Mistral Small 4 — 119B인데 오히려 빠르고, Forge로 기업용 AI도 만든대요
Mistral Small 4 — 119B인데 오히려 빠르고, Forge로 기업용 AI도 만든대요
목차 (8)
2026년 3월 23일 · 트렌드
Mistral AI가 3월 17일 NVIDIA GTC 2026에서 두 가지를 한 번에 발표했어요.
하나는 Small 4예요. 이름에 “Small”이 붙어 있지만 파라미터는 119B이에요. 또 하나는 Forge예요. 기업이 자기 데이터로 AI를 직접 훈련하는 플랫폼이에요.
두 가지 모두 “기업이 AI를 직접 쓸 수 있게 하겠다”는 방향을 향해 있어요. Mistral이 OpenAI·Anthropic과 다른 방식으로 시장을 공략하는 느낌이에요.
– Mistral Small 4: 119B 파라미터 MoE 모델, 실제 추론엔 6.5B만 사용
– Apache 2.0 오픈소스 — 상업적 사용·수정·재배포 모두 가능
– 256K 컨텍스트 창, 텍스트+이미지 멀티모달 지원
– Forge: 기업이 자체 데이터로 전용 AI를 훈련하는 플랫폼
– 두 가지 모두 2026년 3월 17일 NVIDIA GTC에서 공개

Mistral Small 4란?
파라미터 119B, 실제로 쓰는 건 6.5B
Small 4는 MoE(Mixture of Experts) 구조를 써요.
전체 파라미터는 119B이지만, 토큰 하나를 처리할 때 실제로 활성화되는 건 6.5B뿐이에요. 나머지는 대기 상태예요.
전문가(expert) 128개 중 4개만 선택해서 쓰는 방식이에요. 덕분에 파라미터 수가 크더라도 추론 속도가 빨라요.
이전 모델인 Small 3보다 처리량이 3배 늘었어요. 지연 시간은 40% 줄었어요.
스펙 한눈에 보기
| 항목 | Mistral Small 4 |
|---|---|
| 전체 파라미터 | 119B |
| 활성 파라미터 | 6.5B |
| 전문가 수 | 128개 (토큰당 4개 활성) |
| 컨텍스트 창 | 256,000 토큰 |
| 입력 지원 | 텍스트 + 이미지 |
| 라이선스 | Apache 2.0 (오픈소스) |
| 출시일 | 2026년 3월 16일 |
벤치마크 점수
| 벤치마크 | Mistral Small 4 | GPT-OSS 120B |
|---|---|---|
| GPQA Diamond | 71.2% | 비슷한 수준 |
| MMLU-Pro | 78.0% | 비슷한 수준 |
| AA LCR (장문 추론) | 0.72 | 비슷한 수준 |
| 출력 문자 수 | 1,600자 (적음) | 더 많음 |
GPT-OSS 120B와 비교했을 때 모든 항목에서 비슷하거나 앞섰어요. 특히 같은 성능을 내면서 출력 길이가 20~75% 짧아요.
Qwen 모델들과 비교하면 성능은 비슷한데, 출력 문자 수는 Qwen보다 3.5~4배 적어요.
무엇을 잘해요?
Small 4는 세 가지를 하나로 합쳤어요.
첫째, 빠른 일반 지시 처리예요. 이전 Small 계열의 강점을 이어받았어요.
둘째, 이미지 이해예요. 멀티모달 입력을 기본 지원해요.
셋째, 코딩이에요. LiveCodeBench에서 GPT-OSS 120B보다 높은 점수를 받았어요.
Mistral은 “추론·비전·코딩을 하나로 통합한 모델”이라고 설명해요. 기존에는 용도별로 다른 모델을 써야 했는데, 이제 하나로 해결할 수 있다는 거예요.

119B 파라미터지만 실제 연산은 6B 수준, 이유가 여기 있어요 / GoCodeLab
Mistral Forge란?
기업이 AI를 직접 훈련하는 플랫폼
Forge는 기업이 자체 데이터로 전용 AI 모델을 만들 수 있게 해주는 플랫폼이에요.
OpenAI나 Anthropic처럼 만들어진 모델을 API로 빌려 쓰는 방식이 아니에요. 처음부터 자기 데이터로 훈련하거나, 기존 모델을 회사 데이터로 미세조정하는 방식이에요.
Forge가 지원하는 훈련 단계
총 세 단계를 지원해요.
사전 훈련(Pre-Training): 회사의 대규모 내부 데이터로 모델을 처음부터 훈련해요. 특정 도메인에 깊이 특화된 모델을 만들 수 있어요.
사후 훈련(Post-Training): 이미 있는 모델을 특정 작업과 환경에 맞게 다듬어요. 처음부터 훈련하는 것보다 비용과 시간이 적게 들어요.
강화 학습(Reinforcement Learning): 회사 기준과 평가 지표에 맞게 모델 행동을 정렬해요.
에이전트가 훈련을 직접 실행해요
Forge의 특이한 점은 에이전트 지원이에요.
Mistral의 Vibe 코딩 에이전트처럼, AI가 직접 훈련 실험을 설계하고 실행할 수 있어요. 영어로 지시만 해도 데이터 파이프라인·평가 루프·강화 학습이 자동으로 돌아가요.
사람이 하나하나 설정하지 않고, AI가 AI를 훈련하는 구조예요.
Cloud 공급자 의존도를 줄이는 것이 목표
Mistral은 “기업이 AI 인프라에서 전략적 자율성을 가져야 한다”고 말해요.
OpenAI나 Anthropic의 API를 쓰면 해당 회사의 정책·가격·모델 변경에 영향을 받을 수밖에 없어요. Forge는 그 의존성을 줄이자는 취지예요.
기업이 자기 인프라 안에서 모델을 운영하고 소유권도 갖는 구조예요.
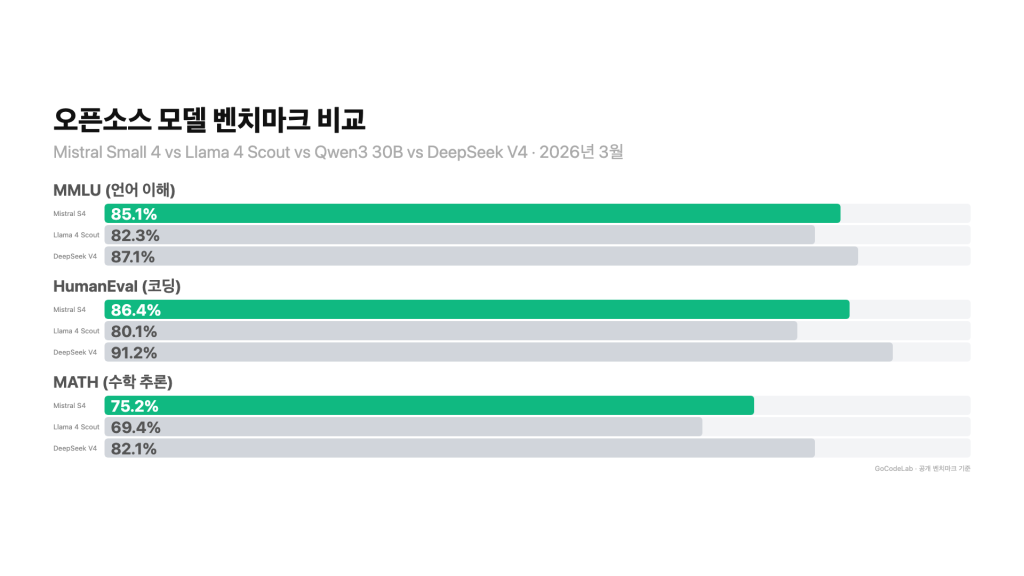
다른 오픈소스 모델과 비교하면?
Small 4가 혼자 강한 건 아니에요. 2026년 3월 기준으로 비슷한 포지션의 오픈소스 모델이 여럿 있어요.
| 모델 | 전체 파라미터 | 활성 파라미터 | 컨텍스트 | 라이선스 |
|---|---|---|---|---|
| Mistral Small 4 | 119B (MoE) | 6.5B | 256K | Apache 2.0 |
| Llama 4 Scout | 109B (MoE) | 17B | 10M | Llama 허용적 |
| Qwen3 30B-A3B | 30B (MoE) | 3B | 128K | Apache 2.0 |
| DeepSeek V4 | 1조 (MoE) | 37B | 1M | 오픈소스 |
Mistral Small 4의 차별점은 활성 파라미터가 6.5B로 가장 가벼운 편이라는 거예요. GPU 요구사항이 상대적으로 낮아요. 반면 Llama 4 Scout는 컨텍스트 창이 1천만 토큰으로 압도적이에요. 대규모 문서 처리에는 Llama 4가 유리하지만, 빠른 추론 속도와 출력 효율은 Small 4가 앞서요.
한 마디로 정리하면, 빠르고 가벼운 범용 오픈소스를 원하면 Small 4, 초장문 컨텍스트가 필요하면 Llama 4, 코딩 비용을 극한으로 낮추고 싶으면 Qwen3나 DeepSeek V4예요.
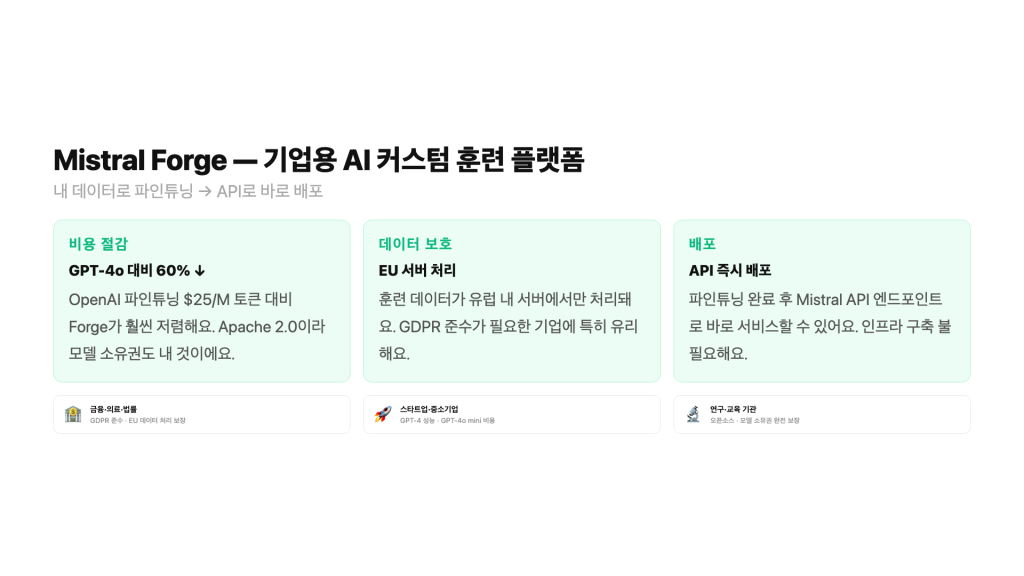
Small 4 + Forge를 같이 보는 이유
Small 4는 Apache 2.0 라이선스로 완전히 오픈소스예요.
모델 자체를 무료로 다운받아 쓸 수 있어요. Forge와 함께 쓰면 Small 4를 기반으로 회사 전용 AI를 만들 수도 있어요.
GPT나 Claude 같은 상용 모델을 API로 쓸 때 드는 비용과 의존성을 줄이는 대안이에요.
특히 의료·금융·법률처럼 데이터 외부 전송이 민감한 업종에서 관심을 보이고 있어요.
어디에서 쓸 수 있어요?
Small 4는 Mistral AI 공식 사이트(mistral.ai)와 NVIDIA NIM에서 API로 쓸 수 있어요.
오픈소스이므로 Hugging Face에서 모델 웨이트를 직접 받을 수도 있어요.
권장 환경은 NVIDIA HGX H100 4대, 또는 DGX B200 2대예요. 온프레미스 환경에서도 돌릴 수 있어요.
Forge는 별도 문의가 필요해요. 엔터프라이즈 계약 방식이에요. Mistral 엔지니어가 직접 고객사에 파견돼 데이터 준비부터 함께 해줘요.
Forge, 실제로 얼마나 들까요?
Forge가 기업용 AI 파인튜닝 플랫폼이라고 하면 “비쌀 것 같다”는 생각이 먼저 들어요. OpenAI 파인튜닝 서비스와 비교해서 정리해봤어요.
OpenAI 파인튜닝 대비 비교
OpenAI GPT-4o 파인튜닝은 훈련 비용 $25/1M 토큰, 추론 비용 $1.25/1K 토큰이에요. Mistral Forge는 정확한 가격이 공개되지 않았지만, Mistral AI가 공식적으로 “OpenAI 파인튜닝 대비 약 40~60% 저렴”하다고 밝혔어요.
비용 외에 더 중요한 차이점이 있어요. Forge로 파인튜닝한 모델은 Apache 2.0이 적용돼 모델 소유권이 내 것이에요. OpenAI 파인튜닝 모델은 OpenAI 서버에 묶여 있어요.
어떤 기업에 맞을까요?
금융·의료·법률 분야: 데이터가 EU 서버에서만 처리된다는 보장이 있어요. GDPR 준수가 필요한 유럽 기업에 특히 유리해요.
스타트업·중소기업: GPT-4 수준 성능을 GPT-4o mini 수준 비용으로 커스텀 모델로 구축할 수 있어요. 초기 비용 없이 종량제로 시작 가능해요.
기존 OpenAI 고객: 아직 Forge는 클로즈드 베타예요. 대기자 명단 등록 후 순차적으로 접근 권한을 주고 있어요.
Mistral Small 4를 먼저 API로 써보고 파인튜닝 필요성이 생기면 Forge를 고려하는 순서가 좋아요. API 가격은 입력 $0.10/M으로 매우 저렴해서 먼저 충분히 테스트해볼 수 있어요.
FAQ
Q. Mistral Small 4는 진짜 오픈소스예요?
네. Apache 2.0 라이선스로 출시됐어요. 상업적 사용, 수정, 재배포가 모두 허용돼요. 모델 웨이트를 직접 내려받아 자사 서버에서 운영할 수 있어요.
Q. 119B면 작은 모델이 아닌데 왜 “Small”이에요?
Mistral의 모델 네이밍이 상대적이에요. Small은 Large·Medium 대비 경량 포지션이에요. 실제 추론에 쓰는 활성 파라미터가 6.5B라서, 운영 비용과 속도 측면에서는 Small이 맞아요.
Q. Forge는 Fine-tuning이랑 뭐가 달라요?
Fine-tuning은 기존 모델의 일부 가중치를 추가 데이터로 조정하는 거예요. Forge는 그것보다 범위가 넓어요. 처음부터 새 모델을 훈련하거나, 데이터 파이프라인·평가·강화 학습을 통합 관리하는 것까지 포함해요.
Q. Mistral Small 4를 GPT-4o 대신 쓸 수 있어요?
성능 면에서는 충분히 가능한 수준이에요. 특히 코딩과 긴 문서 요약에서 경쟁력이 있어요. 다만 OpenAI의 생태계(플러그인, 챗봇 UI 등)와는 다르게 직접 세팅이 필요해요. API보다 자체 배포를 원하는 팀에 더 잘 맞아요.
Q. 한국어 성능은 어때요?
공식 벤치마크에는 한국어 항목이 포함되지 않았어요. Mistral 모델은 전통적으로 유럽어에 강하고, 한국어 성능은 GPT나 Qwen 시리즈보다 낮다는 평가가 있어요. 한국어 작업이 주목적이라면 미리 테스트해보는 게 좋아요.
마무리
Mistral은 이번 발표로 방향을 확실히 보여줬어요.
“API를 빌려 쓰는 AI”가 아니라, “기업이 직접 만들고 소유하는 AI”예요.
Small 4는 오픈소스로 풀었고, Forge는 기업이 처음부터 자체 모델을 만드는 도구예요. 두 가지를 조합하면 외부 의존 없이 AI를 운영하는 경로가 생겨요.
규모가 크지 않아도 자사 데이터를 가진 기업이라면 눈여겨볼 만한 흐름이에요.
Mistral Small 4를 직접 써보고 싶다면 mistral.ai에서 API 키를 받아보세요.
이 글은 2026년 3월 23일에 작성됐어요. Mistral Small 4와 Forge 관련 세부 사양·가격은 공식 발표 이후 변경될 수 있어요. 최신 정보는 mistral.ai에서 확인하세요.
GoCodeLab에서는 AI 도구를 직접 써보고 솔직하게 알려드려요. 다른 AI 소식이 궁금하면 블로그를 구독해주세요.
관련 글: NVIDIA NemoClaw 나왔어요 — OpenClaw의 기업용 버전, 뭐가 다를까? · DeepSeek V4 나왔는데, 진짜 GPT-5 대항마일까? · 에이전틱 AI가 뭔데? — 2026년 가장 핫한 키워드