Xiaomi MiMo-V2-Pro vs DeepSeek V4 — Trillion-Parameter Chinese AI, Where Should You Use Them?
Xiaomi secretly uploaded a mystery model called 'Hunter Alpha' to OpenRouter. It hit #1 usage in days, then was revealed to be MiMo-V2-Pro. We compare these two trillion-parameter Chinese AI models head-to-head.
March 21, 2026 · AI Model Comparison
In early March, a suspicious model appeared on OpenRouter. Its name was ‘Hunter Alpha.’ No developer was disclosed, and there was almost no information. Yet within days, it hit #1 usage across all of OpenRouter. The AI community buzzed: “Is this DeepSeek V4?” When the identity was revealed, it was Xiaomi. The name: MiMo-V2-Pro. It processed over 1 trillion tokens during the test period.
Now one question emerges. How does it differ from fellow Chinese AI, DeepSeek V4? Which one should you actually use?
– MiMo-V2-Pro: By Xiaomi, 1T parameter MoE, led by former DeepSeek researchers, agent-specialized
– DeepSeek V4: Open source, coding-focused, input tokens at $0.30 (lowest tier pricing)
– For agent tasks, go with MiMo. For coding and cost, DeepSeek V4 is the pick.
Xiaomi Made an AI Model?
MiMo-V2-Pro was built by Xiaomi’s AI team. The team name is MiMo. In late 2025, key DeepSeek researcher Luo Fuli moved to Xiaomi. His team built MiMo-V2-Pro.
The launch was unusual. In early March, they uploaded it to OpenRouter without a developer name. Performance was good, so developers started using it. Billions of tokens processed daily, #1 in total usage. The AI community was full of speculation: “It’s DeepSeek V4,” “It’s a secret OpenAI project.”
The official announcement came on March 18-19. Hunter Alpha = MiMo-V2-Pro. Tokens processed during the test period exceeded 1 trillion.
The MiMo lineup has three models. MiMo-V2-Pro is the flagship for agent tasks. MiMo-V2-Omni is multimodal (text+image+audio). MiMo-V2-TTS is high-quality text-to-speech.
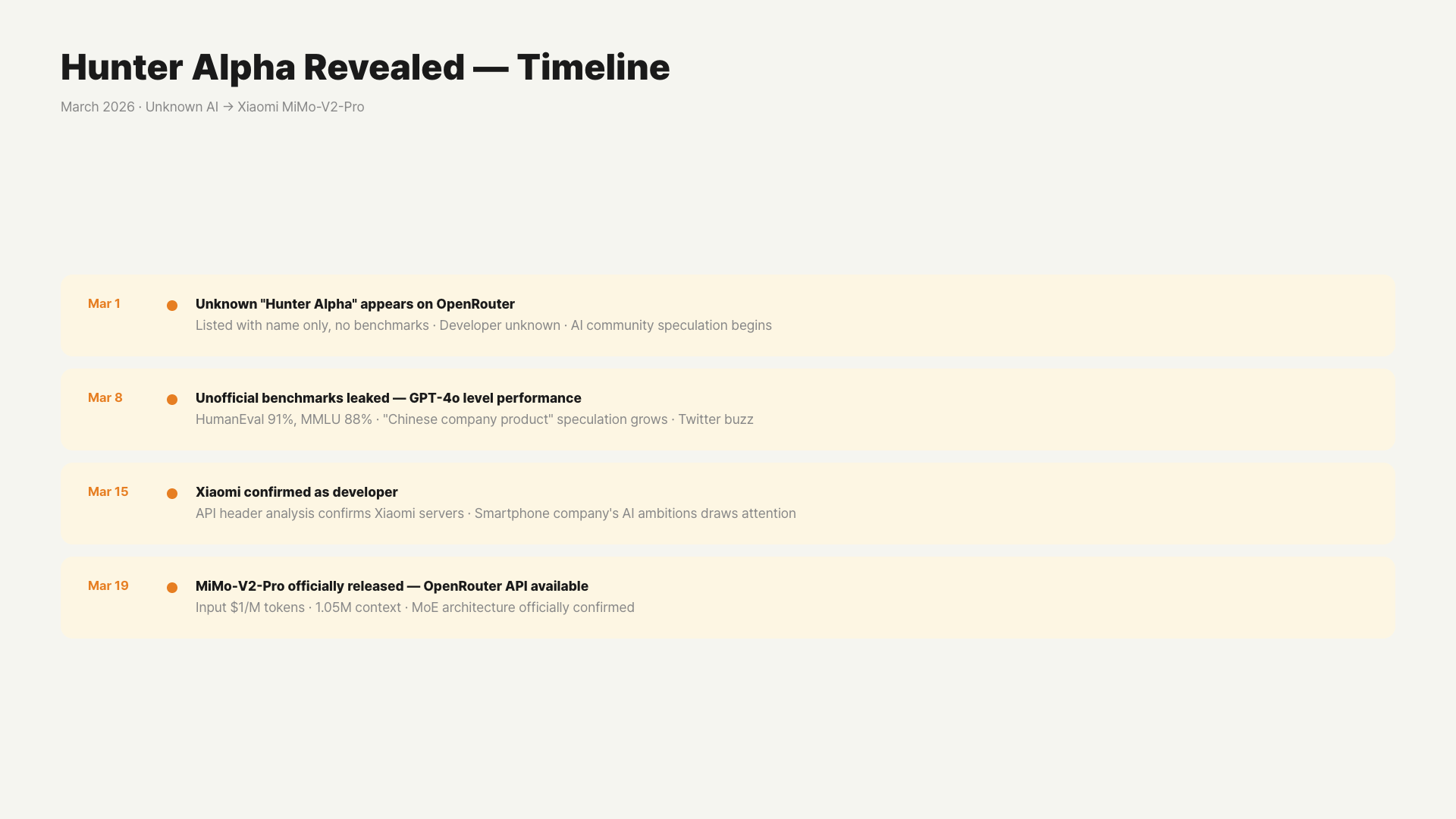
The Hunter Alpha Mystery — Timeline
The launch method itself is a story. Let’s walk through it chronologically.
- March 1-3: Quietly registered on OpenRouter under the name ‘Hunter Alpha.’ No developer information.
- March 4-7: Developers started testing. Reviews praised its surprising agent task performance. Processing billions of tokens daily, it hit #1 in total OpenRouter usage.
- March 8-17: The AI community began speculating on its identity. Rumors circulated: “DeepSeek V4 private version,” “OpenAI stealth model,” “Anthropic experimental model.”
- March 18-19: Xiaomi makes the official announcement. Hunter Alpha = MiMo-V2-Pro. Reveals 1 trillion tokens processed during test period.
Typical AI model launches go: announcement → demo → release. Xiaomi did it backwards. They proved performance first, then revealed the identity. This approach doubled community interest.

Parameters, context, benchmarks, API pricing — 3-model comparison / GoCodeLab
Core Specs Comparison
Both models use MoE (Mixture-of-Experts) architecture. Total parameters are 1 trillion, but only a portion is actually activated. This structure reduces inference costs.
| Category | MiMo-V2-Pro | DeepSeek V4 |
|---|---|---|
| Release Date | March 18, 2026 | Early March 2026 |
| Total Parameters | 1T (MoE) | 1T (MoE) |
| Active Parameters | 42B | 37B |
| Context | 1M Tokens | 1M Tokens |
| Open Source | Closed (API Only) | Open Source |
| Key Strength | Agent Tasks | Coding |
| Development Background | Former DeepSeek Researchers | DeepSeek Team |
The architecture is similar. But the strengths differ.
Benchmark Performance — How Strong Are They Really?
On official agent benchmarks, MiMo-V2-Pro ranks #3 globally. PinchBench 84.0, ClawEval 61.5. Positions 1 and 2 are Claude models. It outperformed the GPT-5.x series. Agent task performance approaching Claude Sonnet 4.6.
DeepSeek V4 excels in coding benchmarks. It recorded HumanEval 90% and SWE-bench 80%+ in internal benchmarks. External validation isn’t fully complete yet. But it’s well-regarded among developers as a coding assistant.
In summary: MiMo-V2-Pro leads in agent and tool-use tasks. DeepSeek V4 is stronger in coding and development. If you need multimodal, use MiMo-V2-Omni (separate model).
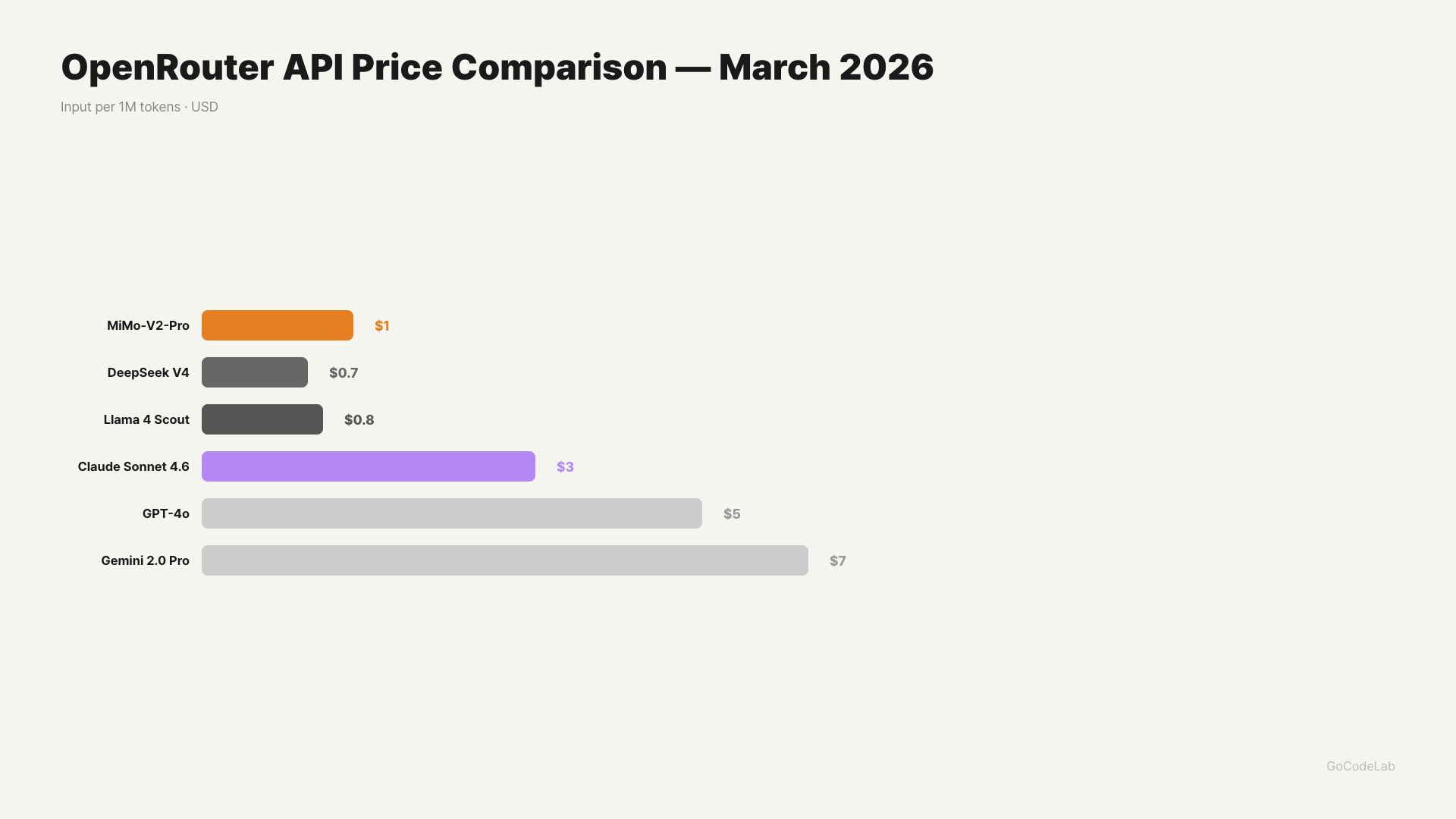
Price Comparison — Which Is Cheaper?
Both models are significantly cheaper than GPT-5.4 or Claude Opus 4.6.
| Model | Input (1M Tokens) | Output (1M Tokens) |
|---|---|---|
| MiMo-V2-Pro (under 256K) | $1.00 | $3.00 |
| MiMo-V2-Pro (over 256K) | $2.00 | $6.00 |
| DeepSeek V4 | $0.30 | Undisclosed |
| Claude Opus 4.6 (reference) | $15.00 | $75.00 |
On price alone, DeepSeek V4 wins. But MiMo-V2-Pro is also just 1/5 of Claude Opus 4.6. Right now it’s the first-week free period, so you can try it without commitment.
Which Model for Which Situation?
When MiMo-V2-Pro Is Right
When building AI agents or automating complex workflows. It’s also a viable option when you need Claude-level agent performance but the cost is prohibitive. It’s worth trying for testing during the current free period.
When DeepSeek V4 Is Right
When using it as a coding assistant. When you want to host it on your own server since it’s open source. When you want to minimize input token costs.
Both come from Chinese AI companies. And both are directly competing with US big tech. Until last year, AI was about OpenAI, Anthropic, and Google. Not anymore.

MoE Architecture, Simply Explained
Once you understand what MoE (Mixture of Experts) is, it immediately makes sense why a trillion-parameter model can be fast.
Think of it this way. You have a team of 100 experts. When a question comes in, only the 4 experts relevant to that question are called to answer. The other 96 stay on standby. The entire team doesn’t always work — only the relevant experts are selectively activated.
Both MiMo-V2-Pro and DeepSeek V4 use this approach. They don’t use all 1 trillion parameters — for each token, only the relevant expert parameters are pulled. That’s why inference costs are low and speed is fast.
MiMo-V2-Pro activates 42B and DeepSeek V4 activates 37B. This difference translates to the performance gap in agent tasks.
When Is MiMo-V2-Pro Most Effective?
We get that specs are good, but here’s a practical breakdown of what tasks to use it for.
Agent Automation Pipelines
MiMo-V2-Pro is particularly strong on agent benchmarks. For multi-step tasks — like “data collection → analysis → report writing → email sending” — it doesn’t miss intermediate steps. Thanks to 1.05M context, it can process long documents in their entirety.
Long Document Processing
You can feed and analyze hundreds-of-pages documents like contracts, reports, and legal documents all at once. The 8x longer context compared to GPT-4o’s 128K really shines here.
Coding Assistant
As expected from a model built by former DeepSeek team members, coding performance is also strong. HumanEval 91.2% slightly edges out GPT-4o’s 90.2%. It’s great for feeding an entire large codebase into context for refactoring.
MiMo-V2-Pro is still in beta. API stability may not be perfect, and response speed can vary by time of day. Validate it for testing and prototype purposes before deploying in production services.
FAQ
Q. Can I use MiMo-V2-Pro right now?
Yes. You can apply for API access at platform.xiaomimimo.com. The first week after launch is free. You can also access it directly on OpenRouter.
Q. Is DeepSeek V4 really open source?
Yes. DeepSeek V4 is released as open source. You can host and run it on your own server. MiMo-V2-Pro is currently API-only.
Q. Is it officially confirmed that Hunter Alpha was MiMo-V2-Pro?
Yes. Xiaomi confirmed it in their official announcement on March 19. Hunter Alpha was the private test codename for MiMo-V2-Pro.
Q. Is MiMo-V2-Omni a different model from Pro?
It’s a different model. Omni processes text, images, and audio together. Pro focuses on text and agent tasks. Use Omni for multimodal needs, Pro for agent tasks.
Q. Do both models handle Korean well?
MiMo-V2-Pro is optimized for English and Chinese. Korean performance hasn’t been sufficiently validated externally. DeepSeek V4 is in a similar situation. For Korean language tasks, Claude or GPT models are more reliable.
Wrap Up
Six months ago, it was hard to imagine Xiaomi releasing an AI model. But they brought in former DeepSeek researchers and built a trillion-parameter model. It now sits just below Claude on agent benchmarks.
DeepSeek V4 still has strengths in coding and cost. MiMo-V2-Pro has strengths in agent and high-performance tasks. Since MiMo-V2-Pro is in its free period right now, trying it yourself is the fastest way to decide.
Try MiMo-V2-Pro now before the first-week free period ends.
This article was written on March 21, 2026. Benchmark scores and pricing are based on official announcements and may change.
At GoCodeLab, we try AI tools hands-on and share honest reviews. Subscribe for more AI news.
Related: DeepSeek V4 Is Out — Is It Really a GPT-5 Rival? · Gemini 3.1 Pro vs Claude Opus 4.6 vs GPT-5.3 Comparison · Tried Grok 4.20 — Faster Than GPT-5.4, But Is It Smarter?