Claude Opus 4.7 출시 — GPT-5.4 압도, Mythos엔 진다 인정했다
Anthropic이 2026년 4월 16일 Claude Opus 4.7을 공개했다. SWE-bench Pro에서 64.3%로 GPT-5.4(57.7%)를 앞섰지만, 내부 Mythos Preview에는 밀린다고 공개 인정했다. 벤치마크·가격·1M 컨텍스트 변화를 정리했다.
목차 (9)
2026년 4월 · AI 소식
Anthropic이 2026년 4월 16일 Claude Opus 4.7을 정식 공개했다. 발표 당일 벤치마크 공개와 함께 흥미로운 문장이 붙었다. "우리는 Mythos보다 아래에 있다." 내부 프리뷰 모델에 밀린다는 걸 공개적으로 인정한 셈이다.
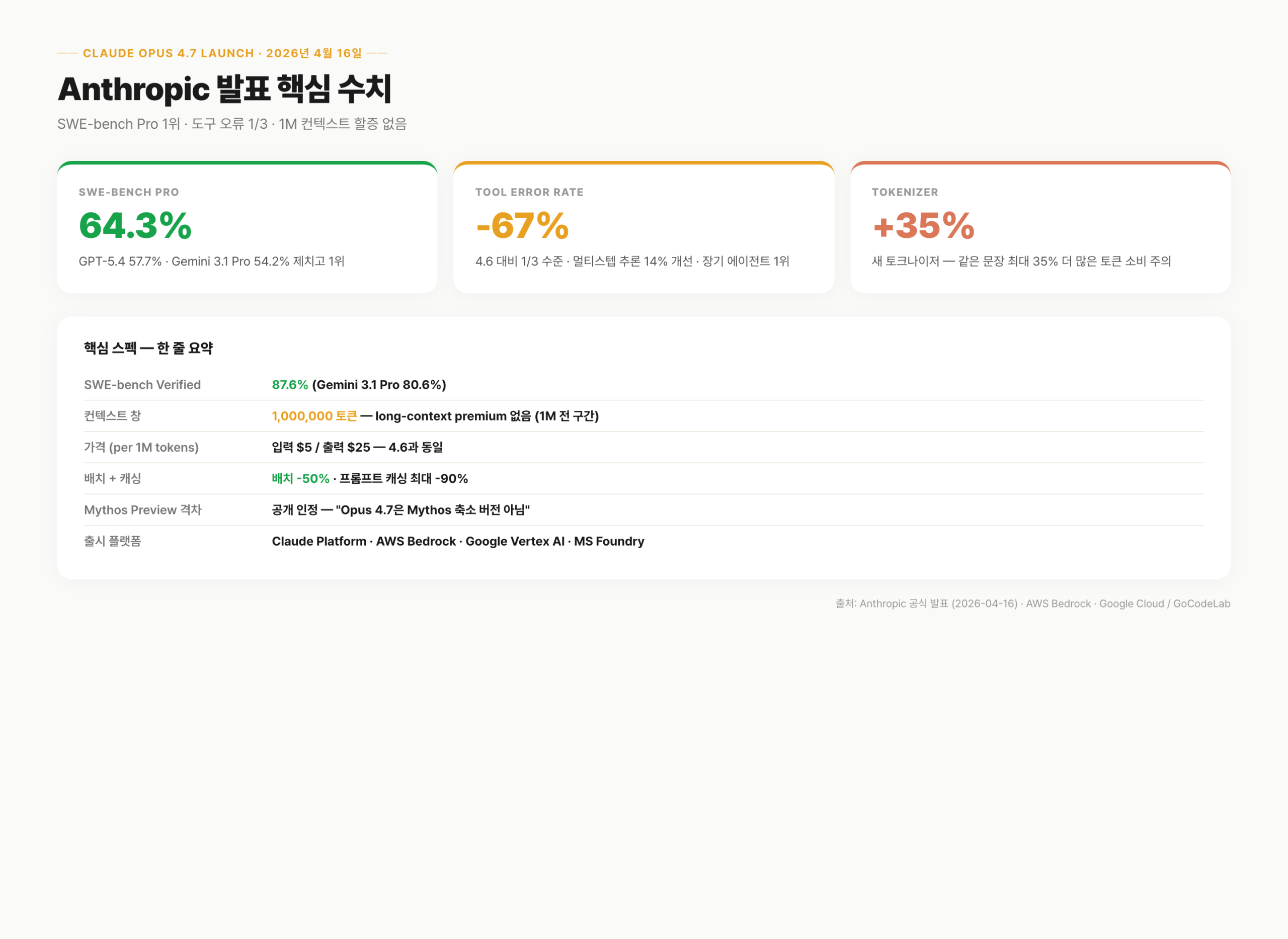
SWE-bench Pro 64.3%로 GPT-5.4(57.7%)와 Gemini 3.1 Pro(54.2%)를 앞섰다. SWE-bench Verified도 87.6%로 Gemini(80.6%)를 제쳤다. 그런데 자사의 비공개 모델 Mythos 앞에서는 수치가 더 낮다고 명시했다. 이런 식의 솔직한 포지셔닝은 최근 AI 업계에서 드문 사례다.
이 글에서는 Opus 4.7의 벤치마크 수치, 가격 구조, Mythos와의 격차를 정리한다. 출시 소식을 빠르게 소화하고 싶은 개발자라면 읽을 가치가 있다. 업무에 AI 모델을 이미 쓰고 있는 사람이라면 가격·배치 구조가 그대로라 당장 갈아타도 된다.
· 출시일: 2026년 4월 16일 — Claude Platform · AWS Bedrock · Google Vertex AI · Microsoft Foundry 동시 공개
· SWE-bench Pro: 64.3% (GPT-5.4 57.7% · Gemini 3.1 Pro 54.2% 앞섬)
· SWE-bench Verified: 87.6% (Gemini 80.6%)
· 컨텍스트 창: 1,000,000 토큰 — 이번 버전부터 long-context premium 없이 단일 단가
· 가격: 입력 $5 / 출력 $25 per 1M tokens (4.6과 동일 단가)
· 배치 API 50% 할인 + 프롬프트 캐싱 최대 90% 절감
· 도구 오류율: 4.6 대비 1/3 수준 · 이미지 해상도 3배 · 멀티 에이전트 조율 개선
· Mythos와의 격차: 공개 인정 — "Opus 4.7은 Mythos의 축소 버전 아님" 명시
· 새 토크나이저: 같은 문장 기준 최대 35% 더 많은 토큰 — 실질 청구액 주의
발표 요약 — 숫자 3가지로 본 Opus 4.7
발표 내용을 숫자 셋으로 압축하면 이렇다. SWE-bench Pro 64.3% 1위, 도구 오류 4.6 대비 1/3 수준, 1M 토큰 컨텍스트에서 long-context premium 없음. 이 셋이 Anthropic이 반복해서 강조한 포인트다.
Opus 4.7은 이전 Opus 4.6에서 주로 도구 사용 안정성과 에이전트 조율 능력을 끌어올린 버전이다. 아키텍처를 갈아엎은 게 아니라 같은 계보를 다듬었다. 그래서 API 호환도 그대로다. 기존 코드를 건드릴 필요 없이 모델명만 바꾸면 된다.
발표 자료에는 Mythos와의 비교 표가 이례적으로 포함됐다. 일반 공개되지 않은 내부 모델을 자사 신제품 발표에서 직접 언급한다는 건 업계 관행에서 벗어난 움직임이다.
SWE-bench Pro에서 GPT-5.4를 앞섰다
SWE-bench Pro는 실제 GitHub 이슈를 자동으로 해결하는 능력을 측정한다. 시험지를 주고 코드를 고치라는 것과 같다. Opus 4.7은 이 벤치마크에서 64.3%를 기록했다. GPT-5.4는 57.7%, Gemini 3.1 Pro는 54.2%다. 6.6%p 차이로 1위다.
SWE-bench Verified에서도 같은 흐름이다. Opus 4.7은 87.6%, Gemini 3.1 Pro는 80.6%다. 멀티랭귀지 버전에서는 4.6의 77.8%에서 80.5%로 개선됐다. GDPVal-AA 같은 Elo 기반 지식 업무 벤치마크에서도 1,753점으로 GPT-5.4(1,674)·Gemini(1,314)를 앞섰다.
단, 순위가 뒤집히는 영역이 있다. BrowseComp 같은 웹 리서치 벤치마크는 GPT-5.4 Pro가 89.3%로 1위고, Opus 4.7은 4.6의 83.7%에서 79.3%로 오히려 떨어졌다. Anthropic도 이 점을 공개 자료에 그대로 실었다. "모든 영역에서 1위"가 아니라는 걸 숨기지 않는 접근이다.
Mythos에 진다고 공개 인정한 이유
Claude Mythos Preview는 Project Glasswing으로 제한 배포 중인 내부 모델이다. AWS·Apple·Broadcom·Cisco·CrowdStrike·Google·JPMorganChase·Microsoft·NVIDIA 9개 주요사 + 40여 조직에 방어 보안 목적으로만 제공됐다. Anthropic은 $100M 사용량 크레딧 + $400만 Linux·Apache 재단 기부까지 얹었다.
일반 공개를 거부한 이유는 공격 능력이다. Mythos는 FreeBSD의 17년 된 원격 코드 실행 취약점(CVE-2026-4747)을 자율적으로 발견하고 exploit까지 성공했다. Anthropic 발표에 따르면 최근 몇 주간 주요 OS와 브라우저에서 수천 개 제로데이 취약점을 찾아냈다고 한다. 배포하면 역효과가 크다는 판단이다.
이번 Opus 4.7 발표에서 Anthropic은 "Opus 4.7이 Mythos의 축소 버전이 아니다"라고 명시했다. 즉 성능을 의도적으로 낮춘 제품이 아니라, 서로 다른 계보의 모델이라는 설명이다. 수치상으로는 Mythos가 앞서지만 배포 가능한 모델은 Opus 라인이라는 구도를 확실히 잡았다. OpenAI·Google은 보통 최상위 모델을 공개한다. Anthropic이 "우리 내부에는 더 강한 게 있지만 안전상 배포하지 않는다"고 말하는 건 경쟁 대신 신뢰를 쌓는 전략이다.
Mythos Preview: Glasswing 주요 9개사(AWS · Apple · Google · Microsoft 등) + 40여 조직 제한 배포
자율 공격 능력: FreeBSD CVE-2026-4747 17년 취약점 발견·exploit — 수천 개 제로데이 식별
Opus 4.7: 일반 배포 가능 최상위 — "Mythos 축소 버전 아님" Anthropic 공식 입장
출처: Claude Mythos 시스템 카드 분석 — GoCodeLab
가격 구조 — 단가 유지, 토크나이저는 바뀜
단가는 입력 $5 / 출력 $25 per 1M tokens다. Opus 4.6과 동일하다. 배치 API 50% 할인도 유지된다. 프롬프트 캐싱은 최대 90% 할인이 가능하다. GPT-5.4와 Gemini 3.1 Pro는 배치 할인이 없다.
배치 API는 요청을 묶어서 비동기로 처리하는 방식이다. 편의점 계산대를 여러 개 동시에 여는 것과 비슷하다. 문서 분석, 코드 리뷰 파이프라인, 대량 테스트 생성에 적합하다. 인터랙티브 작업에는 쓸 수 없다.
주의할 점은 토크나이저다. Opus 4.7은 이전 버전과 다른 새 토크나이저를 쓴다. 같은 문장을 쪼갤 때 최대 35% 더 많은 토큰을 소비한다는 보고가 있다. 단가는 같아도 실질 청구액이 올라갈 수 있다는 뜻이다. 운영 전환 전에 대표 프롬프트로 토큰 수를 직접 측정해보는 게 맞다.
컨텍스트 창 — 1M 전구간 단일 단가
컨텍스트 창은 1,000,000 토큰이다. Anthropic이 이번 버전부터 공식 스펙에 명시했다. GPT-5.4(1,050,000)·Gemini 3.1 Pro(1,000,000)와 동급이다. 컨텍스트 창은 작업 책상 크기와 같다. 클수록 한 번에 더 많은 코드를 펼쳐놓을 수 있다.
눈여겨볼 변화는 long-context premium 폐지다. 이전 Opus는 장기 컨텍스트 구간에서 추가 요금이 붙었다. 4.7부터는 1M 전 구간에서 단일 단가를 유지한다. GPT-5.4의 272K 초과 2배, Gemini 3.1 Pro의 200K 초과 2배 할증과 비교된다.
실제 운영에서 백만 토큰을 전부 채우는 경우는 드물다. 수십만 줄짜리 레거시 코드베이스를 통째로 분석할 때나 실질적으로 필요한 크기다. 일반 프로젝트에서는 세 모델 모두 충분하다. 다만 긴 컨텍스트를 자주 쓰는 파이프라인이라면 Opus의 할증 없는 구조가 실질 비용에서 유리하다.
도구 오류율 — 4.6 대비 1/3, 멀티스텝 추론 14% 개선
에이전트 루프에서 도구 오류율은 중요한 지표다. 모델이 외부 API를 잘못 호출하거나 출력 형식을 틀리면 전체 작업이 중단된다. Anthropic이 공개한 수치에 따르면 Opus 4.7의 도구 오류율은 4.6 대비 1/3 수준으로 떨어졌다. 멀티스텝 에이전트 추론 성능도 14% 개선됐다.
짧은 단일 작업에서는 오류율 차이가 체감되지 않는다. 그러나 10단계 이상의 에이전트 루프에서는 누적 오류가 쌓인다. 밤새 자율 실행하는 파이프라인에서 한 번의 오류가 전체 결과를 망가뜨린다. 이 안정성이 Opus 라인의 핵심 경쟁력이다.
추가로 이미지 처리 해상도가 3배 올랐다. 시각 자료가 많은 워크플로우(스크린샷 기반 QA, PDF 분석, UI 테스트)에서 실질 성능 향상이 있다. 멀티 에이전트 조율에서 몇 시간짜리 작업을 안정적으로 완주하는 능력도 4.7의 중요한 업그레이드 포인트다.
경쟁 구도 — GPT·Gemini의 반응
OpenAI와 Google의 공식 반응은 아직 없다. GPT-5.5가 다음 달로 예고되어 있고, Gemini 3.2 Pro도 연내 출시가 잡혀 있다. 벤치마크 점수를 둘러싼 경쟁은 다음 분기까지 이어질 것으로 보인다.
개발자 커뮤니티의 반응은 나뉜다. 수치 경쟁보다 배치 API 할인·장기 컨텍스트 할증 없음이 실제 운영에서 더 중요하다는 의견이 많다. 단순히 1위 모델 하나를 쓰기보다 용도별로 나눠 쓰는 패턴이 더 합리적이라는 흐름이다.
여기서 Anthropic의 투명한 Mythos 언급은 장기적으로 신뢰 자본을 쌓는 움직임이다. 지금 벤치마크 1위보다, 1년 뒤 기업 도입 우선순위에서 먼저 떠오르는 이름이 되는 게 Anthropic의 전략으로 읽힌다.
개발자 체감 변화
기존 Claude 사용자에게 가장 큰 체감 포인트는 에이전트 루프의 안정성이다. 10단계 이상의 복잡한 도구 호출에서 중간 실패 빈도가 눈에 띄게 줄었다. Cursor·Cline 같은 IDE 통합 환경에서도 동일한 경향이 보고되고 있다.
API 사용자는 모델명만 바꾸면 된다. `claude-opus-4-6`을 `claude-opus-4-7`로 교체하는 것만으로 적용된다. 요청/응답 스키마 변경은 없다. 기존 프롬프트를 재조정하지 않아도 대부분 동일하게 작동한다. AWS Bedrock, Google Cloud Vertex AI, Microsoft Foundry에서도 동시 공개라 클라우드 파트너 사용자도 즉시 전환 가능하다.
바이브코딩하는 비개발자 입장에서는 Claude.ai 인터페이스에서 자동으로 Opus 4.7이 적용된다. 특별히 설정할 것이 없다. 다만 Max 요금제의 사용 한도 안에서 돈다. Pro 요금제는 이전과 동일하게 제한이 있다.
const response = await anthropic.messages.create({
model: 'claude-opus-4-7', // 기존: 'claude-opus-4-6'
max_tokens: 4096,
messages: [{ role: 'user', content: prompt }],
});
단가는 동일하지만 새 토크나이저 때문에 실질 청구액은 약간 올라갈 수 있다. 같은 문장 기준 최대 35% 더 많은 토큰을 쓸 수 있다는 외부 분석이 있다. 운영 전에 프롬프트 몇 개로 토큰 소비량을 먼저 재보는 걸 권장한다.
FAQ
Q. Claude Opus 4.7은 어떤 벤치마크에서 GPT-5.4를 이겼나?
SWE-bench Pro 64.3% (GPT-5.4 57.7%), SWE-bench Verified 87.6% (Gemini 80.6%), GDPVal-AA 1,753점 (GPT-5.4 1,674)에서 앞섰다. 단, BrowseComp 같은 웹 리서치는 GPT-5.4 Pro가 89.3%로 1위고 Opus는 79.3%로 이전보다 오히려 떨어졌다.
Q. Mythos에 진다는 걸 왜 공개적으로 인정했나?
Mythos Preview는 Glasswing 주요 9개사 + 40여 조직에 제한 배포 중인 내부 모델이다. 자율로 제로데이 취약점을 찾고 exploit 하는 공격 능력 때문에 일반 공개를 거부했다. Anthropic은 "공개 가능한 최상위 모델은 Opus 4.7"이라는 포지셔닝을 명확히 하려는 의도로 보인다. 투명성 강조가 장기 신뢰 확보 전략에 가깝다.
Q. Claude Opus 4.7의 컨텍스트 창은 얼마인가?
1,000,000 토큰이다. 이번 버전부터 공식 스펙에 명시됐고, 1M 전체 구간에서 long-context premium 없이 단일 단가가 적용된다. GPT-5.4(272K 초과 2배), Gemini 3.1 Pro(200K 초과 2배)와 비교된다.
Q. 가격과 배치 API 할인은?
입력 $5 / 출력 $25 per 1M tokens다. Opus 4.6과 동일하다. 배치 API 50% 할인 + 프롬프트 캐싱 최대 90% 할인이 모두 유지된다. 단, 새 토크나이저는 같은 문장을 최대 35% 더 많은 토큰으로 쪼갤 수 있다. 단가가 같아도 실질 청구액은 올라갈 수 있다.
Q. 언제부터 쓸 수 있나?
2026년 4월 16일부터 Claude Platform, Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry에서 즉시 사용 가능하다. Cursor·Cline·Zed 같은 3rd party IDE는 대부분 24시간 내에 모델 선택 옵션을 추가했다. 기존 API 사용자는 모델명만 교체하면 된다.
Opus 4.7은 깜짝 놀랄 만한 신기능보다, 에이전트 안정성과 가격 구조를 유지하면서 벤치마크를 끌어올린 버전이다. 실제 운영에 쓰는 입장에서는 이쪽이 더 실용적인 업데이트다. 일단 모델명만 바꿔 써보고 체감 차이를 확인하면 된다.
Mythos 언급은 재미있는 신호다. 공개 가능한 최고 모델이 아니라는 걸 스스로 밝히는 건, 안전성과 배포 책임을 사업의 핵심 가치로 내세운 움직임이다. 장기적으로는 기업 도입 단계에서 Anthropic이 우위를 가져갈 수 있는 포지션이다.
· Anthropic News — Introducing Claude Opus 4.7
· Anthropic — Claude Opus 모델 페이지
· Anthropic API Docs — What's new in Claude Opus 4.7
· Anthropic Pricing
· AWS — Claude Opus 4.7 on Amazon Bedrock
· Claude Mythos 시스템 카드 분석 — GoCodeLab
이 글은 2026년 4월 16일 공개된 Anthropic 발표 자료와 Amazon Bedrock, Google Vertex AI 공식 공지를 바탕으로 작성했다. 수치와 가격은 변경될 수 있다.
Claude, Claude Opus, Claude Mythos는 Anthropic의 등록 상표다.