Apsity. The MVP comes out fast, and the real time is spent on what comes after.
This is why you can’t ship AI-generated code as-is. Region settings, middleware optimization, security vulnerabilities, CLS — these only become visible when you actually run and use the code. Claude generates the first draft quickly, and I spend my time asking: “Why is this slow?”, “Is this URL structure right?”, “Should this data really be exposed?”
What happened over the next few days
By midnight on Day 1, I had 5 performance-related commits stacked up. Changed the Vercel region to Seoul (icn1), skipped unnecessary auth calls for public routes in middleware, added Prisma singleton caching, and matched skeleton heights to eliminate layout shift.
For 5 days I didn’t touch the code and just used it myself. Re-signed up for Canny and Nolt and compared. Wrote down what was lacking.
Came back on Day 6 and improved 38 files in one go. 7 security patches, 6 DB indexes, dashboard parallel query optimization. Expanded the widget SDK to 5 types, built iOS SwiftUI and Android Kotlin native widgets. Integrated LemonSqueezy payments and pivoted pricing from KRW to USD. Along the way, I accidentally committed 686K lines of node_modules and pushed a deletion commit 28 seconds later.
On Day 7, I revamped the landing page and improved the AI clustering priority formula.
Each of these processes — how AI clustering works, how security vulnerabilities were fixed, how the payment and plan system was built — will be covered one by one in the episodes that follow.
72.5% was AI, the rest was judgment
37 out of 51 commits have the Claude Co-Authored-By tag. 72.5%. This doesn’t mean “Claude built 72.5% of it.” I organize the requirements, Claude generates code, I review, modify, and commit. The Co-Authored tag gets added during this process.
Same pattern as EP.02. When I hand Claude requirements, an architecture proposal comes back. If it makes sense, I use it as-is. If not, I change direction. Judgment is always my job. Questions like “Is this structure right?”, “Is this security handling sufficient?”, “Is this pricing right?” Code generation got faster, but the volume of judgment didn’t decrease. In fact, because things get built faster, I had to make more decisions.
This is why vibe coding isn’t “letting AI do everything.” Build fast, use it fast, decide fast. What speeds up isn’t code generation — it’s the entire feedback loop.
In the next episode
FeedMission’s key differentiator is AI clustering. How “please add dark mode” and “my eyes hurt at night” end up in the same group. Converting feedback text to 1024 numbers, comparing them by cosine similarity, and automatically naming the groups. It’s all in 188 lines of clustering.ts. EP.05 covers that story.