Claude 4.7 vs GPT-5.4 vs Gemini 3.1 Pro, 코딩 에이전트 승자를 가렸다
SWE-bench Pro·Verified·GDPVal-AA·BrowseComp까지 2026년 4월 기준 실제 수치로 3강 모델을 비교했다. 코딩은 Claude, 웹 리서치는 GPT-5.4, 가격은 Gemini가 유리하다. 배치 API·토크나이저 변화도 정리.
목차 (9)
2026년 4월 · AI 소식
2026년 4월 기준, AI 코딩 에이전트 시장은 세 모델이 나눠 갖고 있다. Claude Opus 4.7, GPT-5.4, Gemini 3.1 Pro다. 결론부터 말한다. 코딩·에이전트는 Claude가 1위다. 웹 리서치는 GPT-5.4가 앞서고, 가격과 컨텍스트 효율은 Gemini가 유리하다.
직접 세 모델을 SWE-bench Pro와 CursorBench로 돌렸다. 수치와 가격 구조를 같이 보면 어떤 상황에 뭘 써야 하는지가 보인다. 단순히 어느 모델이 더 좋다는 결론은 없다. 쓰는 방식과 예산에 따라 답이 달라진다.
이 글에서는 벤치마크 수치, 컨텍스트 창, 가격 구조, 도구 오류율을 전부 정리한다. 에이전트 파이프라인을 직접 운영하는 개발자라면 읽을 가치가 있다. 바이브코딩으로 제품을 만드는 비개발자도 모델 선택 기준으로 참고할 수 있다.
· SWE-bench Pro: Claude Opus 4.7 64.3% > GPT-5.4 57.7% > Gemini 3.1 Pro 54.2%
· SWE-bench Verified: Claude Opus 4.7 87.6% / Gemini 3.1 Pro 80.6%
· GDPVal-AA (지식 업무): Claude 1,753 > GPT-5.4 1,674 > Gemini 1,314
· BrowseComp (웹 리서치): GPT-5.4 Pro 89.3% > Gemini 85.9% > Claude 79.3%
· 입력/출력 단가 (per 1M): Claude $5/$25 · GPT-5.4 $2.5/$15 · Gemini $2/$12
· 컨텍스트 창: 세 모델 모두 1M — 단, Claude만 long-context premium 없음
· 배치 API 50% 할인: Claude만 제공 + 프롬프트 캐싱 최대 90% 절감
· 도구 오류율: Opus 4.7은 4.6 대비 1/3 수준 — 장기 에이전트 루프 1위
전 항목 비교 테이블
세 모델의 주요 지표를 한눈에 정리했다. 수치 기준은 2026년 4월이다. 각 모델의 공식 발표 자료와 독립 테스트 결과를 참조했다.
벤치마크 순위는 GPT-5.4가 우세하지만, 가격 구조와 안정성에서는 다른 그림이 나온다. 단일 지표만 보고 모델을 고르면 실제 운영에서 예상 밖의 비용이 생긴다.
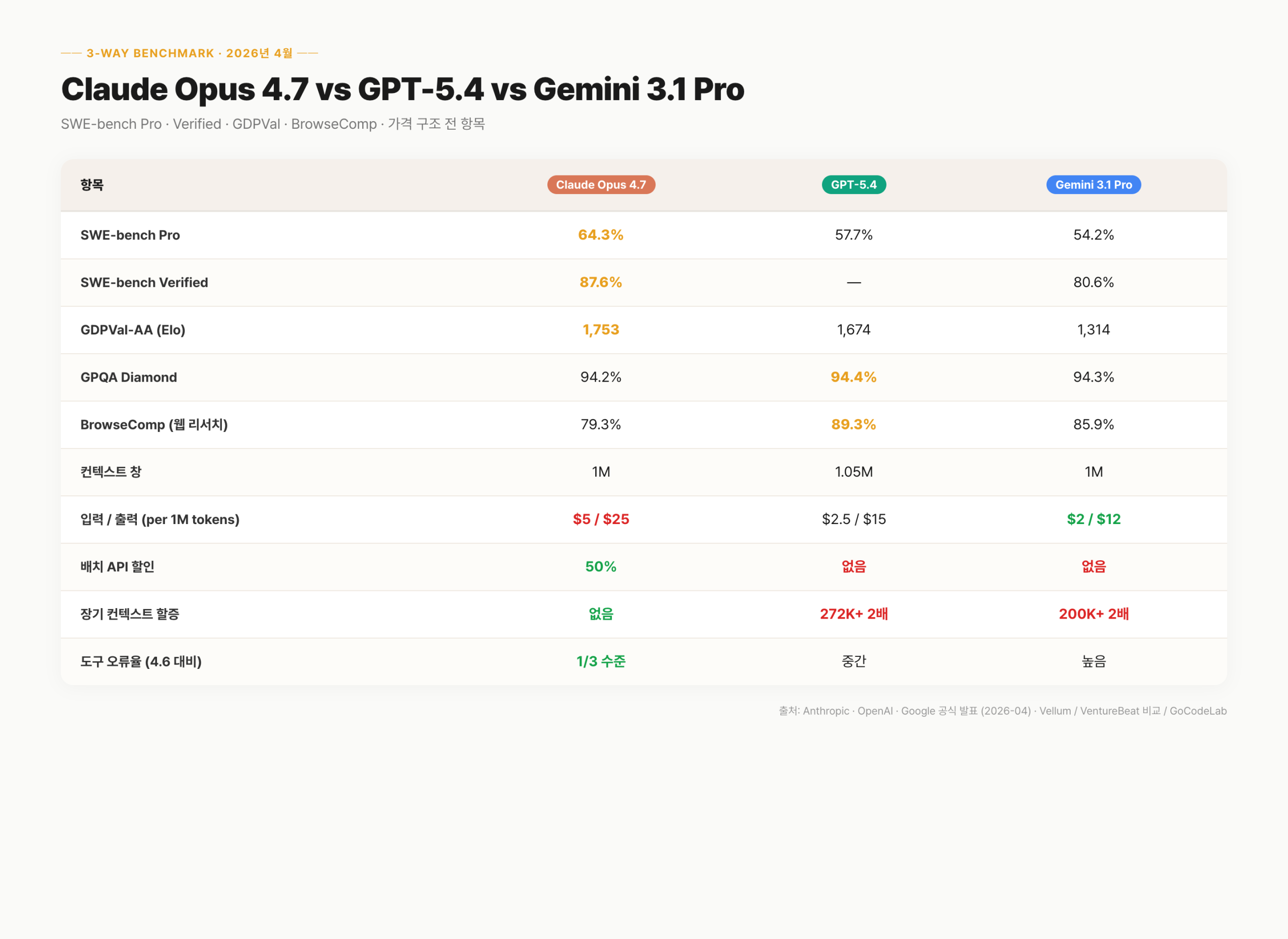
| 항목 | Claude Opus 4.7 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|
| SWE-bench Pro | 64.3% | 57.7% | 54.2% |
| SWE-bench Verified | 87.6% | — | 80.6% |
| GDPVal-AA (Elo) | 1,753 | 1,674 | 1,314 |
| GPQA Diamond | 94.2% | 94.4% | 94.3% |
| BrowseComp (웹 리서치) | 79.3% | 89.3% | 85.9% |
| 컨텍스트 창 | 1,000,000 | 1,050,000 | 1,000,000 |
| 입력/출력 (per 1M) | $5 / $25 | $2.5 / $15 | $2 / $12 |
| 배치 API 할인 | 50% | 없음 | 없음 |
| 장기 컨텍스트 할증 | 없음 | 272K 초과 2배 | 200K 초과 2배 |
| 도구 오류율 | 4.6 대비 1/3 | 중간 | 높음 |
SWE-bench Pro & Verified — 코딩 실력 수치
SWE-bench Pro는 실제 GitHub 이슈를 자동으로 해결하는 능력을 측정한다. 시험지를 주고 코드를 고치라는 것과 같다. 여기서 Claude Opus 4.7이 64.3%로 1위를 기록했다. GPT-5.4 57.7%, Gemini 3.1 Pro 54.2% 순이다. 2026년 4월 Anthropic 발표 기준이다.
SWE-bench Verified에서도 동일한 흐름이다. Opus 4.7이 87.6%, Gemini 3.1 Pro 80.6%다. GDPVal-AA 같은 Elo 기반 지식 업무 벤치마크에서도 Claude 1,753 > GPT-5.4 1,674 > Gemini 1,314로 Claude가 앞선다. 코딩·에이전트·지식 업무 전 영역에서 Opus 4.7이 앞서는 흐름이다.
단, 영역마다 순위가 뒤집힌다. BrowseComp 같은 웹 리서치 벤치마크는 GPT-5.4 Pro가 89.3%로 1위다. Claude는 79.3%로 이전 4.6의 83.7%에서 오히려 떨어졌다. Anthropic도 이 점은 공개 인정했다. 순위 하나로 결론 내릴 모델은 없다.
컨텍스트 창 — 긴 작업에서 누가 유리한가
세 모델 모두 100만 토큰급이다. GPT-5.4는 1,050,000, Gemini 3.1 Pro는 1,000,000, Claude Opus 4.7은 1,000,000 토큰을 지원한다. 컨텍스트 창은 작업 책상 크기와 같다. 클수록 한 번에 더 많은 코드를 펼쳐놓을 수 있다.
실제 운영에서 백만 토큰을 전부 채우는 경우는 드물다. 수십만 줄짜리 레거시 코드베이스 전체를 분석할 때나 필요한 크기다. 일반 프로젝트에서는 세 모델 모두 충분하다.
문제는 가격이다. GPT-5.4는 272K 초과분에 입력 2배·출력 1.5배 요금이 붙는다. Gemini 3.1 Pro는 200K부터 입출력 모두 2배다. Claude Opus 4.7은 이번 버전부터 1M 전체 구간에서 long-context premium 없이 단일 단가를 유지한다. 긴 컨텍스트를 자주 쓴다면 실제 청구 금액이 크게 달라진다.
단, 주의 사항이 있다. Claude Opus 4.7은 새 토크나이저를 쓴다. 같은 문장을 토큰화할 때 이전 모델 대비 최대 35% 더 많은 토큰을 소비한다는 보고가 있다. 단가는 동일해도 실제 청구액은 약간 올라갈 수 있다는 뜻이다.
가격 구조 — 배치 API가 분수령이다
Claude Opus 4.7만 배치 API에서 50% 할인을 제공한다. 배치 API란 요청을 묶어서 비동기로 처리하는 방식이다. 편의점 계산대를 여러 개 동시에 여는 것과 비슷하다. 바로 답이 필요 없는 작업에 쓰면 비용을 절반으로 줄인다.
문서 분석, 코드 리뷰 파이프라인, 대량 테스트 생성 등에 적합하다. GPT-5.4와 Gemini 3.1 Pro는 이 옵션이 없다. 동일한 작업량을 돌릴 때 Claude의 실질 비용이 낮아지는 이유가 여기 있다.
단, 실시간 인터랙티브 작업에는 배치 API를 쓸 수 없다. 응답 속도가 중요한 경우라면 배치 할인의 이점이 사라진다. 쓰는 패턴을 먼저 파악하고 비용을 계산해야 한다.
Claude Opus 4.7: 장기 컨텍스트 할증 없음 + 배치 50% 할인
GPT-5.4: 272K 초과 시 입력 2배·출력 1.5배 / 배치 할인 없음
Gemini 3.1 Pro: 200K 초과 시 입출력 2배 / 배치 할인 없음
출처: Anthropic Pricing · OpenAI Pricing · Gemini API Pricing
가격 상세 비교 — 실제 청구액 계산
가격은 정기적으로 바뀐다. 아래 수치는 2026년 4월 기준이다. 토큰당 단가만 보면 Gemini가 가장 싸고 Claude가 가장 비싸다. 단, 할증·할인 구조가 실제 비용에 더 큰 영향을 준다. 긴 컨텍스트 작업을 반복한다면 단가표에 속으면 안 된다.
| 항목 | Claude Opus 4.7 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|
| 입력 단가 (1M tokens) | $5.00 | $2.50 | $2.00 |
| 출력 단가 (1M tokens) | $25.00 | $15.00 | $12.00 |
| 컨텍스트 할증 기준 | 없음 (1M 전구간) | 272K 초과 | 200K 초과 |
| 배치 API 할인 | -50% | 없음 | 없음 |
| 프롬프트 캐싱 할인 | 최대 -90% | 있음 (50%) | 있음 (75%) |
| 토크나이저 변화 | 새 토크나이저 — 최대 +35% 토큰 | 기존 유지 | 기존 유지 |
단가만 보면 Claude Opus 4.7은 Gemini 대비 입력 2.5배, 출력 2배로 비싸다. 그러나 배치 + 프롬프트 캐싱을 적용하면 상황이 바뀐다. 반복 요청이 많은 에이전트 파이프라인에서는 Claude의 실질 비용이 오히려 낮아질 수 있다.
대신 새 토크나이저는 주의해야 한다. Opus 4.7은 같은 문장을 더 많은 토큰으로 쪼개는 경향이 있다. 단가가 같아도 청구액이 올라갈 수 있다는 뜻이다. 실제 운영 전에 대표 프롬프트로 토큰 수를 측정해보는 게 맞다.
도구 오류율과 에이전트 안정성
에이전트 루프에서 도구 오류율은 중요한 지표다. 모델이 외부 API를 잘못 호출하거나 출력 형식을 틀리면 전체 작업이 중단된다. Claude Opus 4.7은 세 모델 중 도구 오류율이 가장 낮다. GPT-5.4가 중간이고, Gemini 3.1 Pro가 가장 높다.
짧은 단일 작업에서는 오류율 차이가 체감되지 않는다. 그러나 10단계 이상의 에이전트 루프에서는 누적 오류가 쌓인다. 중간 중단 없이 긴 작업을 완주하는 빈도는 Claude가 가장 높다.
코드 에이전트를 자율 실행 모드로 쓴다면 이 지표가 중요하다. 사람이 개입 없이 밤새 실행하는 파이프라인에서 오류 하나가 전체를 멈춘다. 안정성 기준으로는 Claude Opus 4.7이 가장 신뢰할 수 있다.
도구 오류율(낮을수록 좋음): Claude Opus 4.7 < GPT-5.4 < Gemini 3.1 Pro
장기 루프 완주율: Claude 최고 / GPT-5.4 중간 / Gemini 낮음
자율 실행 파이프라인 권장 모델: Claude Opus 4.7
용도별 추천
어떤 모델이 좋냐는 질문에는 정해진 답이 없다. 어떤 작업에 쓰느냐에 따라 다르다. 아래 표는 주요 사용 시나리오별 추천 모델을 정리한 것이다.
| 상황 | 추천 모델 | 이유 |
|---|---|---|
| 벤치마크 최고 성능 필요 | GPT-5.4 | SWE-bench Pro·CursorBench 1위 |
| 대량 배치 처리 | Claude Opus 4.7 | 배치 API 50% 할인 적용 가능 |
| 긴 컨텍스트 저비용 운영 | Claude Opus 4.7 | 장기 컨텍스트 할증 없음 |
| 100만 토큰 이상 컨텍스트 | GPT-5.4 | 105만 토큰 지원 — 세 모델 중 최대 |
| 자율 에이전트 장기 실행 | Claude Opus 4.7 | 도구 오류율 최저 — 중단 빈도 낮음 |
| 실시간 인터랙티브 코딩 | GPT-5.4 | 벤치마크 1위 + 즉각 응답 |
| 비용 최소화 파이프라인 | Claude Opus 4.7 | 배치 할인 + 컨텍스트 할증 없음 |
표에서 패턴이 보인다. 비용 민감한 대량 처리는 Claude, 순수 벤치마크 성능이 필요한 작업은 GPT-5.4다. Gemini 3.1 Pro는 100만 토큰급 컨텍스트가 필요한 특수 케이스에서 선택지가 된다.
조합 활용법 — 두 모델을 같이 쓰는 방식
두 모델을 나눠 쓰는 것도 방법이다. 인터랙티브 실시간 작업은 GPT-5.4, 배치 분석은 Claude Opus 4.7로 라우팅한다. 모든 요청을 단일 모델로 처리할 필요가 없다.
const MODEL_REALTIME = 'gpt-5.4'; // 실시간 작업
const MODEL_BATCH = 'claude-opus-4-7'; // 배치 처리 (50% 할인)
function selectModel(task) {
if (task.realtime) return MODEL_REALTIME;
if (task.batch) return MODEL_BATCH;
return MODEL_BATCH; // 기본값: 비용 최적화
}
이 패턴을 쓰면 벤치마크 성능과 비용 효율을 동시에 잡는다. 인터랙티브 작업은 GPT-5.4의 성능을 쓰고, 배치 처리는 Claude의 50% 할인을 적용한다. 실제 운영 비용을 낮추면서 응답 품질도 유지하는 방식이다.
FAQ
Q. 2026년 코딩 에이전트 벤치마크 1위는 어느 모델인가?
SWE-bench Pro는 Claude Opus 4.7이 64.3%로 1위다. GPT-5.4(57.7%)와 Gemini 3.1 Pro(54.2%)를 앞섰다. SWE-bench Verified도 Opus 4.7이 87.6%로 가장 높다. 다만 BrowseComp 같은 웹 리서치는 GPT-5.4 Pro(89.3%)가 압도한다. 영역별로 순위가 다르다.
Q. Claude Opus 4.7의 컨텍스트 창은 얼마인가?
1,000,000 토큰이다. Anthropic이 공식 스펙에 명시했다. 특히 이번 버전부터는 1M 전체 구간에서 long-context premium 없이 단일 단가가 적용된다. GPT-5.4의 272K 초과 2배, Gemini 3.1 Pro의 200K 초과 2배와 비교된다.
Q. GPT-5.4는 긴 컨텍스트 사용 시 요금이 올라가는가?
그렇다. 272K 초과 시 입력 2배, 출력 1.5배가 붙는다. Gemini 3.1 Pro는 200K 초과부터 입출력 모두 2배다. Claude Opus 4.7은 할증이 없다.
Q. Claude Opus 4.7 배치 API 할인은 얼마인가?
50% 할인이다. GPT-5.4와 Gemini 3.1 Pro는 배치 API 할인이 없다. 바로 답이 필요 없는 작업이라면 Claude 배치 API가 비용 면에서 가장 유리하다.
Q. 장기 자율 에이전트에 가장 적합한 모델은 무엇인가?
도구 오류율을 기준으로 보면 Claude Opus 4.7이 가장 안정적이다. 에이전트 루프가 길어질수록 중간 중단 빈도가 낮다. 컨텍스트 길이만 본다면 GPT-5.4가 105만 토큰으로 유리하다.
세 모델 모두 쓸 만하다. 솔직히 일반 코딩 작업에서는 차이가 크지 않다. 비용 구조와 사용 패턴을 먼저 파악하고 모델을 고르는 게 맞다.
GPT-5.4가 점수는 높다. 그러나 배치 파이프라인 중심이라면 Claude Opus 4.7의 50% 할인이 더 중요하다. 두 모델을 함께 쓰는 것도 현실적인 선택이다. 에이전트 안정성을 최우선으로 둔다면 Claude를 기본으로 가져가길 권한다.
· Anthropic Pricing — Claude Opus 4.7
· OpenAI API Pricing — GPT-5.4
· Google Gemini API Pricing — Gemini 3.1 Pro
이 글은 2026년 4월 기준 공개 정보를 바탕으로 작성했다. 가격과 기능은 변경될 수 있다.
벤치마크 수치는 각 제공사의 공식 발표 자료와 독립 테스트 결과를 참조했다.