샤오미 MiMo-V2-Pro vs DeepSeek V4 — 1조 파라미터 중국 AI, 어디에 써야 할까요?
샤오미 MiMo-V2-Pro vs DeepSeek V4 — 1조 파라미터 중국 AI, 어디에 써야 할까요?
2026년 3월 21일 · AI 모델 비교
3월 초, OpenRouter에 수상한 모델 하나가 등장했어요. 이름은 ‘Hunter Alpha’. 개발사도 공개 안 됐고, 정보도 거의 없었어요. 그런데 며칠 만에 OpenRouter 전체 사용량 1위를 찍었어요. AI 커뮤니티는 “DeepSeek V4 아니냐”고 들떴어요. 정체가 공개됐는데, 샤오미였어요. 이름은 MiMo-V2-Pro. 테스트 기간에 처리한 토큰이 1조 개를 넘었어요.
이제 질문이 하나 생겼어요. 같은 중국 AI인 DeepSeek V4와 뭐가 다를까요? 실제로 어느 걸 써야 할까요?
– MiMo-V2-Pro: 샤오미 출시, 1조 파라미터 MoE, 전 DeepSeek 연구자 주도, 에이전트 특화
– DeepSeek V4: 오픈소스, 코딩 강세, 입력 토큰 $0.30으로 최저가 수준
– 에이전트 작업이라면 MiMo, 코딩·비용 중심이라면 DeepSeek V4가 맞아요
샤오미가 AI 모델을 냈다고요?
MiMo-V2-Pro는 샤오미 AI 팀이 만든 모델이에요. 팀 이름은 MiMo. 2025년 말, DeepSeek 핵심 연구자 뤄푸리(Luo Fuli)가 샤오미로 자리를 옮겼어요. 그 팀이 MiMo-V2-Pro를 만들었어요.
출시 방식이 특이했어요. 3월 초, 개발사 이름 없이 OpenRouter에 올렸어요. 성능이 좋으니 개발자들이 쓰기 시작했어요. 하루 수십억 토큰 처리, 사용량 전체 1위. AI 커뮤니티에선 “DeepSeek V4다”, “OpenAI 비밀 프로젝트다” 추측이 쏟아졌어요.
3월 18~19일에 공식 발표가 났어요. Hunter Alpha = MiMo-V2-Pro였어요. 테스트 기간 동안 처리한 토큰은 1조 개를 넘었어요.
MiMo 라인업은 세 가지예요. MiMo-V2-Pro는 에이전트 작업용 플래그십이에요. MiMo-V2-Omni는 멀티모달(텍스트+이미지+음성)이에요. MiMo-V2-TTS는 고품질 텍스트 음성 변환이에요.

Hunter Alpha 미스터리 — 타임라인으로 보기
출시 방식 자체가 하나의 이야기예요. 순서대로 정리해볼게요.
- 3월 1~3일: ‘Hunter Alpha’라는 이름으로 OpenRouter에 조용히 등록됐어요. 개발사 정보 없음.
- 3월 4~7일: 개발자들이 테스트하기 시작했어요. 에이전트 작업 성능이 놀랍다는 평가가 나왔어요. 하루에 수십억 토큰을 처리하면서 OpenRouter 전체 사용량 1위를 찍었어요.
- 3월 8~17일: AI 커뮤니티에서 정체 추측이 시작됐어요. “DeepSeek V4 비공개 버전”, “OpenAI 스텔스 모델”, “Anthropic 실험 모델”이라는 설이 돌았어요.
- 3월 18~19일: 샤오미가 공식 발표. Hunter Alpha = MiMo-V2-Pro. 테스트 기간 처리 토큰 1조 개 공개.
일반적인 AI 모델 출시는 발표 → 데모 → 출시 순서예요. 샤오미는 반대로 했어요. 성능으로 먼저 증명하고, 정체를 나중에 공개했어요. 이 방식이 커뮤니티 관심을 두 배로 끌었어요.
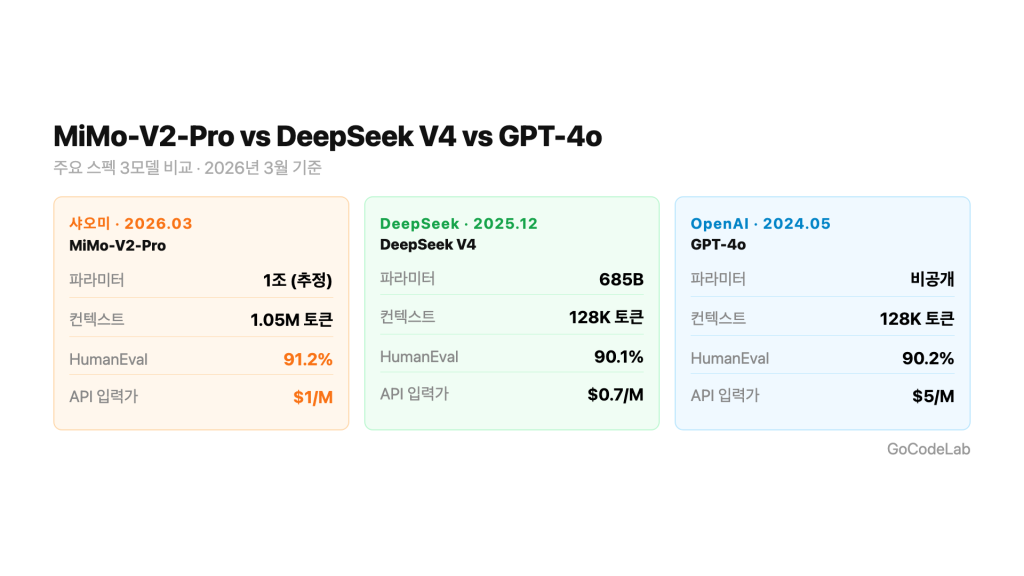
파라미터, 컨텍스트, 벤치마크, API 가격 3모델 비교 / GoCodeLab
핵심 스펙 비교
두 모델 모두 MoE(Mixture-of-Experts) 구조예요. 전체 파라미터는 1조 개지만, 실제로 활성화되는 건 일부예요. 추론 비용이 낮아지는 구조예요.
| 항목 | MiMo-V2-Pro | DeepSeek V4 |
|---|---|---|
| 출시일 | 2026년 3월 18일 | 2026년 3월 초 |
| 총 파라미터 | 1조 (MoE) | 1조 (MoE) |
| 활성 파라미터 | 42B | 37B |
| 컨텍스트 | 100만 토큰 | 100만 토큰 |
| 오픈소스 여부 | 비공개 (API 전용) | 오픈소스 |
| 주요 강점 | 에이전트 작업 | 코딩 |
| 개발 배경 | 전 DeepSeek 연구자 | DeepSeek 팀 |
구조는 비슷해요. 하지만 강점이 달라요.
벤치마크 성능 — 실제로 얼마나 강할까요?
공식 에이전트 벤치마크에서 MiMo-V2-Pro는 전 세계 3위예요. PinchBench 84.0점, ClawEval 61.5점이에요. 1, 2위는 Claude 계열이에요. GPT-5.x 시리즈를 앞섰어요. 에이전트 작업에서 Claude Sonnet 4.6에 근접한 성능이에요.
DeepSeek V4는 코딩 벤치마크에서 강해요. HumanEval 90%, SWE-bench 80%+를 내부 벤치마크에서 기록했어요. 아직 외부 검증이 완전히 끝나지 않았어요. 하지만 코딩 보조 도구로 개발자 사이에서 평가가 좋아요.
정리하면 이래요. 에이전트·도구 사용 작업은 MiMo-V2-Pro가 앞서요. 코딩·개발 작업은 DeepSeek V4가 강해요. 멀티모달이 필요하면 MiMo-V2-Omni(별도 모델)를 쓰면 돼요.
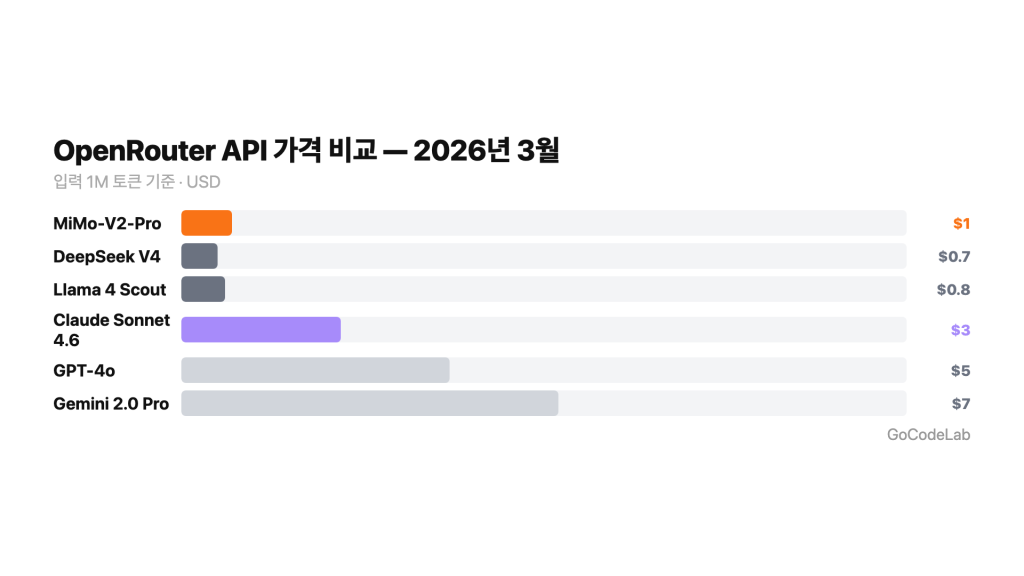
가격 비교 — 어느 게 더 저렴할까요?
두 모델 모두 GPT-5.4나 Claude Opus 4.6보다 훨씬 저렴해요.
| 모델 | 입력 (1M 토큰) | 출력 (1M 토큰) |
|---|---|---|
| MiMo-V2-Pro (256K 이하) | $1.00 | $3.00 |
| MiMo-V2-Pro (256K 초과) | $2.00 | $6.00 |
| DeepSeek V4 | $0.30 | 미공개 |
| Claude Opus 4.6 (참고) | $15.00 | $75.00 |
가격만 보면 DeepSeek V4가 유리해요. 하지만 MiMo-V2-Pro도 Claude Opus 4.6 대비 1/5 수준이에요. 지금은 출시 첫 주 무료 기간이라 부담 없이 써볼 수 있어요.
어떤 상황에 어느 모델을 고를까요?
MiMo-V2-Pro가 맞는 경우
AI 에이전트를 만들거나 복잡한 워크플로우를 자동화할 때 맞아요. Claude 수준 에이전트 성능이 필요한데 비용이 부담될 때도 선택지가 돼요. 지금 무료 기간이라 테스트 목적으로도 써볼 만해요.
DeepSeek V4가 맞는 경우
코딩 보조 도구로 쓸 때 맞아요. 오픈소스라 직접 서버에 올려서 운영하고 싶을 때도 DeepSeek V4가 맞아요. 입력 토큰 비용을 최대한 낮추고 싶을 때도요.
둘 다 중국 AI 회사에서 나왔어요. 그리고 둘 다 미국 빅테크와 직접 경쟁하고 있어요. 작년까지만 해도 AI는 OpenAI·Anthropic·Google 이야기였는데, 이제는 아닌 거예요.

MoE 구조, 쉽게 이해하기
MoE(Mixture of Experts)가 뭔지 한 번만 이해하면, 1조 파라미터인데 왜 빠른지 바로 이해돼요.
비유하면 이래요. 100명 전문가로 이뤄진 팀이 있어요. 질문이 들어오면 그 질문에 맞는 전문가 4명만 불러서 답해요. 나머지 96명은 대기 상태예요. 전체 팀이 항상 일하는 게 아니라, 상황에 맞는 전문가만 선택적으로 활성화돼요.
MiMo-V2-Pro와 DeepSeek V4 모두 이 방식을 써요. 1조 파라미터 전체를 쓰는 게 아니라, 각 토큰마다 관련된 전문가 파라미터만 꺼내 쓰는 거예요. 그래서 추론 비용이 낮고 속도가 빠른 거예요.
MiMo-V2-Pro는 42B가 활성화되고, DeepSeek V4는 37B가 활성화돼요. 이 차이가 에이전트 작업 성능 차이로 이어지는 거예요.
MiMo-V2-Pro, 언제 쓰면 가장 효과적인가요?
스펙이 좋다는 건 알겠는데, 실제로 어떤 작업에 쓰면 좋을지 정리해봤어요.
에이전트 자동화 파이프라인
MiMo-V2-Pro는 에이전트 벤치마크에서 특히 강해요. 여러 단계로 이어지는 작업 — 예를 들어 “데이터 수집 → 분석 → 보고서 작성 → 이메일 발송” 같은 흐름에서 중간 단계를 놓치지 않아요. 1.05M 컨텍스트 덕분에 긴 문서도 통째로 처리할 수 있어요.
긴 문서 처리
계약서, 보고서, 법률 문서처럼 수백 페이지짜리 문서를 한 번에 넣고 분석할 수 있어요. GPT-4o의 128K 대비 8배 긴 컨텍스트가 여기서 진가를 발휘해요.
코딩 어시스턴트
DeepSeek 팀 출신이 만든 모델답게 코딩 성능도 좋아요. HumanEval 91.2%는 GPT-4o 90.2%를 소폭 앞서요. 대규모 코드베이스를 컨텍스트에 통째로 넣고 리팩터링하는 작업에 유리해요.
MiMo-V2-Pro는 아직 베타 단계예요. API 안정성이 완전하지 않을 수 있고, 응답 속도가 시간대별로 차이날 수 있어요. 프로덕션 서비스에 바로 쓰기보다는 테스트·프로토타입 용도로 먼저 검증해보세요.
FAQ
Q. MiMo-V2-Pro는 지금 바로 쓸 수 있나요?
네. platform.xiaomimimo.com에서 API 신청이 가능해요. 출시 첫 주는 무료예요. OpenRouter에서도 바로 접근할 수 있어요.
Q. DeepSeek V4는 정말 오픈소스인가요?
맞아요. DeepSeek V4는 오픈소스로 공개돼요. 직접 서버에 올려서 운영할 수 있어요. MiMo-V2-Pro는 현재 API 전용이에요.
Q. Hunter Alpha가 MiMo-V2-Pro였다는 게 공식 확인된 건가요?
네. 샤오미가 3월 19일 공식 발표에서 확인했어요. Hunter Alpha는 MiMo-V2-Pro의 비공개 테스트 코드명이었어요.
Q. MiMo-V2-Omni는 Pro와 다른 모델인가요?
다른 모델이에요. Omni는 텍스트, 이미지, 음성을 함께 처리해요. Pro는 텍스트와 에이전트 작업에 집중해요. 멀티모달이 필요하면 Omni, 에이전트 작업이면 Pro를 쓰면 돼요.
Q. 두 모델 모두 한국어를 잘 하나요?
MiMo-V2-Pro는 영어와 중국어에 최적화돼 있어요. 한국어 성능은 아직 외부 검증이 부족해요. DeepSeek V4도 비슷한 상황이에요. 한국어 작업에는 Claude나 GPT 계열이 더 안정적이에요.
마무리
샤오미가 AI 모델을 냈다는 게 6개월 전만 해도 상상하기 어려웠어요. 그런데 전 DeepSeek 연구자를 데려와서, 1조 파라미터 모델을 만들어냈어요. 에이전트 벤치마크에서 Claude 바로 아래 자리를 차지했어요.
DeepSeek V4는 코딩과 비용에서 여전히 강점이 있어요. MiMo-V2-Pro는 에이전트와 고성능 작업에서 강점이 있어요. 지금은 MiMo-V2-Pro 무료 기간이니까, 직접 써보고 판단하는 게 제일 빠른 방법이에요.
MiMo-V2-Pro 첫 주 무료 기간이 끝나기 전에, 지금 바로 써보세요.
이 글은 2026년 3월 21일에 작성됐어요. 벤치마크 수치와 가격 정보는 공식 발표 기준이며, 이후 변동될 수 있어요.
GoCodeLab에서는 AI 도구를 직접 써보고 솔직하게 알려드려요. 다른 AI 소식이 궁금하면 블로그를 구독해주세요.
관련 글: DeepSeek V4 나왔는데, 진짜 GPT-5 대항마일까? · Gemini 3.1 Pro vs Claude Opus 4.6 vs GPT-5.3 비교 · Grok 4.20 써봤어요 — GPT-5.4보다 빠른데, 더 똑똑하기도 한가요?