유저 피드백 정리하다 지쳐서 AI한테 분류 맡겼다
2026년 4월 · 귀찮은개발자 EP.05
On this page (13)
2026년 4월 · 귀찮은개발자 EP.05
EP.04에서 FeedMission을 7일 만에 만들었다. 위젯 붙이고 공개 보드를 열었더니 피드백이 오기 시작했다. 처음엔 좋았다. 피드백이 온다는 건 누군가 쓰고 있다는 뜻이니까.
근데 쌓이기 시작하면 다른 문제가 생긴다. “다크모드 넣어주세요.” “밤에 쓸 때 눈이 아파요.” “배경색 옵션 추가해주세요.” 세 사람이 세 가지 말을 했는데, 요청은 하나다. 이걸 수동으로 묶는 건 10개일 때는 괜찮다. 50개가 넘으면 읽기만 해도 시간이 간다.
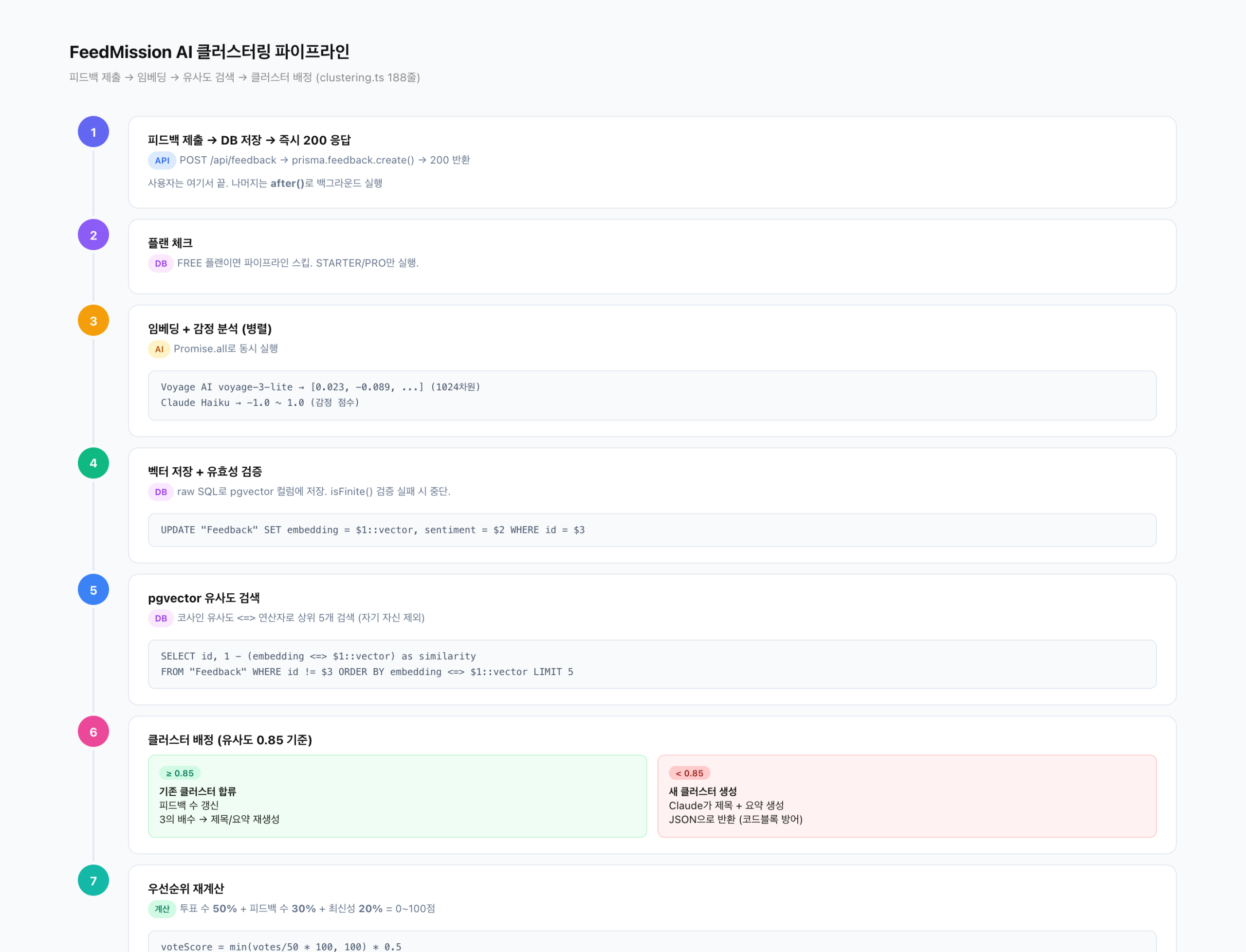
EP.02에서 수익 확인을 자동화하고, EP.03에서 분석 판단을 자동화했다. 이번엔 피드백 분류를 자동화할 차례였다. Claude한테 물어봤다. “비슷한 피드백을 자동으로 묶을 수 있어?” 답은 “임베딩”이라는 거였다.
– 피드백 텍스트를 Voyage AI로 1024개 숫자 배열로 변환 (임베딩)
– Claude Haiku로 감정 점수(-1.0 ~ 1.0) 동시 분석
– PostgreSQL에 pgvector 확장을 켜서 벡터 저장 + 유사도 검색
– 코사인 유사도 0.85 이상이면 같은 그룹, 미만이면 새 그룹 생성
– 그룹이 커지면 Claude가 이름과 요약을 자동으로 다시 지음
– 전체 파이프라인이 after() 패턴으로 백그라운드에서 돌아감
– clustering.ts 188줄에 전부 들어있다
“비슷한 피드백을 묶어줘” — 근데 어떻게?
“다크모드 넣어주세요”랑 “밤에 눈 아파요”는 글자가 하나도 안 겹친다. 근데 둘 다 같은 요청이다. 이걸 컴퓨터한테 알려주려면? 문장을 1024개 숫자로 바꾼다. 비슷한 의미면 비슷한 숫자가 나온다. 배달앱으로 치면 “야식 마렵다”가 치킨이랑 족발을 동시에 찾아주는 거다. 글자가 아니라 의미로 검색한다.
Claude한테 “비슷한 피드백을 자동으로 묶을 수 있어?”라고 물었더니, 이 숫자 배열을 “임베딩”이라고 한다고 했다. 문장마다 1024개 숫자로 된 좌표를 매기고, 좌표가 가까우면 비슷한 요청으로 판단하는 방식이다.
설명은 알겠는데 감이 안 왔다. 직접 돌려봤다.
Voyage AI로 첫 임베딩을 만들어봤다
Voyage AI라는 서비스를 썼다. API에 문장을 보내면 1024개 숫자가 돌아온다. 코드는 짧다.
const response = await fetch(‘https://api.voyageai.com/v1/embeddings’, {
body: JSON.stringify({
model: ‘voyage-3-lite’,
input: [“다크모드 넣어주세요”],
}),
})
// → [0.0234, -0.0891, 0.0412, …] (1024개)
API 하나 호출하면 끝이다. 돌아온 숫자 배열이 그 문장의 “의미 좌표” 같은 거다. “밤에 눈 아파요”도 비슷한 좌표가 나온다. 둘 사이의 거리를 재면 “이 두 문장이 얼마나 비슷한지”를 숫자로 알 수 있다.
감정 분석도 같이 돌렸다. Claude Haiku한테 “이 문장이 긍정인지 부정인지 -1에서 1 사이 숫자 하나만 줘”라고 시켰다. “다크모드 넣어주세요”는 0.1(중립), “왜 아직도 없어요?”는 -0.4(부정). 같은 요청이어도 온도가 다르다. 이걸 알면 “사용자가 짜증을 내기 시작하는 기능”을 먼저 처리할 수 있다.
이 두 작업은 Promise.all로 동시에 돌렸다. 순서대로 하면 500ms, 동시에 하면 300ms.
“피드백 두 개를 Claude한테 보내서 비슷한지 물어보면 안 되나?” 당연히 된다. 정확도도 더 높을 거다. 근데 피드백이 100개면 비교 조합이 4,950개다. 매번 Claude API를 호출하면 시간도 비용도 감당이 안 된다. 임베딩은 한 번만 만들어두면 비교는 DB가 수학으로 처리한다. 숫자끼리 거리 재는 건 API 호출 없이 밀리초 단위로 끝난다. 피드백이 1,000개가 돼도 검색 속도는 거의 같다.
임베딩 방식이 만능은 아니다. 숫자에 약하다. “버튼이 3개 필요해요”와 “버튼이 30개 필요해요”는 의미가 완전히 다른데, 임베딩 좌표는 거의 비슷하게 나온다. 부정어도 마찬가지다. “다크모드가 좋다”와 “다크모드가 별로다”가 비슷한 좌표에 찍힌다. 문장 구조가 비슷하면 의미가 반대여도 가깝게 나오는 거다. 알고는 있다. 근데 지금 FeedMission의 피드백 특성상 이런 케이스가 많지 않았다. 처음부터 이런 엣지 케이스까지 전부 잡으려고 하면 정작 핵심 기능이 안 나온다. 80%를 커버하는 구조를 빠르게 만들고, 나머지 20%는 실제로 문제가 생겼을 때 고치는 게 낫다. 피드백이 수천 건 쌓이고 오분류가 눈에 띄면 그때 보완하면 된다. 완벽하게 만들고 출시하는 것보다, 출시하고 고치는 게 빠르다.
pgvector — 숫자 1024개를 DB에 넣는 법
임베딩이 나왔다. 이걸 어디에 저장할지가 문제다. Pinecone 같은 전용 벡터 DB가 있다. 근데 이미 Supabase PostgreSQL을 쓰고 있다. 별도 DB를 또 관리하기 싫었다.
pgvector라는 PostgreSQL 확장이 있었다. 켜면 기존 DB에서 벡터를 저장하고 비교할 수 있다. Prisma 스키마에 한 줄 추가하면 된다.
model Feedback {
embedding Unsupported(“vector(1024)”)? // ← 이거
sentiment Float?
}
근데 문제가 있었다. Prisma는 pgvector를 공식 지원하지 않는다. Unsupported로 선언하면 스키마는 만들어지는데, 일반 Prisma API로는 이 컬럼을 읽거나 쓸 수 없다. SQL을 직접 써야 한다.
const vectorStr = `[${embedding.join(‘,’)}]`
await prisma.$executeRawUnsafe(
`UPDATE “Feedback”
SET embedding = $1::vector, sentiment = $2
WHERE id = $3`,
vectorStr, sentiment, feedbackId
)
1024개 숫자를 문자열로 만들어서 ::vector로 캐스팅한다. Prisma의 일반 모델은 그대로 쓰고, 벡터 관련만 raw SQL로 처리하는 하이브리드 구조가 됐다. 깔끔하지는 않지만 돌아간다.
“이것과 비슷한 걸 찾아줘” — 유사도 검색
벡터가 저장됐으니 비교할 수 있다. 새 피드백이 들어오면 기존 피드백들과 얼마나 비슷한지 점수를 매긴다. pgvector에 <=>라는 연산자가 있다. 코사인 거리를 계산해준다.
SELECT id, title,
1 – (embedding <=> $1::vector) as similarity
FROM “Feedback”
WHERE “projectId” = $2
AND id != $3 — 자기 자신 제외 (중요!)
ORDER BY embedding <=> $1::vector
LIMIT 5
1 - 거리로 변환하면 유사도가 된다. 1이면 동일, 0이면 무관. 그리고 AND id != $3. 이걸 빼먹어서 한참 헤맸다.
자기 자신이 유사도 1.0으로 매칭됐다. 당연하다. 자기 자신이 가장 비슷하니까. 모든 새 피드백이 기존 클러스터에만 합류하고, 새 클러스터가 절대 안 만들어졌다. “왜 전부 하나의 그룹에 들어가지?”라고 한참 들여다보다가 알아챘다. 한 줄 추가로 해결됐는데 찾는 데 오래 걸렸다.
자기 자신을 결과에서 제외하지 않으면 항상 유사도 1.0이 나온다. 모든 피드백이 “이미 있는 것과 똑같다”로 판정되어 새 그룹이 절대 생기지 않는다.
AND id != $3 한 줄이 전체 로직의 정확성을 좌우한다.
0.85가 정답이었다 — 임계값을 정한 과정
유사도가 나왔다. 근데 “얼마나 비슷하면 같은 요청인가?”를 정해야 한다. 이건 이론으로 정할 수 있는 게 아니었다. 피드백 20개를 만들어서 직접 실험했다.
0.85에서 “같은 요청을 다른 말로 한 것”이 잘 묶였다. 코드에서는 상수 하나로 관리한다.
클러스터 배정 — 합류하거나, 새로 만들거나
유사도 검색 결과로 두 가지 중 하나를 정한다. 0.85 이상인 피드백이 있으면 그 피드백이 속한 그룹에 합류한다. 없으면 새 그룹을 만든다.
const bestMatch = similar.find(
s => s.similarity >= 0.85 && s.clusterId
)
if (bestMatch) {
// 기존 그룹에 합류
} else {
// Claude한테 이름 지어달라고 하고 새 그룹 생성
}
그룹에 합류할 때마다 피드백 수를 갱신한다. 그리고 그룹이 커질 때마다 이름을 다시 짓는다.
if (count % 3 === 0 || count === 2) {
await refreshClusterSummary(clusterId)
}
왜 3의 배수인가. 피드백이 1개일 때 붙인 이름은 그 피드백 하나의 내용이다. 2개가 되면 공통점이 보이기 시작한다. 3개, 6개, 9개로 늘어나면 성격이 변할 수 있다. 매번 Claude를 호출하면 API 비용이 느니까, 3의 배수일 때만 갱신한다.
Claude가 그룹 이름을 짓는 방법
그룹에 속한 피드백들을 모아서 Claude Haiku한테 던진다. “이것들의 공통 주제를 30자 이내 제목과 80자 이내 요약으로 만들어줘. JSON으로.”
“Return ONLY valid JSON:
{\”title\”: \”…\”, \”summary\”: \”…\”}”
// Claude 응답 예시
{ “title”: “다크모드 / 테마 커스텀”,
“summary”: “사용자들이 다크모드와 테마 색상을 요청하고 있어요” }
잘 나왔다. 근데 가끔 Claude가 JSON을 코드블록으로 감쌌다. ```json ... ``` 형태로. 그대로 JSON.parse 하면 당연히 에러가 난다. 정규식으로 코드블록 마커를 벗기는 방어 코드를 넣었다.
if (text.startsWith(‘“`’)) {
text = text.replace(/^“`(?:json)?\s*\n?/, ”)
.replace(/\n?“`\s*$/, ”)
}
AI 응답은 100% 예측할 수 없다. 항상 fallback이 있어야 한다. 파싱이 실패하면 텍스트 전체를 제목으로 쓴다.
우선순위 — 뭘 먼저 봐야 하나
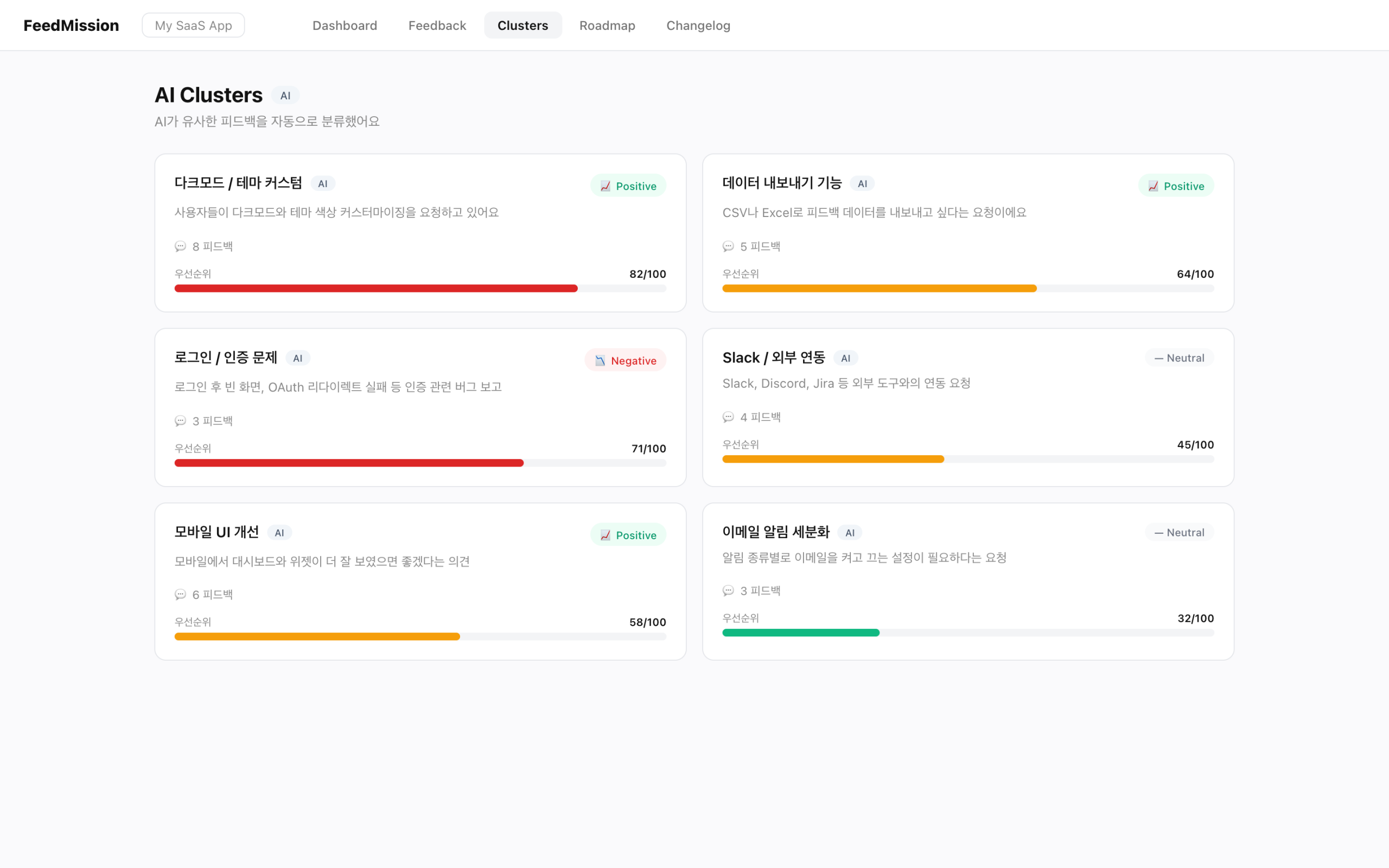
그룹이 10개가 넘으면 순서를 정해야 한다. “많은 사람이 최근에 자주 요청하는 것”이 위로 올라오게 만들었다.
투표 수 50% + 피드백 수 30% + 최신성 20%
// 투표 50개면 만점, 피드백 10개면 만점
// 최근 피드백이 50일 지나면 최신성 0점
투표가 50%로 가장 크다. 피드백 수는 30%. 최신성이 20%. 이 공식으로 0~100 사이 점수가 나온다. 70 이상이면 빨간색, 40 이상이면 노란색, 그 아래는 초록색으로 표시한다.
after() 패턴 — 사용자는 기다리지 않는다
이 파이프라인 전체가 피드백 제출 API 안에서 실행된다. 임베딩 + 감정 분석 + 유사도 검색 + 클러스터 배정 + 우선순위 계산. 다 합치면 1-2초 걸린다. 사용자가 “피드백 보내기” 버튼을 누르고 2초를 기다리면 UX가 나쁘다.
EP.02에서 Vercel Cron 타임아웃을 피할 때 쓴 그 패턴을 여기서도 썼다. after(). 편의점에서 계산은 바로 끝나고, 영수증은 뒤에 나오는 것처럼.
const feedback = await prisma.feedback.create({ … })
const response = NextResponse.json(feedback, { status: 201 })
// ↑ 즉시 “접수 완료” 반환
after(async () => {
await processFeedbackAsync(feedback.id)
// ↑ 임베딩 + 클러스터링은 백그라운드
})
return response
사용자는 “피드백이 접수됐습니다”를 바로 본다. 뒤에서 AI가 조용히 분류를 끝낸다. 대시보드를 새로고침하면 새 피드백이 알맞은 그룹에 들어가 있다.
만들면서 겪은 문제들
만들면서 겪은 문제들을 모아봤다. 다른 사람은 같은 실수 안 했으면 좋겠다.
isFinite()로 검증하지 않으면 DB가 오염된다.recalculatePriority()를 호출하고 새로 만들 때는 빠뜨렸다. 새 그룹이 항상 우선순위 0이어서 정렬이 무의미했다.```json```으로 감싼다. 정규식 제거 + try-catch + fallback이 필수다.188줄로 피드백 분류를 자동화했다
clustering.ts 188줄에 전체 파이프라인이 들어있다. 외부 API 2개(Voyage + Claude), DB 쿼리 5~7개, 분기 1개. 한 파일에 담겨 있어서 흐름을 따라가기 쉽다.
이제 피드백이 들어오면 수동으로 읽고 묶을 필요가 없다. AI가 분류하고 이름 붙이고 우선순위까지 매겨준다. 대시보드를 열면 “지금 사용자들이 가장 원하는 것”이 점수 순으로 보인다.
EP.02에서 수익 데이터 확인을, EP.03에서 분석 판단을, EP.04에서 SaaS 전체를 만들었다. 이번에는 피드백 분류를 자동화했다. 다음엔 보안 취약점과 이메일 디버깅 이야기를 쓸 예정이다.