Grok 4.20 Comparison — Faster Than GPT-5.4, But Is It Smarter?
We tested Grok 4.20 Beta 0309, released in March 2026. With 4 AI agents debating each other, 259 tokens per second output speed, and #1 non-hallucination rate on AA-Omniscience. Direct comparison with GPT-5.4 and Claude Sonnet 4.6 — which model fits which use case.
March 15, 2026 · A. Model/Tool Comparison
xAI first unveiled Grok 4.20 Beta on February 17. It was quickly followed by Beta 2 on March 3 and Beta 0309 (Reasoning version) on March 10. Three numbers stand out. An output speed of 259.7 tokens per second, the #1 non-hallucination rate on AA-Omniscience, and a completely new architecture where 4 AI agents debate each other. It’s over 4x faster than GPT-5.4, and we compared all three models — including Claude Sonnet 4.6 — head to head.What Is Grok 4.20?
Grok is the AI model built by Elon Musk’s xAI. It’s positioned similarly to GPT and Claude. First unveiled on February 17, Grok 4.20 has been updating rapidly. The latest version, Beta 0309 (March 10), comes in three variants: reasoning, non-reasoning, and multi-agent. Each serves a different purpose, and you can switch between them by toggling the reasoning parameter in the API. Compared to the previous Grok 4, the Intelligence Index went up by 6 points. The price actually went down, and the context window expanded dramatically from 256K to 2 million tokens.The 4-Agent Architecture Is the Key
The biggest differentiator of Grok 4.20 is its 4-agent architecture. For each question, 4 AI agents think simultaneously in different directions, debate, and then deliver a consensus conclusion. Each of the 4 agents has a name and a role.Grok — The captain. It breaks down the question, assigns tasks to other agents, resolves conflicts, and synthesizes the final answer.
Harper — The information gatherer. Collects relevant data and evidence.
Benjamin — The verifier. Checks the accuracy of Harper’s information and even reviews syntax in coding tasks.
Lucas — The devil’s advocate. Intentionally presents opposing views to the other three agents’ conclusions.
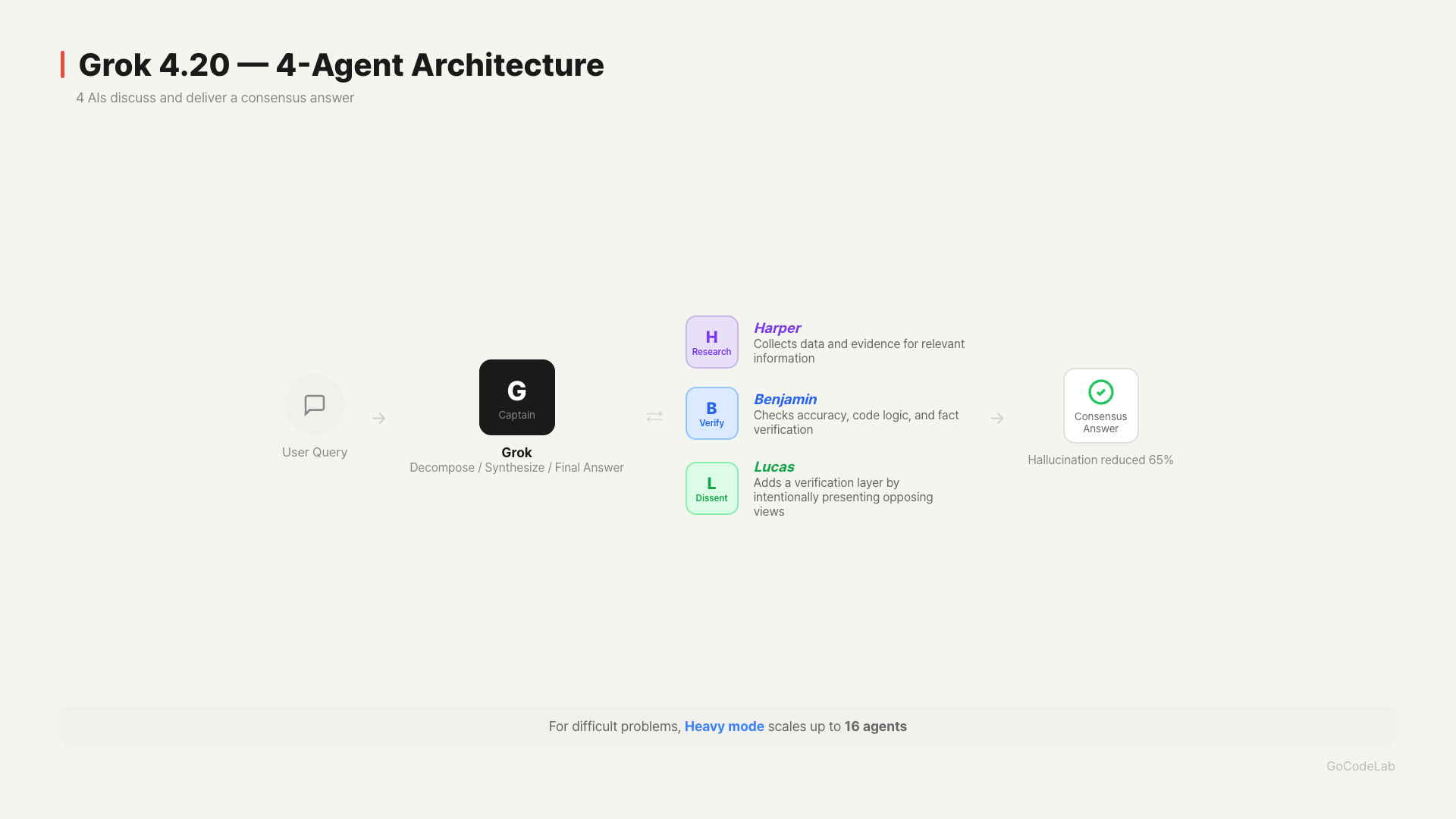 Lucas’s role is quite impressive. Trained specifically to present opposing views, it provides an extra layer of verification even when the other three agree. According to xAI, this structure contributed to a 65% reduction in hallucinations.
For difficult problems, it can scale up to 16 agents in “Heavy” mode.
Lucas’s role is quite impressive. Trained specifically to present opposing views, it provides an extra layer of verification even when the other three agree. According to xAI, this structure contributed to a 65% reduction in hallucinations.
For difficult problems, it can scale up to 16 agents in “Heavy” mode.
Key Metrics Comparison
Here’s how the three models compare on core metrics under the same conditions.| Metric | Grok 4.20 Beta | GPT-5.4 | Sonnet 4.6 |
|---|---|---|---|
| AI Intelligence Index | 48 | 57 | 54 |
| Output Speed | 259.7 tokens/sec | ~60 tokens/sec | ~80 tokens/sec |
| Time to First Token | 8.93s | ~2.7s | ~3s |
| Input Price | $2/M | $2.5/M | $3/M |
| Output Price | $6/M | $10/M | $15/M |
| Context Window | 2M tokens | 1M tokens | 1M tokens |
| Non-Hallucination Rate | 78% (#1) | Not officially released | Not officially released |
| Coding Index | 42.2 | 40.1 | 41.8 |
| Release Status | Beta | Stable Release | Stable Release |
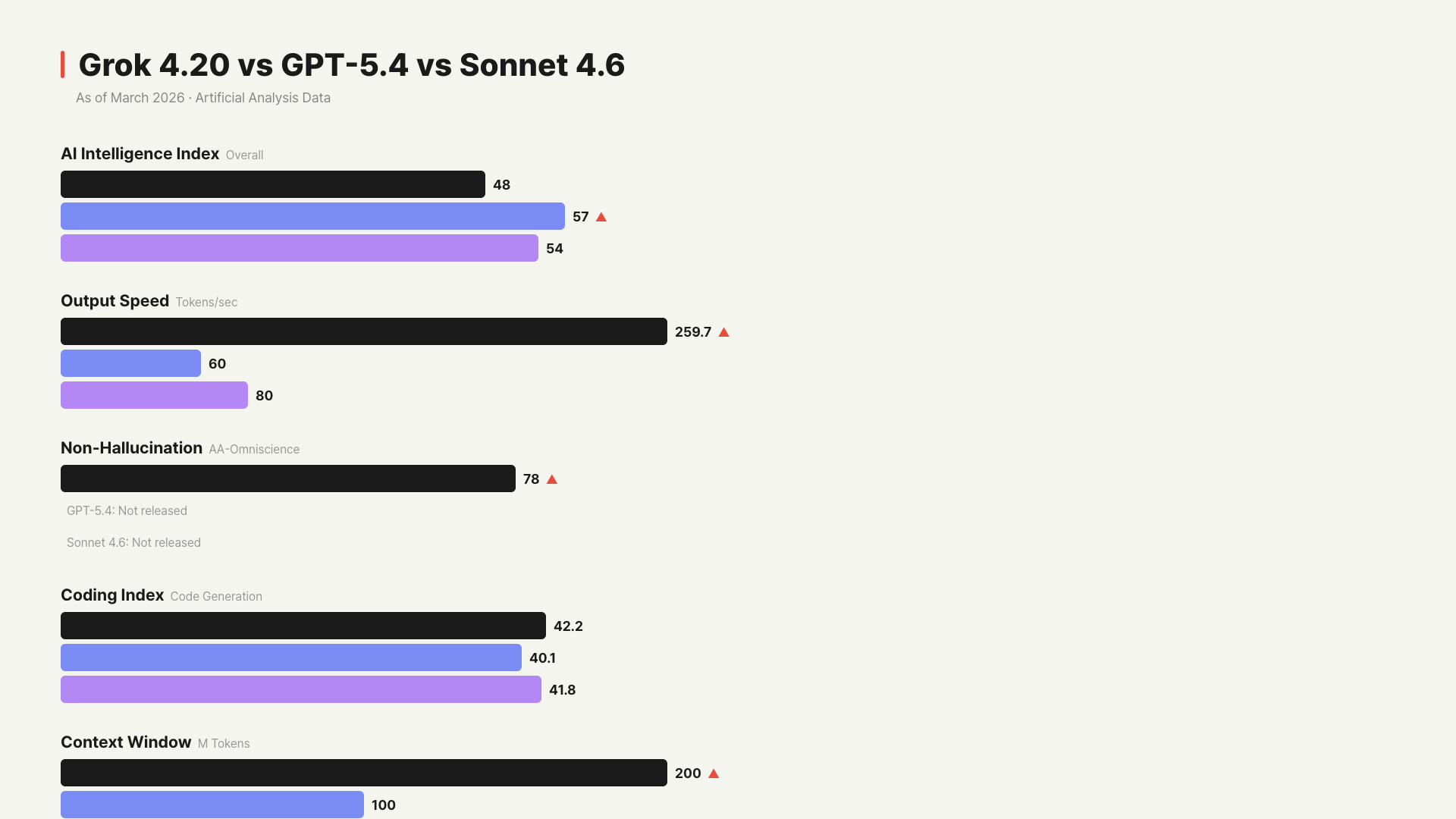 Looking at the numbers alone, GPT-5.4 is the smartest, Grok 4.20 is the fastest, and Claude Sonnet 4.6 is strongest at coding.
Looking at the numbers alone, GPT-5.4 is the smartest, Grok 4.20 is the fastest, and Claude Sonnet 4.6 is strongest at coding.
The Speed Difference Is Real
To put 259.7 tokens per second in perspective — it’s over 4x faster than the median speed of reasoning models in the same price range (61.9 tokens/sec). When generating long reports or code blocks, the wait time is noticeably shorter. This speed advantage is especially significant during repetitive work tasks. However, time to first response (TTFT) is 8.93 seconds, which is a bit long. That’s the time for the 4 agents to debate first. The first character appears slowly, but then the output pours out quickly after that.The #1 Non-Hallucination Rate Actually Matters
AA-Omniscience is a benchmark that measures factual accuracy and hallucination frequency across 6,000 questions in 42 domains. Grok 4.20 scored 78% for non-hallucination rate — #1 among all models tested. xAI says hallucinations dropped by about 65% compared to the previous Grok 4. The 4-agent structure acts as a self-verification layer. Harper gathers information, Benjamin verifies it, Lucas challenges it, and Grok cross-validates the result. That said, 78% means 22% can still be wrong. It doesn’t mean “no hallucinations.”The Pricing Is Quite Reasonable
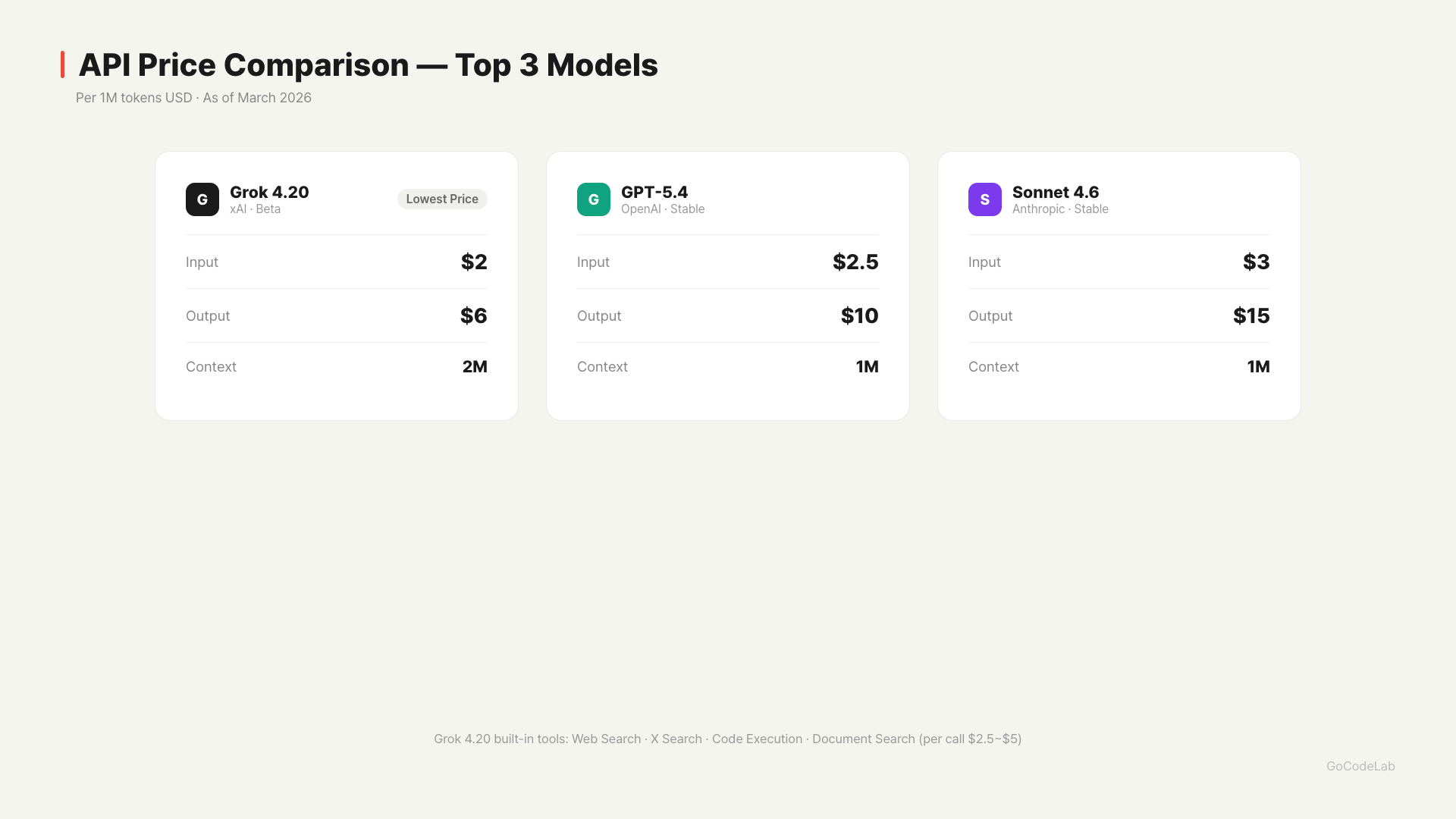 Grok 4.20’s output cost of $6/M is clearly cheaper than GPT-5.4 ($10/M) and Sonnet 4.6 ($15/M). The cost difference adds up for output-heavy tasks.
It also offers built-in tools. Web Search, X Search, Code Execution, and Document Search are available directly through the API, with separate charges of $2.50–$5 per call.
Grok 4.20’s output cost of $6/M is clearly cheaper than GPT-5.4 ($10/M) and Sonnet 4.6 ($15/M). The cost difference adds up for output-heavy tasks.
It also offers built-in tools. Web Search, X Search, Code Execution, and Document Search are available directly through the API, with separate charges of $2.50–$5 per call.
Where Does the Intelligence Score Gap Come From?
On Artificial Analysis’s AI Intelligence Index, GPT-5.4 scores 57, Claude Sonnet 4.6 scores 54, and Grok 4.20 scores 48. Gemini 3.1 Pro also matches GPT-5.4 at 57. GPT-5.4 surpassed actual job expert levels in 83% of occupations on the GDPval benchmark. This measures how well a model answers real-world professional questions — different from just solving logic puzzles well. Grok 4.20 doesn’t match GPT-5.4 on this metric yet.Which Model Fits Which Situation?
Each of the three models works better in different scenarios.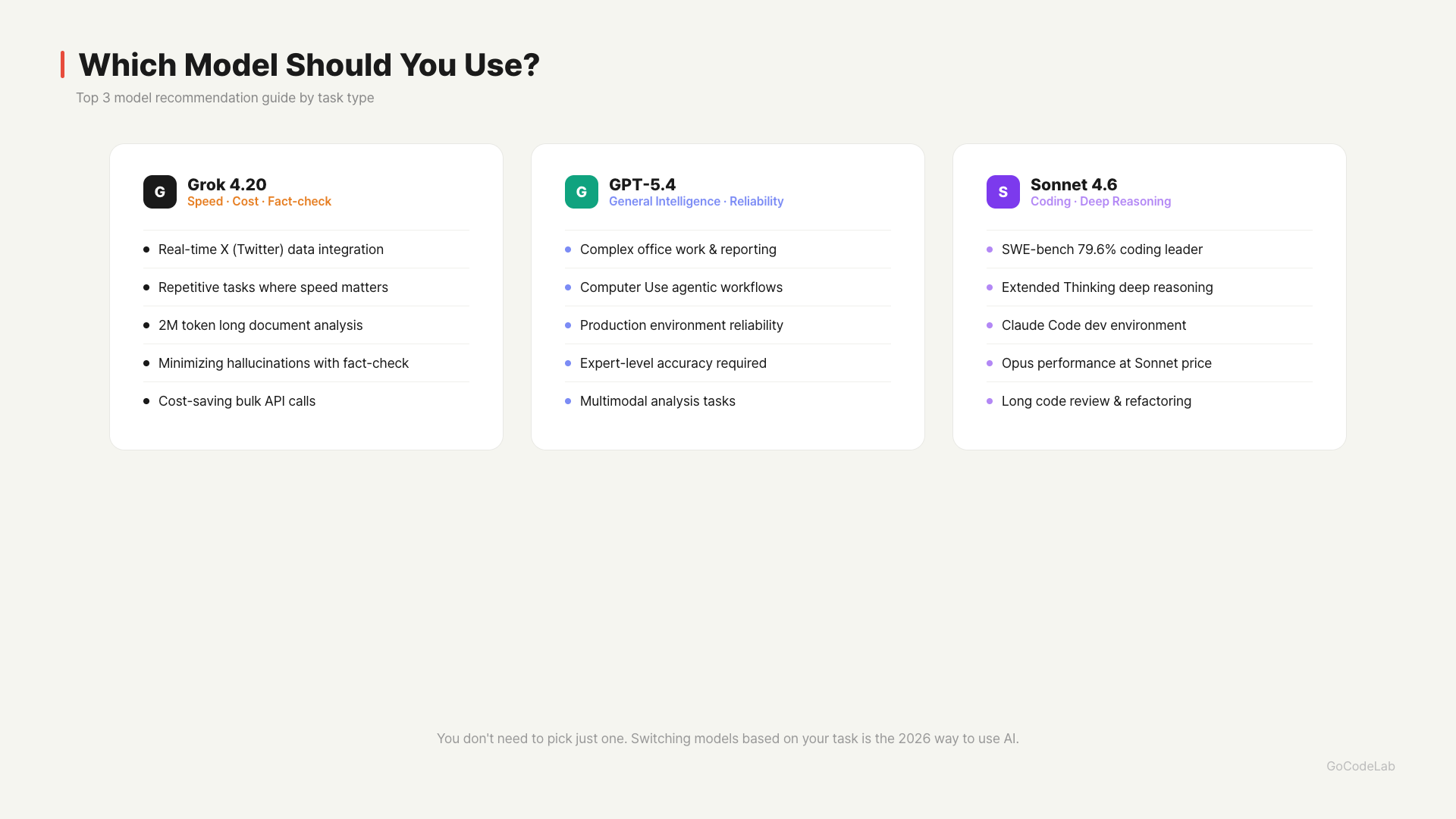 When Grok 4.20 has the edge: When you need real-time X (Twitter) data, speed-critical repetitive tasks (code generation, translation, etc.), analyzing entire long documents (2M token context), fact-checking tasks that need minimal hallucination, and high-volume API calls where you want to save on output costs.
When GPT-5.4 has the edge: Complex office tasks (document writing, data analysis, reporting), agentic tasks that involve direct computer operation, production environments where consistent and reliable results matter, and tasks requiring expert-level accuracy.
When Claude Sonnet 4.6 has the edge: Coding tasks (SWE-bench 79.6%, top tier), cases requiring deep reasoning with Extended Thinking, the Claude Code development environment, and when you want Opus-level performance at Sonnet pricing.
You don’t have to pick just one. Choosing the right model for each task type is the key to AI usage in 2026.
When Grok 4.20 has the edge: When you need real-time X (Twitter) data, speed-critical repetitive tasks (code generation, translation, etc.), analyzing entire long documents (2M token context), fact-checking tasks that need minimal hallucination, and high-volume API calls where you want to save on output costs.
When GPT-5.4 has the edge: Complex office tasks (document writing, data analysis, reporting), agentic tasks that involve direct computer operation, production environments where consistent and reliable results matter, and tasks requiring expert-level accuracy.
When Claude Sonnet 4.6 has the edge: Coding tasks (SWE-bench 79.6%, top tier), cases requiring deep reasoning with Extended Thinking, the Claude Code development environment, and when you want Opus-level performance at Sonnet pricing.
You don’t have to pick just one. Choosing the right model for each task type is the key to AI usage in 2026.
Hands-On Impressions
The speed claim is real. When generating long text, the difference compared to GPT and Claude models was noticeable. The 4-agent debate structure produced quite good results on complex math problems and coding tasks. Unlike a single model, there’s a sense of review from multiple angles. Results that included Lucas’s counterarguments had noticeably less bias. The downside was response consistency. When asking the same question multiple times, Grok 4.20 tended to produce more variable results than GPT-5.4. The debate outcome between the 4 agents differs slightly each time. This is partly because it’s still in beta. The 8.93-second TTFT feels quite long in practice. It’s confusing at first — “fast” but with a slow first response. It makes sense when you think of it as the agents debating first. Bottom line: Grok 4.20 has clear advantages in speed, cost, and non-hallucination rate. GPT-5.4 leads in general intelligence and Claude Sonnet 4.6 in coding, but Grok has carved out a clear niche for itself.FAQ
Q. Can I use Grok 4.20 for free?
X (Twitter) Premium subscribers get partial free access. For API usage, pricing is $2/M input and $6/M output. Check the official xAI website for exact free usage limits.Q. How well does Grok 4.20 handle Korean?
Korean performance is still behind GPT-5.4 and Claude compared to English. If you primarily work with Korean documents, GPT or Claude is more reliable.Q. What’s the difference between the 4-agent and 16-agent Heavy mode?
The default uses 4 agents (Grok, Harper, Benjamin, Lucas) working together. For harder problems, Heavy mode scales up to 16 agents. Heavy mode takes longer to respond but improves accuracy.Q. How are the reasoning and non-reasoning versions different?
The reasoning version is suited for tasks requiring complex inference. The non-reasoning version is faster and cheaper for simple Q&A or classification tasks. You can switch between them using the reasoning parameter in the API.Q. What does the #1 non-hallucination rate on AA-Omniscience mean?
AA-Omniscience is a benchmark that measures AI factual accuracy across 6,000 questions in 42 domains. Grok 4.20’s 78% #1 ranking means it gave the most factually accurate answers among all AI models tested. However, 22% can still be wrong.Q. Which should I use — GPT-5.4, Claude Sonnet 4.6, or Grok 4.20?
You don’t need to pick just one. GPT-5.4 for general office work, Claude Sonnet 4.6 for coding, and Grok 4.20 when speed matters or you need real-time X data. Switching models based on the task is the most practical approach.Q. Should I use Grok 4.20 now, or wait for the stable release?
If speed matters to you or you need real-time X data, it’s already usable now. There’s talk that xAI is preparing a stable release for Q2. Personally, using it alongside other models while watching how it improves is the most realistic approach.Wrap-Up
Grok 4.20 Beta 0309 introduced a new approach to AI model design. The structure of 4 agents debating rather than a single model actually worked for reducing hallucinations and coding performance. It has clear advantages in speed, cost, and non-hallucination rate, but still falls short of GPT-5.4 and Gemini 3.1 Pro in general intelligence. However, it’s updating weekly and has a stable release coming in Q2, so future improvements are worth watching. The 2026 AI market is no longer about “one best model” — it’s about choosing the right model for the right task. Grok 4.20 is definitely a meaningful addition to those choices.If this Grok 4.20, GPT-5.4, and Claude Sonnet 4.6 comparison was helpful, subscribe to the GoCodeLab blog. We’ll test and compare every new model that comes out.
This article was written on March 15, 2026. AI models update rapidly, so numbers and features may differ depending on when you read this.
At GoCodeLab, we test AI tools hands-on and share honest reviews. Subscribe to the blog for more AI news.
Related posts: DeepSeek V4 Launch Review · GPT-5.4 Thinking Update Summary · Claude Sonnet 4.6 Complete Guide