Gemma 4를 내 Mac에서 돌려봤어요 — Ollama로 로컬 AI 시작하기
Gemma 4를 내 Mac에서 돌려봤어요 — Ollama로 로컬 AI 시작하기
2026년 4월 4일 · 튜토리얼
AI 모델을 쓰려면 ChatGPT나 Claude 같은 서비스에 매달 구독료를 내야 한다고 생각하기 쉬워요. 그런데 요즘은 내 Mac에서 무료로 AI 모델을 돌릴 수 있어요. Gemma 4가 대표적이에요. Google이 Apache 2.0 라이선스로 공개한 오픈소스 모델이에요.
Ollama라는 도구를 쓰면 터미널에서 한 줄 명령어로 바로 실행할 수 있어요. 설치 5분, 실행 1분이면 내 Mac에서 AI와 대화할 수 있어요. 데이터가 외부로 나가지 않으니 개인정보 보호도 돼요.
이 글에서는 Ollama 설치부터 Gemma 4 모델 선택, Mac 사양별 권장 모델, 그리고 실제 사용 팁까지 정리해요.
– Ollama v0.20.2 필요 (Gemma 4는 v0.20.0부터 지원)
– 명령어: ollama run gemma4 (기본 E4B, 9.6GB)
– 8GB Mac: E2B만 가능 / 16GB Mac: E4B / 18GB+: 26B MoE / 64GB+: 31B
– Apple Silicon MLX 가속 자동 적용 (Ollama v0.19.0부터)

왜 로컬에서 AI를 돌리나요?
세 가지 이유가 있어요. 첫째, 비용이에요. ChatGPT Plus가 월 $20, Claude Pro가 월 $20이에요. 로컬 실행은 0원이에요. 전기세만 나와요.
둘째, 개인정보 보호예요. 로컬에서 돌리면 대화 내용이 외부 서버로 전송되지 않아요. 의료, 법률, 기업 내부 문서 같은 민감한 데이터를 다룰 때 중요한 장점이에요.
셋째, 인터넷 연결이 필요 없어요. 모델을 한 번 다운로드하면 오프라인에서도 돌아가요. 비행기 안에서도, 카페 Wi-Fi가 불안정해도 문제없어요.
Ollama 설치하기
Ollama는 Mac, Windows, Linux를 모두 지원해요. Mac에서는 두 가지 방법으로 설치할 수 있어요.
curl -fsSL https://ollama.com/install.sh | sh
# 방법 2: DMG 다운로드
# ollama.com에서 DMG 파일을 받아서 설치
# 설치 확인
ollama –version
# ollama version 0.20.2 (이상이면 OK)
macOS 14 이상이 필요해요. Apple Silicon(M1, M2, M3, M4) Mac이면 MLX 가속이 자동으로 적용돼요. Ollama v0.19.0부터 MLX를 자동 감지해서 켜줘요. 별도 설정이 필요 없어요.
Intel Mac에서도 돌아가지만, 속도가 많이 느려요. 실용적으로 쓰려면 Apple Silicon Mac을 추천해요.
Gemma 4 모델 선택 가이드
Gemma 4는 4개 모델이 있고, Ollama에서 전부 지원해요. 어떤 걸 골라야 할지 정리해볼게요.
ollama run gemma4 # E4B (기본) — 9.6GB
ollama run gemma4:e2b # E2B — 7.2GB (가장 가벼움)
ollama run gemma4:26b # 26B MoE — 18GB
ollama run gemma4:31b # 31B Dense — 20GB
gemma4 (=E4B)가 기본이에요. 대부분의 용도에 가장 적합해요. 일반 대화, 코드 작성, 번역, 요약 같은 일에 무난하게 쓸 수 있어요.
gemma4:e2b는 가장 가벼운 모델이에요. 8GB Mac에서도 돌아가요. 성능은 E4B보다 낮지만, 간단한 질문이나 가벼운 작업에는 충분해요.
gemma4:26b는 MoE(Mixture of Experts) 구조예요. 전체 파라미터는 26B인데, 매번 3.8B만 활성화돼서 크기 대비 빨라요. 18GB 이상 Mac이 있다면 가성비 최고예요.
gemma4:31b는 가장 큰 모델이에요. 벤치마크 성능이 가장 높지만, 64GB 이상 Mac이 필요해요. M4 Max나 M2 Ultra 급이 아니면 느려요.
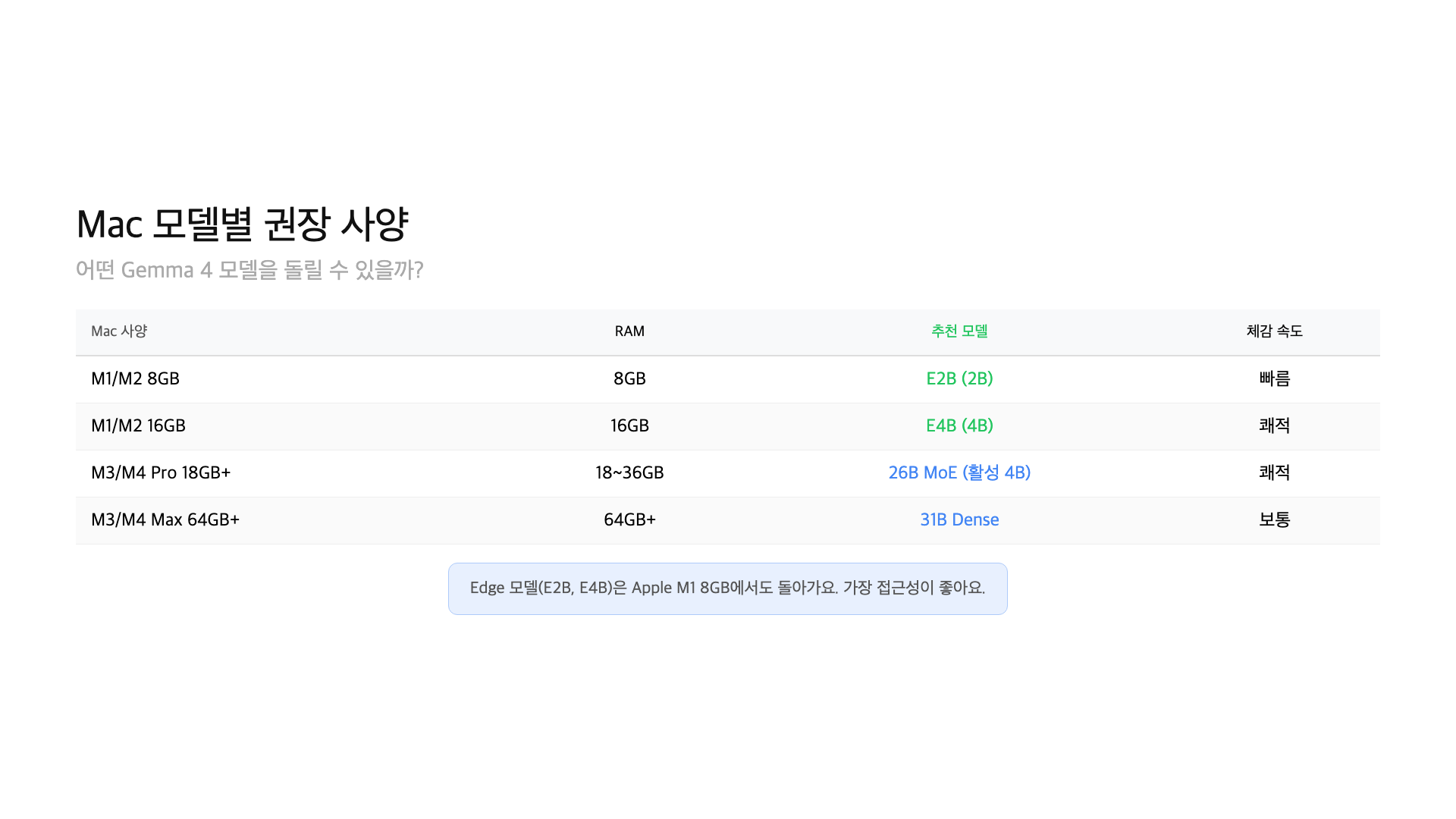
Mac 사양별 권장 모델
| Mac 사양 | RAM | 권장 모델 | 다운로드 크기 | 체감 속도 |
|---|---|---|---|---|
| M1 MacBook Air | 8GB | gemma4:e2b | 7.2GB | 보통 |
| M1/M2 MacBook Pro | 16GB | gemma4 (E4B) | 9.6GB | 쾌적 |
| M3 Pro MacBook Pro | 18GB+ | gemma4:26b | 18GB | 쾌적 |
| M4 Max / M2 Ultra | 64GB+ | gemma4:31b | 20GB | 쾌적 |
gemma4 (E4B)를 추천해요. 9.6GB라서 여유 있게 돌아가고, 성능도 대부분의 용도에 충분해요. 26B를 돌릴 수도 있지만 다른 앱을 함께 쓰면 느려질 수 있어요.
첫 번째 대화 시작하기
설치가 끝났으면 바로 시작해봐요. 터미널을 열고 아래 명령어를 입력하면 돼요.
ollama run gemma4
# 다운로드 완료 후 바로 대화 가능
>>> 한국어로 인사해줘
안녕하세요! 무엇을 도와드릴까요?
# 대화 종료: /bye 입력
>>> /bye
첫 실행 시 모델을 다운로드해요. E4B 기준 9.6GB라서 네트워크 속도에 따라 몇 분 걸려요. 한 번 다운로드하면 다음부터는 바로 실행돼요.
응답 속도는 Mac 사양에 따라 달라요. M1 16GB에서 E4B를 돌리면 초당 약 15~20토큰 정도 나와요. 체감상 ChatGPT보다 약간 느리지만, 충분히 쓸 만한 속도예요.
Thinking 모드와 고급 기능
Gemma 4는 Thinking 모드를 지원해요. 복잡한 문제를 풀 때 모델이 먼저 “생각”하고 답하는 방식이에요. 수학 문제나 코딩 같은 추론이 필요한 작업에서 정확도가 올라가요.
enable_thinking = True
# 모델이 <think> 토큰 안에서 추론 후 답변
# 일반 대화에서는 굳이 켤 필요 없어요
Ollama는 API 서버 모드도 지원해요. ollama serve를 실행하면 localhost:11434에서 REST API를 제공해요. 자기 앱에 로컬 AI를 연동하고 싶을 때 유용해요.
파인튜닝은 Ollama 자체에서는 지원하지 않아요. LoRA 기반 파인튜닝을 하려면 Unsloth나 Axolotl 같은 별도 프레임워크를 써야 해요. 파인튜닝된 모델을 GGUF 형식으로 변환하면 Ollama에서 불러올 수 있어요.
다른 도구와 비교 — LM Studio, llama.cpp
| 도구 | UI | Gemma 4 지원 | 설치 난이도 | 추천 대상 |
|---|---|---|---|---|
| Ollama | 터미널 | v0.20.0+ | 쉬움 | 개발자, 터미널 익숙한 분 |
| LM Studio | GUI | 미정 | 매우 쉬움 | 비개발자 |
| llama.cpp | 터미널 | 미확인 | 어려움 | 저수준 커스터마이징 |
2026년 4월 기준, Gemma 4를 공식 지원하는 도구는 Ollama v0.20.0+뿐이에요. LM Studio는 GUI 기반이라 비개발자에게 편하지만, Gemma 4 지원 시점은 아직 미정이에요.
llama.cpp는 가장 저수준의 도구예요. 커스터마이징 자유도가 높지만, 설정이 복잡해요. 대부분의 사용자에게는 Ollama가 가장 쉽고 빠른 선택이에요.

FAQ
Q. Ollama가 뭔가요?
로컬에서 AI 모델을 실행하는 오픈소스 도구예요. 터미널에서 한 줄 명령어로 모델을 다운로드하고 대화할 수 있어요. Mac, Windows, Linux를 모두 지원해요.
Q. Gemma 4를 돌리려면 Mac 사양이 어떻게 돼야 하나요?
E2B는 8GB, E4B는 16GB, 26B MoE는 18GB 이상, 31B Dense는 64GB 이상을 추천해요. Apple Silicon(M1 이상)이면 MLX 가속이 자동 적용돼요.
Q. 데이터가 외부로 전송되나요?
아니요. 모든 처리가 내 Mac에서 이뤄져요. 인터넷 연결 없이도 동작하고, 대화 내용이 외부 서버로 전송되지 않아요.
Q. Ollama 말고 다른 방법도 있나요?
LM Studio(GUI 기반)와 llama.cpp(저수준 CLI)가 있어요. 다만 2026년 4월 기준 Gemma 4를 공식 지원하는 건 Ollama v0.20.0+뿐이에요.
Q. 파인튜닝도 Ollama에서 되나요?
Ollama 자체는 파인튜닝을 지원하지 않아요. LoRA 기반 파인튜닝은 Unsloth나 Axolotl 같은 별도 프레임워크를 써야 해요. 파인튜닝된 모델을 GGUF로 변환하면 Ollama에서 실행 가능해요.
마무리
Gemma 4를 Mac에서 돌리는 건 생각보다 쉬워요. Ollama를 설치하고, ollama run gemma4를 입력하면 끝이에요. API 비용 0원, 데이터 유출 걱정 없음, 오프라인에서도 동작해요.
16GB Mac이 있다면 E4B부터 시작해보세요. 대부분의 일반 작업에 충분하고, 부족하다고 느끼면 26B MoE로 올리면 돼요. 오픈소스 AI가 이 정도로 접근 가능해진 시대예요. 내 Mac에서 직접 체험해보세요.
이 글은 2026년 4월 4일에 작성됐어요. Ollama v0.20.2, Gemma 4 (v0.20.0 지원 시작) 기준이에요. 버전이 올라가면 명령어나 지원 범위가 달라질 수 있어요.
GoCodeLab에서는 AI 도구를 직접 써보고 솔직하게 알려드려요. 다른 AI 소식이 궁금하면 블로그를 구독해주세요.