Did DeepSeek Copy ChatGPT? — The OpenAI vs DeepSeek IP Dispute Explained
OpenAI accused DeepSeek of traini
April 4, 2026 · AI News
In January 2025, DeepSeek R1 dropped and the AI industry took notice. The performance was solid, and the development cost was suspiciously low. Then a different kind of question surfaced: “Did they train on ChatGPT outputs?”
OpenAI and Microsoft were the first to raise the alarm. Their claim: DeepSeek used ChatGPT’s outputs as training data through systematic scraping. By February 2026, OpenAI had submitted a formal memo to the US Congress China Select Committee. This was no longer a corporate spat. It had become a political issue.
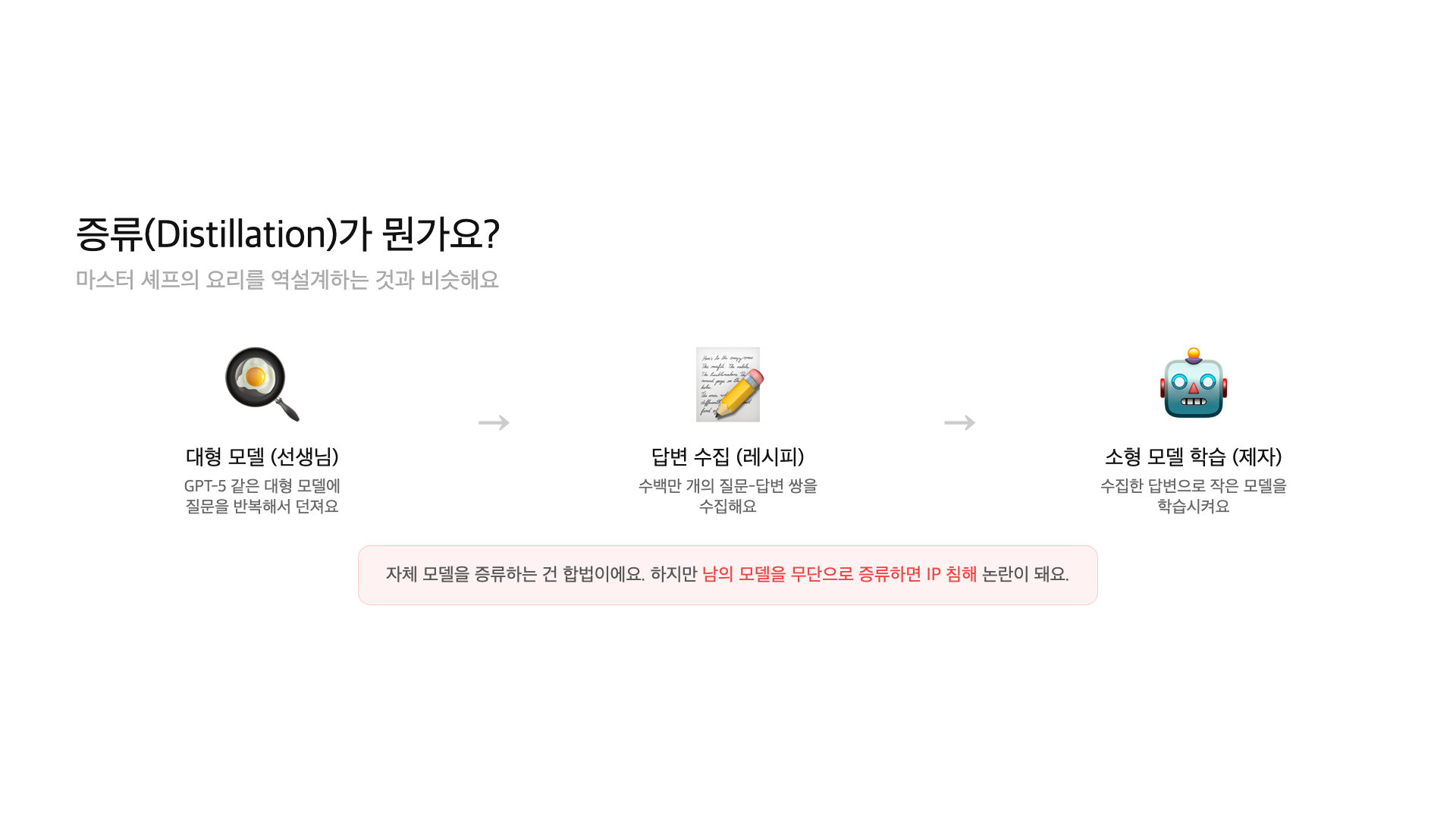
The technical mechanism at the center of this controversy is called “distillation.” Here’s a simple analogy: imagine ordering from a famous restaurant every day, meticulously analyzing every dish, then reverse-engineering the recipes for your own menu. You never stole the recipe book, but you systematically replicated the results.
– Jan 2025: DeepSeek R1 launched; OpenAI and Microsoft alleged ChatGPT output training
– Feb 12, 2026: OpenAI submitted formal memo to US Congress China Select Committee
– Feb 24, 2026: Anthropic also accused DeepSeek, Moonshot AI, and MiniMax of coordinated distillation
– Core technique “distillation”: training smaller models on outputs from larger models

What is distillation, and why is it controversial?
Distillation is a technique where a large AI model’s outputs are used as training data for a smaller model. The large model is the “teacher,” and the small model is the “student.” Feed millions of prompts to the teacher, collect its responses, and train the student on that data. The student learns to mimic the teacher’s behavior at a fraction of the cost.
Here’s the restaurant analogy in full. A master chef spends years perfecting recipes. You order from the restaurant hundreds of times, photograph every dish, analyze the ingredients, and reverse-engineer the cooking process. You never stole the recipe book. But you systematically replicated the output. Is that theft? It depends on who you ask.
Distillation itself is a standard technique. OpenAI distills GPT-4 into GPT-4o mini. Google distills Gemini into Gemma. Meta does the same with Llama. The issue is doing it to someone else’s model without permission. That’s where the legal line gets blurry.
What happened with DeepSeek R1?
In January 2025, Chinese AI startup DeepSeek released R1, an open-source model under the MIT license. It approached GPT-4-level reasoning performance at a dramatically lower development cost. The AI industry immediately asked: how?
OpenAI and Microsoft launched internal investigations. According to their claims, DeepSeek employees developed code specifically designed to circumvent ChatGPT’s access restrictions. They allegedly used obfuscated third-party routers to scrape model outputs at scale. Those outputs were then used as training data for distillation.
DeepSeek denied all allegations, maintaining that R1 was trained using independent data and methodology. Neither side’s claims have been independently verified.
OpenAI’s congressional memo
On February 12, 2026, OpenAI submitted a formal memo to the US Congress China Select Committee. The framing was deliberate: this wasn’t just a corporate dispute. It was a national security matter.
The memo made three core claims. First, DeepSeek employees built custom code to bypass API access restrictions. Second, they routed requests through obfuscated third-party proxies for mass scraping. Third, they used the collected outputs as distillation training data.
AI technology leakage isn’t just a copyright issue from the US government’s perspective. It’s a national security concern involving billions of dollars in R&D. A bipartisan bill to ban Chinese AI systems from federal agencies was already introduced in June 2025.
The timing matters. DeepSeek R1 launched over a year before the memo. Why wait? Some analysts suggest OpenAI strategically timed the escalation as US-China AI competition intensified, turning a technical complaint into a political weapon.
Anthropic joins in — the problem gets bigger
On February 24, 2026, Anthropic (the company behind Claude) issued its own statement. It accused not just DeepSeek but also Moonshot AI and MiniMax of running coordinated distillation campaigns against its models.
Anthropic’s involvement changed the calculus. If only OpenAI made the claim, it could be dismissed as a competitive grievance. When two rival American AI companies report the same pattern, it suggests a structural problem rather than an isolated incident.
Moonshot AI is known for its Kimi chatbot. MiniMax is behind Hailuo AI. All three accused companies are based in China. The US side views this not as individual corporate misconduct but as a systematic pattern.
Whether distillation can actually be detected is also a key question. Research is underway on embedding watermarks in model outputs or inserting identifiable patterns for specific prompts. OpenAI has said it’s developing such detection capabilities. Whether watermarks survive the distillation process, however, remains unproven.
Where does the law stand?
Honestly, nothing is settled. There’s no legal precedent specifically addressing whether distilling a competitor’s AI model constitutes intellectual property theft. Existing copyright law and trade secret protections don’t map cleanly onto this situation.
Here’s what we know. API terms-of-service violations are relatively clear-cut. Both ChatGPT and Claude API terms explicitly prohibit using outputs to train competing models. But TOS violations are contract breaches, not criminal offenses. International enforcement adds another layer of complexity.
Output Restrictions:
“Using API outputs to develop or train competing models is prohibited”
“Automated collection that circumvents access restrictions is prohibited”
“Violations subject to service termination and legal action”
// Note: This is a contract breach, not a criminal offense
// International enforcement is a separate challenge
The bipartisan bill introduced in June 2025 is also worth watching. It would ban Chinese AI systems from US federal agencies. It doesn’t directly address distillation, but it signals that the US government’s wariness toward Chinese AI technology is being codified into law.
The AI industry already uses distillation
This is the crux of the issue. Distillation is a standard, widely-used technique in the AI industry. There’s nothing new or unusual about it.
OpenAI distills GPT-4 knowledge into GPT-4o mini. Google transfers capabilities from Gemini to Gemma. Meta does the same across the Llama family. Distilling your own models is perfectly fine. No one disputes that.
The line gets blurry when it comes to “collecting outputs from a competitor’s model and using them for training.” Using an API normally and referencing the results is legal. But bypassing access restrictions, systematically mass-collecting outputs, and feeding them into training pipelines is different. Where “fair use” ends and “exploitation” begins — there’s no industry consensus or legal standard for that yet.
Back to the restaurant analogy. Eating at a restaurant and thinking “this is great, I should try making something similar” is perfectly fine. But ordering 100 meals a day, sending them to a food lab for ingredient analysis, and opening a franchise based on the results? The restaurant owner would see that very differently. The AI distillation debate sits at exactly this point.
What this means for regular users
In the short term, not much changes. Whether you use ChatGPT or DeepSeek, the services themselves aren’t affected. But longer-term shifts are possible.
First, API terms of service will likely get stricter. OpenAI has already strengthened monitoring for suspicious high-volume requests. Rate limits may tighten for regular developers too.
Second, geographic restrictions could expand. The US government is moving toward limiting Chinese AI services domestically. The federal agency ban bill was just the start. It could extend to the private sector.
Third, the open-source AI ecosystem may be impacted. As distillation concerns grow, more models will ship with licenses that explicitly prohibit “training competing models on outputs.” Some already do.

Fourth, pressure for AI training transparency will increase. There’s growing demand for companies to disclose what data their models were trained on. The EU AI Act already requires training data documentation for high-risk AI systems. The distillation controversy adds momentum to these regulatory efforts.
FAQ
Q. What exactly is distillation in AI?
It’s a technique where outputs from a large AI model are used as training data for a smaller model. Think of it like reverse-engineering a master chef’s recipes by repeatedly ordering dishes and analyzing every component.
Q. Did DeepSeek actually copy ChatGPT?
Nothing is confirmed. OpenAI submitted allegations to the US Congress, and DeepSeek denies wrongdoing. The evidence has not been independently verified.
Q. Is distillation illegal?
It’s a legal gray area. Distilling your own models is standard practice. Whether doing it to a competitor’s model without permission is illegal has no legal precedent. It may violate API terms of service, but that’s a contract breach, not a crime.
Q. Why did Anthropic get involved?
Anthropic accused DeepSeek, Moonshot AI, and MiniMax of coordinated distillation campaigns. By adding its voice, it demonstrated this was an industry-wide issue, not just an OpenAI complaint.
Q. How does this affect regular AI users?
Short-term impact is minimal. Long-term, expect stricter API terms, potential restrictions on Chinese AI services in the US, and tighter conditions in open-source licenses.
Final thoughts
The DeepSeek vs OpenAI distillation controversy isn’t just a corporate dispute. It’s a collision of questions: Do AI model outputs constitute intellectual property? Where is the legal boundary for distillation? How should technology protection work in the US-China AI race? All of these erupted at once.
One thing is clear: this won’t resolve quickly. There are no legal precedents, no industry standards, and certainly no international agreements. As AI advances at breakneck speed, the rules need to keep pace.
Published April 4, 2026. Based on OpenAI’s congressional memo (Feb 12, 2026), Anthropic’s statement (Feb 24, 2026), and official announcements from each company. No legal rulings have been made, and neither side’s claims have been independently verified.
GoCodeLab covers AI news with firsthand research. Subscribe for more updates.