Claude Sonnet 4.6 출시 총정리 — Opus보다 더 잘한다고요?
Claude Sonnet 4.6 출시 총정리 — Opus보다 더 잘한다고요?
목차 (8)
2026년 3월 13일 · AI 트렌드 분석
Claude Sonnet 4.6이 2월 17일에 나왔어요.
가격은 Opus 4.6의 5분의 1이에요. 그런데 어떤 평가에서는 Opus를 앞섰어요. 처음엔 좀 의아했거든요. 비싼 게 무조건 좋은 거 아닌가 싶었는데요. 벤치마크 숫자를 하나씩 뜯어보니 꽤 흥미로웠어요.
– 출시일: 2026년 2월 17일
– 실무 사무 평가(GDPval-AA)에서 전체 1위
– SWE-bench 코딩 점수는 Opus와 1.2%p 차이
– 1M 토큰 컨텍스트 윈도우 지원 (GA)
– 확장 사고(Extended Thinking) 지원
– Claude Code에서 Sonnet 4.5 대비 70% 선호
– 가격: 입력 $3 / 출력 $15 per 1M 토큰 (Opus의 20%)
Sonnet 4.6이 뭔데요?
Anthropic은 2026년 초에 새 모델 두 개를 내놨어요. Opus 4.6(2월 5일)과 Sonnet 4.6(2월 17일)이에요.
Opus는 Anthropic의 최상위 모델이에요. 가격도 제일 비싸요. Sonnet은 중간 티어 모델이에요. 빠르고 저렴한 게 장점이죠.
보통은 “비싼 Opus가 당연히 더 좋겠지”라고 생각하는데요. 이번에는 좀 달랐어요.
Anthropic 공식 설명에 따르면, Sonnet 4.6은 코딩, 컴퓨터 사용, 장문 맥락 추론, 에이전트 계획, 지식 작업, 디자인까지 전면 업그레이드됐어요. Free와 Pro 플랜에서 기본 모델로 지정됐고요.
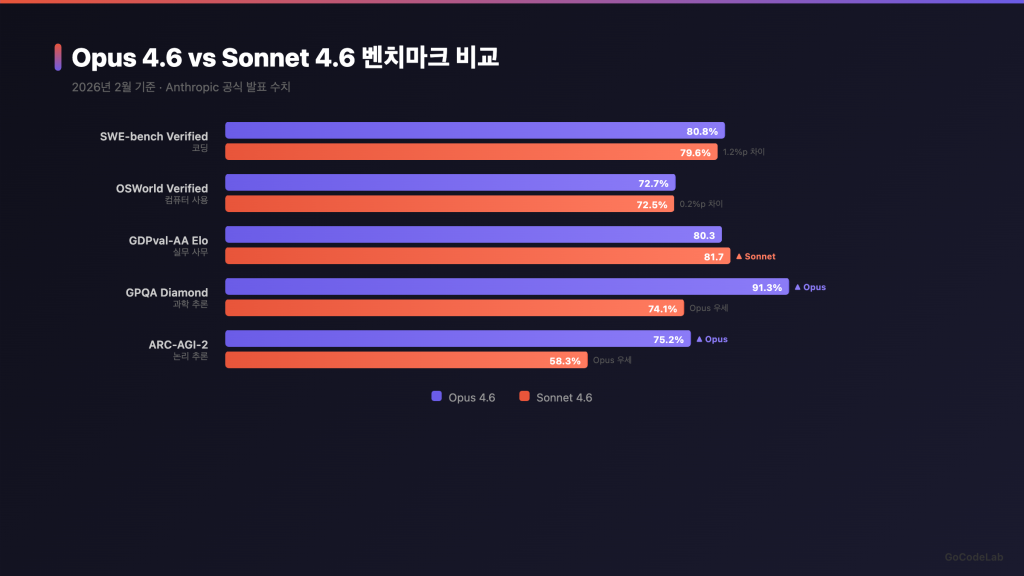
벤치마크로 보는 성능 차이
사무 작업: Sonnet이 1위
GDPval-AA Elo라는 평가가 있어요. 전문가 수준의 실무 사무 작업을 테스트하는 벤치마크예요. 이메일 작성, 문서 정리, 보고서 쓰기 같은 것들이죠.
여기서 Sonnet 4.6이 1,633점으로 전체 1위를 했어요. Opus 4.6(1,606점)보다 높고요. Gemini 3.1 Pro보다도 높았어요.
일반적인 사무 작업에서는 Sonnet이 더 나을 수 있다는 거예요.
코딩: 사실상 동급
SWE-bench Verified에서 Opus 4.6은 80.8%, Sonnet 4.6은 79.6%를 받았어요.
차이가 1.2%p밖에 안 나요. Anthropic 역사상 Opus와 Sonnet의 코딩 격차가 가장 작아요.
컴퓨터 사용 능력(OSWorld-Verified)도 Opus 72.7%, Sonnet 72.5%로 거의 같아요. 2024년 10월에 이 기능이 처음 나왔을 때 14.9%였거든요. 1년 반 만에 72.5%까지 올라온 거예요.
과학 추론: Opus가 확실히 앞서요
GPQA Diamond라는 대학원 수준의 과학 문제 벤치마크가 있어요. 여기서 Opus 4.6이 91.3%, Sonnet 4.6이 74.1%를 받았어요.
17%p 차이예요. 두 모델 간 가장 큰 격차가 나는 영역이에요.
고난도 추론: Opus 우세
ARC-AGI-2(순수 논리 추론)에서는 Opus 75.2%, Sonnet 58.3%였어요. Humanity’s Last Exam에서도 Opus 26.3%, Sonnet 19.1%였고요.
복잡한 전문 지식이나 다단계 추론이 필요하면 Opus가 더 안정적이에요.
| 항목 | Opus 4.6 | Sonnet 4.6 | 격차 |
|---|---|---|---|
| 출시일 | 2월 5일 | 2월 17일 | — |
| SWE-bench (코딩) | 80.8% | 79.6% | 1.2%p |
| OSWorld (컴퓨터 사용) | 72.7% | 72.5% | 0.2%p |
| GDPval-AA Elo (실무) | 1,606점 | 1,633점 | Sonnet 우세 |
| GPQA Diamond (과학) | 91.3% | 74.1% | 17.2%p |
| ARC-AGI-2 (추론) | 75.2% | 58.3% | 16.9%p |
| Humanity’s Last Exam | 26.3% | 19.1% | 7.2%p |
| API 가격 (입력/출력) | $15 / $75 | $3 / $15 | 5배 차이 |
한마디로 정리하면 이래요. 사무 작업과 컴퓨터 사용은 Sonnet이 같거나 앞서요. 과학 추론과 고난도 논리는 Opus가 확실히 앞서요. 코딩은 거의 같아요.
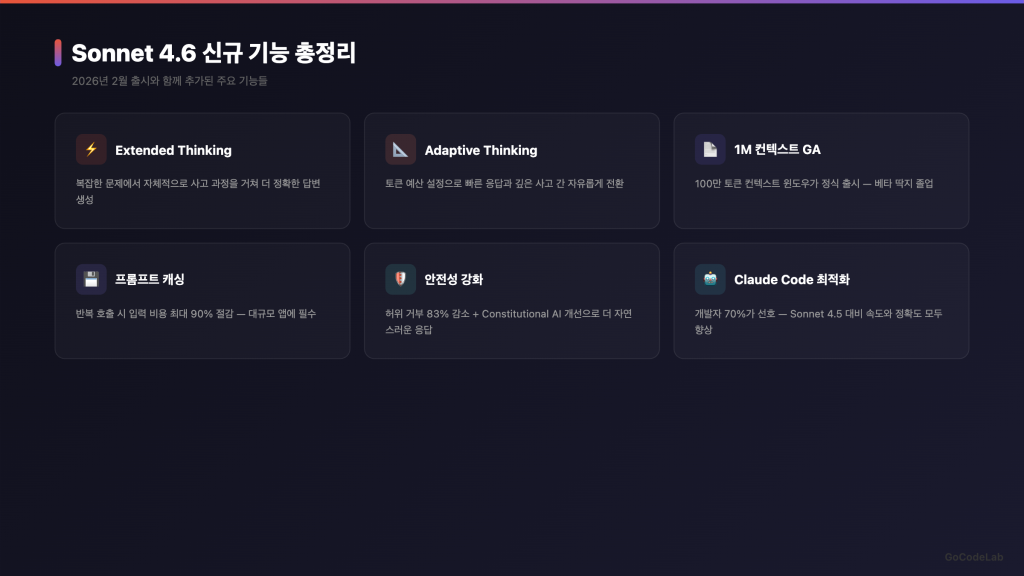
새로 추가된 기능들
1M 토큰 컨텍스트 윈도우
Sonnet 4.6은 1M 토큰 컨텍스트 윈도우를 지원해요. 베타로 시작했다가 이후 정식(GA)으로 전환됐어요.
100만 토큰이면 대략 책 7~8권 분량이에요. 긴 문서를 통째로 넣고 분석하거나, 대규모 코드베이스를 한번에 읽힐 수 있어요.
Anthropic에 따르면 전체 1M 윈도우에서도 정확도가 유지된다고 해요. 세대가 올라갈수록 장문 검색 성능이 개선되고 있다고 하고요.
확장 사고(Extended Thinking)
Sonnet 4.6은 확장 사고를 지원해요. 어려운 문제를 만나면 답변 전에 내부적으로 더 오래 생각하는 기능이에요.
적응형 사고(Adaptive Thinking)도 지원돼요. Claude가 요청의 난이도에 따라 생각하는 시간을 알아서 조절해요. 간단한 질문엔 바로 답하고, 복잡한 문제엔 더 깊이 생각해요.
프롬프트 캐싱
같은 프롬프트를 반복 사용하면 최대 90% 비용을 절감할 수 있어요.
캐시 읽기 토큰은 기본 입력 가격의 10%예요. 5분 캐시 쓰기는 1.25배, 1시간 캐시 쓰기는 2배고요. API를 많이 쓰는 기업이라면 꽤 유의미한 절감이에요.

안전성 개선
Sonnet 4.6의 안전성 평가 결과도 주목할 만해요. 프롬프트 인젝션 방어가 이전 모델 대비 크게 개선됐어요. Opus 4.6과 동급이라고 하고요.
안전성 연구팀은 이 모델이 “따뜻하고 정직하며, 강한 안전 행동을 보이고, 심각한 오정렬 징후가 없다”고 평가했어요.
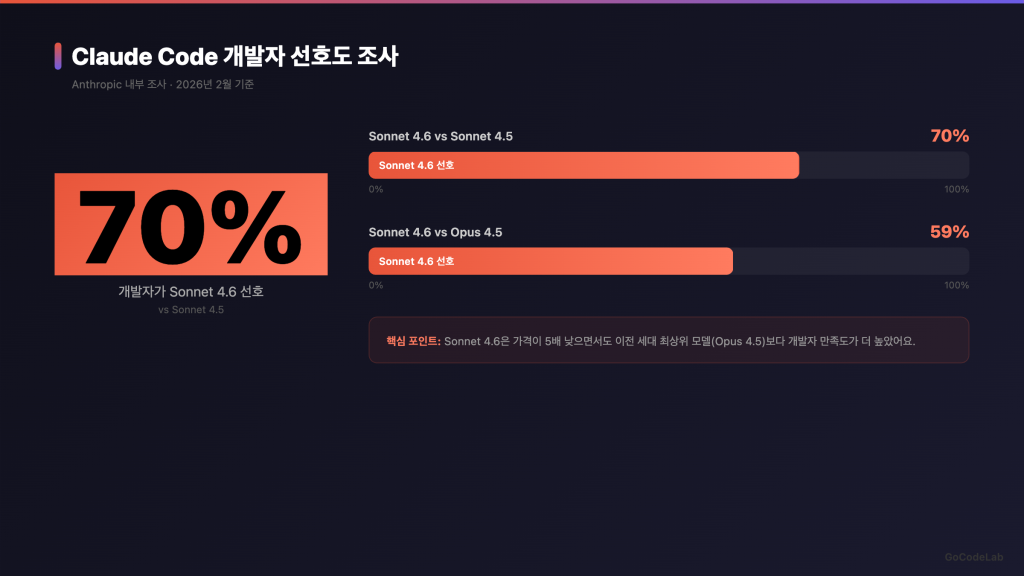
Claude Code에서 개발자 반응
Claude Code에서 테스트한 결과가 인상적이에요.
초기 사용자들이 Sonnet 4.6을 이전 버전인 Sonnet 4.5보다 70%의 경우 더 선호했어요. 2025년 11월의 최상위 모델이었던 Opus 4.5와 비교해도 59%의 경우 Sonnet 4.6을 골랐고요.
개발자들이 특히 언급한 개선점은 두 가지예요. 코드를 수정하기 전에 컨텍스트를 더 꼼꼼히 읽는다는 것. 그리고 공유 로직을 복제하지 않고 통합한다는 거예요.
이 두 가지가 실제 코딩 작업에서 체감이 크거든요. 코드를 여기저기 중복으로 만들지 않는다는 건 꽤 중요한 변화예요.
실제로 써보면 어때요?
직접 써본 느낌으로는, Sonnet 4.6이 이전 버전보다 분명 빨라졌어요. 응답 속도가 체감될 정도였어요.
일반 글쓰기, 이메일, 요약 같은 작업은 Sonnet 4.6으로도 충분했어요. 솔직히 Opus랑 구분이 잘 안 됐어요.
복잡한 코딩 문제나 여러 단계로 이어지는 추론은, 아직 Opus가 약간 더 안정적인 느낌이에요. 근데 그 차이가 전처럼 크진 않았어요.
컴퓨터 사용도 써봤는데요. 스프레드시트 탐색이나 다단계 웹 폼 작성 같은 작업에서 사람 수준의 능력을 보여줬어요. 여러 브라우저 탭을 넘나드는 것도 잘했고요.
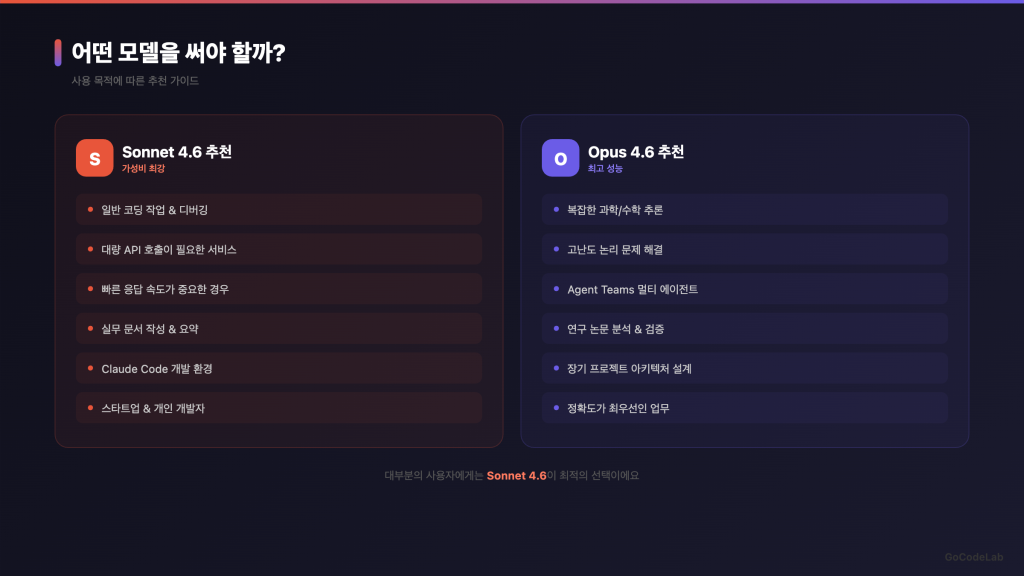
누구한테 의미 있는 변화예요?
기업 API 사용자가 가장 큰 수혜자예요. 코딩과 사무 작업에서 Opus와 거의 같은 성능을 5분의 1 가격에 쓸 수 있거든요. 프롬프트 캐싱까지 합치면 비용 절감이 상당해요.
일반 사용자는 Claude Pro 구독 시 두 모델 다 쓸 수 있어요. Free 플랜에서도 Sonnet 4.6이 기본 모델이에요. 필요에 따라 골라 쓰면 돼요.
개발자는 Claude Code에서 Sonnet 4.6을 기본으로 쓰는 게 효율적이에요. 코딩 성능 차이가 1.2%p밖에 안 되니까요. 정말 복잡한 아키텍처 설계가 필요할 때만 Opus를 쓰면 돼요.
Vertex AI / Azure 사용자는 바로 붙여 쓸 수 있어요. Sonnet 4.6은 Google Vertex AI Model Garden과 Microsoft Azure Foundry에서 공식 지원돼요.
한 가지 참고할 점이 있어요. Agent Teams 기능은 Opus 4.6에서만 쓸 수 있어요. 여러 Claude 인스턴스가 프로젝트를 동시에 작업하는 기능인데요. 이게 필요하다면 Opus를 써야 해요.
FAQ
Q. Sonnet 4.6이 Opus 4.6보다 무조건 낫나요?
아니에요. 사무 작업 평가에선 Sonnet이 앞섰지만, 과학 추론(GPQA Diamond)에서 17%p 차이로 Opus가 앞서요. 고난도 추론이나 전문 지식이 필요한 작업은 Opus가 더 안정적이에요. 작업 성격에 따라 달라요.
Q. Sonnet 4.6은 무료로 쓸 수 있나요?
Claude.ai Free 플랜에서 기본 모델로 쓸 수 있어요. Pro 구독($20/월)에서는 사용량 제한이 훨씬 넉넉하고 Opus도 함께 쓸 수 있어요.
Q. Claude Code에서 Sonnet 4.6 쓸 수 있나요?
쓸 수 있어요. Claude Code에서 기본 모델로 지원돼요. 개발자 초기 테스트에서 이전 Sonnet 4.5보다 70% 선호됐어요. 코드 컨텍스트를 더 잘 읽고, 로직 중복을 줄여준다고 해요.
Q. 1M 토큰 컨텍스트가 실제로 유용한가요?
대규모 코드베이스를 한번에 분석하거나, 긴 문서를 통째로 요약할 때 유용해요. Anthropic에 따르면 1M 윈도우 전체에서 정확도가 유지된다고 해요. 다만 토큰 사용량이 늘어나면 비용도 올라가니까 프롬프트 캐싱과 함께 쓰는 게 좋아요.
Q. Gemini 3.1 Pro랑 비교하면 어때요?
GDPval-AA 기준으로 Sonnet 4.6이 Gemini 3.1 Pro보다 높아요. 하지만 순수 추론(ARC-AGI-2)은 Gemini 3.1 Pro가 77.1%로 Claude Opus(75.2%)보다 높아요. 컨텍스트 윈도우는 Gemini가 200만 토큰으로 더 크고요. 용도에 따라 선택이 달라져요.
Q. API 가격 차이가 얼마나 나요?
Sonnet 4.6은 입력 1M 토큰당 $3, 출력 $15예요. Opus 4.6은 입력 $15, 출력 $75예요. 5배 차이가 나요. 프롬프트 캐싱을 쓰면 Sonnet은 캐시 읽기가 $0.30/1M 토큰까지 내려가요. 대량으로 쓰는 기업이라면 연간 수천만 원 차이가 날 수 있어요.
Q. 확장 사고는 어떻게 쓰나요?
API에서 적응형 사고(Adaptive Thinking)를 켜면 Claude가 알아서 판단해요. 쉬운 질문엔 바로 답하고, 복잡한 문제엔 더 깊이 생각해요. 수동으로 확장 사고 시간을 설정할 수도 있어요.
마무리
Sonnet 4.6은 “비싸야 좋다”는 공식을 확실히 흔들어 놨어요.
사무 작업에선 전체 1위. 코딩은 Opus와 1.2%p 차이. 컴퓨터 사용은 사실상 동급. 거기에 1M 컨텍스트, 확장 사고, 프롬프트 캐싱까지 전부 지원해요.
물론 과학 추론이나 고난도 논리에서는 Opus가 확실히 앞서요. 17%p 차이는 무시 못 하죠. Agent Teams 기능도 Opus 전용이에요.
결국 대부분의 작업에서는 Sonnet 4.6이 정답이에요. Opus는 정말 복잡한 추론이 필요할 때 꺼내 쓰는 도구가 된 거예요.
Claude Sonnet 4.6, 직접 써보고 내 작업에 맞는지 확인해보세요.
이 글은 2026년 3월 13일에 작성됐어요. 벤치마크 수치는 Anthropic 공식 발표 기준이에요. 실제 체감은 사용 환경에 따라 다를 수 있어요.
GoCodeLab에서는 AI 도구를 직접 써보고 솔직하게 알려드려요. 다른 AI 소식이 궁금하면 블로그를 구독해주세요.
관련 글: Gemini vs Claude vs ChatGPT 비교 · GPT-5.4 핵심 변화 정리 · DeepSeek V4 출시 정보 총정리