Grok 4.20 비교 — GPT-5.4보다 빠른데, 더 똑똑하기도 한가요?
Grok 4.20 비교 — GPT-5.4보다 빠른데, 더 똑똑하기도 한가요?
2026년 3월 15일 · A. 모델/툴 비교
xAI가 2월 17일에 Grok 4.20 Beta를 처음 공개했어요. 이후 3월 3일에 Beta 2, 3월 10일에 Beta 0309(Reasoning 버전)까지 빠르게 업데이트됐어요. 가장 눈에 띄는 숫자가 세 개 있어요. 초당 259.7 토큰이라는 생성 속도, AA-Omniscience 비환각률 1위 기록, 그리고 4개의 AI 에이전트가 서로 토론하는 완전히 새로운 구조예요. GPT-5.4 대비 속도가 4배 이상 빠르고, Claude Sonnet 4.6까지 포함해서 3개 모델을 직접 비교해봤어요.
– Grok 4.20은 2월 17일 최초 공개 → 3월 3일 Beta 2 → 3월 10일 Beta 0309(Reasoning)으로 빠르게 진화 중이에요
– 4개의 AI 에이전트(Grok, Harper, Benjamin, Lucas)가 서로 토론한 뒤 합의된 답변을 내놓는 구조예요
– 출력 속도 초당 259.7토큰으로 GPT-5.4보다 4배 이상 빨라요
– AA-Omniscience 비환각률 78%로 테스트된 모든 모델 중 1위를 기록했어요
– 코딩 인덱스 42.2점으로 코드 생성 작업에서 최상위권이에요
– API 가격은 입력 $2, 출력 $6 (100만 토큰당)이에요
Grok 4.20이 뭔가요?
Grok은 일론 머스크의 xAI가 만드는 AI 모델이에요. GPT나 Claude와 비슷한 포지션이에요.
2월 17일에 처음 공개된 Grok 4.20은 빠르게 업데이트되고 있어요. 최신 버전인 Beta 0309(3월 10일)는 3가지 변형으로 나왔어요. reasoning(추론), non-reasoning(비추론), multi-agent(멀티 에이전트) 버전이에요. 각각 용도가 달라서, API에서 reasoning 파라미터를 켜고 끄는 식으로 전환할 수 있어요.
이전 Grok 4 대비 Intelligence Index가 6점 올랐어요. 가격은 오히려 내렸고, 컨텍스트 창은 256K에서 200만 토큰으로 대폭 확장됐어요.
4-에이전트 구조가 핵심이에요
Grok 4.20의 가장 큰 차별점은 4-에이전트 아키텍처예요. 하나의 질문에 4개의 AI 에이전트가 동시에 서로 다른 방향으로 생각하고, 토론한 뒤, 합의된 결론을 내놓아요.
4개의 에이전트에는 각각 이름과 역할이 있어요.
Grok — 캡틴 역할이에요. 질문을 분해해서 다른 에이전트에게 할당하고, 충돌을 해결하고, 최종 답변을 합성해요.
Harper — 정보 수집 담당이에요. 관련 데이터와 근거를 모아요.
Benjamin — 검증 담당이에요. Harper가 모은 정보의 정확성을 확인하고, 코딩 작업에서는 문법까지 체크해요.
Lucas — 반론 담당이에요. 다른 세 에이전트의 결론에 의도적으로 반대 의견을 제시해요.
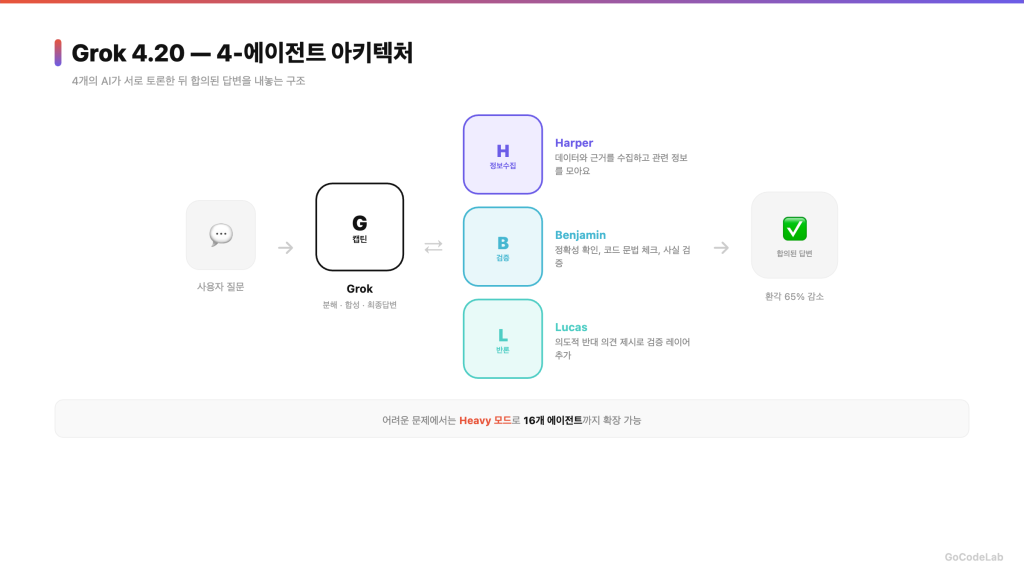
Lucas의 존재가 꽤 인상적이에요. 일부러 반대 의견을 내도록 학습된 에이전트라서, 나머지 셋이 동의하더라도 한 번 더 검증하는 효과가 있어요. 이 구조가 환각을 65% 줄이는 데 기여했다고 xAI는 설명하고 있어요.
어려운 문제에서는 “Heavy” 모드로 16개 에이전트까지 확장할 수 있어요.
주요 지표 비교
같은 조건에서 세 모델의 핵심 지표를 비교하면 이래요.
| 항목 | Grok 4.20 Beta | GPT-5.4 | Sonnet 4.6 |
|---|---|---|---|
| AI 지능 지수 | 48점 | 57점 | 54점 |
| 출력 속도 | 259.7 토큰/초 | 약 60 토큰/초 | 약 80 토큰/초 |
| 첫 응답 대기 | 8.93초 | 약 2.7초 | 약 3초 |
| 입력 가격 | $2/M | $2.5/M | $3/M |
| 출력 가격 | $6/M | $10/M | $15/M |
| 컨텍스트 | 200만 토큰 | 100만 토큰 | 100만 토큰 |
| 비환각률 | 78% (1위) | 공식 미발표 | 공식 미발표 |
| 코딩 인덱스 | 42.2점 | 40.1점 | 41.8점 |
| 베타 여부 | 베타 | 정식 출시 | 정식 출시 |
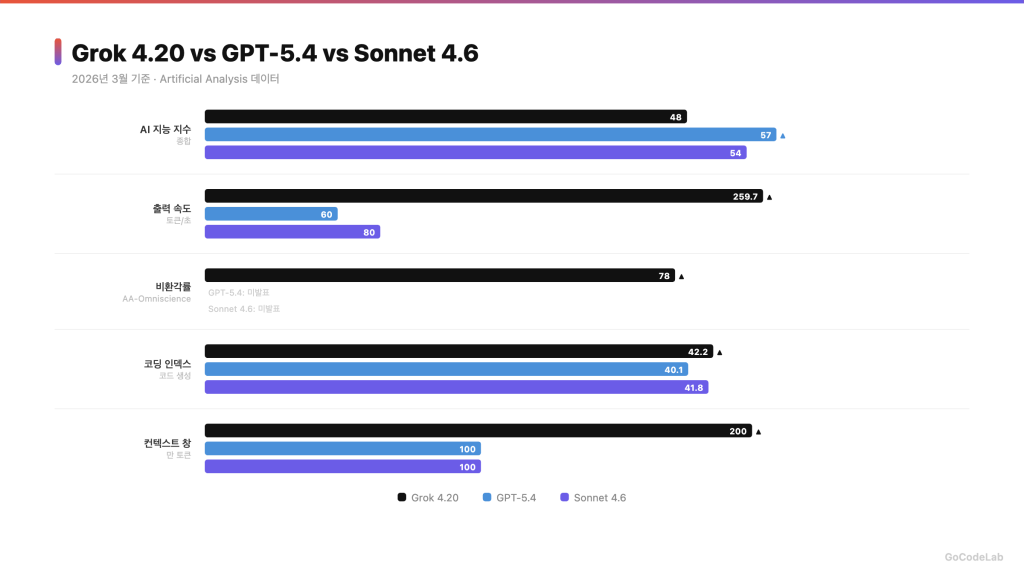
숫자만 보면 GPT-5.4가 가장 똑똑하고, Grok 4.20이 가장 빠르고, Claude Sonnet 4.6은 코딩에서 강해요.
속도는 정말 체감이 달라요
초당 259.7 토큰이 어느 정도냐면, 같은 가격대 추론 모델의 중간값(61.9 토큰/초)보다 4배 이상 빠른 거예요.
긴 리포트나 코드 블록을 생성할 때, 기다리는 시간이 확실히 짧아요. 빠른 속도는 특히 업무에서 반복 작업을 할 때 체감 차이가 크거든요.
단, 첫 응답까지 걸리는 시간(TTFT)은 8.93초로 조금 길어요. 이건 4개 에이전트가 먼저 토론하는 시간이에요. 첫 글자가 뜨기까지는 오히려 느리고, 그 이후 쏟아지는 속도가 빠른 구조예요.
비환각률 1위는 진짜 의미 있어요
AA-Omniscience는 6,000개 질문을 42개 분야에 걸쳐 사실 정확성과 환각 빈도를 측정하는 벤치마크예요. Grok 4.20은 여기서 비환각률 78%로 테스트된 모든 모델 중 1위를 기록했어요.
이전 Grok 4 대비 환각이 약 65% 줄었다고 xAI는 밝혔어요. 4-에이전트 구조가 자체 검증 레이어 역할을 하면서 달성한 결과예요. Harper가 정보를 모으고, Benjamin이 확인하고, Lucas가 반박하고, Grok이 교차 검증하는 과정을 거치거든요.
단, 78%라는 건 22%는 여전히 틀릴 수 있다는 얘기예요. “환각이 없다”는 뜻이 아니에요.
가격은 꽤 합리적이에요
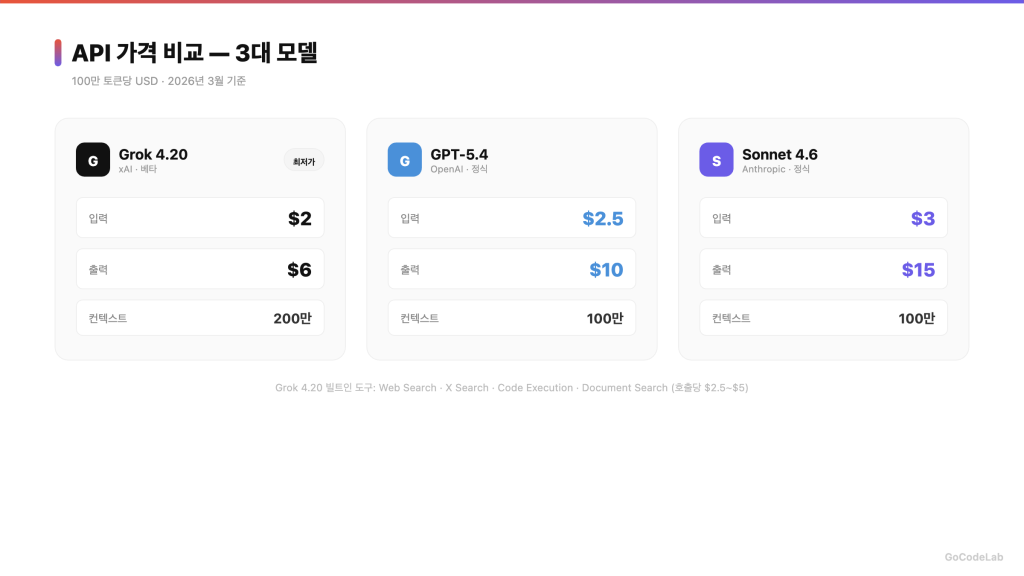
Grok 4.20의 출력 단가가 $6/M으로 GPT-5.4($10/M)나 Sonnet 4.6($15/M)보다 확실히 저렴해요. 출력이 많은 작업에서 비용 차이가 누적돼요.
추가로 빌트인 도구도 제공해요. Web Search, X Search, Code Execution, Document Search를 API에서 바로 쓸 수 있는데, 호출당 $2.50~$5 별도 과금이 있어요.
지능 점수 차이는 어디서 나요?
Artificial Analysis의 AI 지능 지수에서 GPT-5.4는 57점, Claude Sonnet 4.6은 54점, Grok 4.20은 48점이에요. Gemini 3.1 Pro도 GPT-5.4와 동급인 57점이에요.
GPT-5.4는 GDPval 벤치마크에서 실제 직업 전문가 수준을 83%의 직종에서 넘었어요. 이건 “논리 퀴즈 잘 푸는 것”과 다르게, 실제 업무 질문에 얼마나 잘 답하느냐를 측정한 거예요. Grok 4.20은 이 지표에서는 아직 GPT-5.4에 못 미쳐요.
어떤 상황에 어울릴까요?
세 모델이 각각 더 잘 맞는 경우가 달라요.
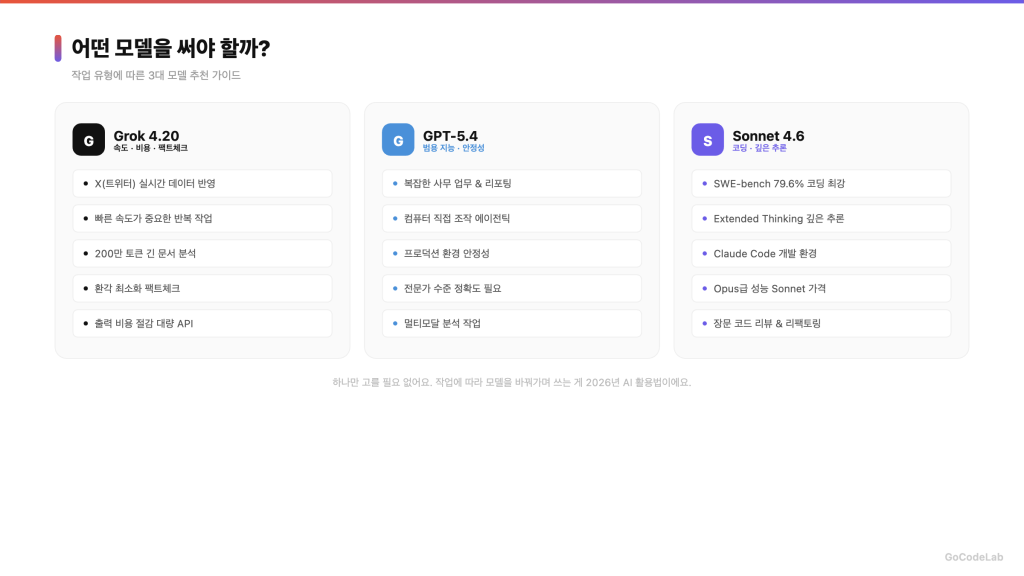
Grok 4.20이 더 유리한 경우: X(트위터)의 실시간 소식을 반영해야 할 때, 빠른 속도가 중요한 반복 작업(코드 생성, 번역 등), 긴 문서를 통째로 분석할 때(200만 토큰 컨텍스트), 환각을 최소화해야 하는 팩트체크 작업, 출력 비용을 아껴야 하는 대량 API 호출이에요.
GPT-5.4가 더 유리한 경우: 복잡한 사무 업무(문서 작성, 데이터 분석, 리포팅), 컴퓨터를 직접 조작하는 에이전틱 작업, 안정적이고 일관된 결과가 중요한 프로덕션 환경, 전문가 수준의 정확도가 필요한 업무예요.
Claude Sonnet 4.6이 더 유리한 경우: 코딩 작업(SWE-bench 79.6% 최상위), Extended Thinking으로 깊은 추론이 필요한 경우, Claude Code 개발 환경, Opus급 성능을 Sonnet 가격에 쓰고 싶을 때예요.
하나만 쓸 필요는 없어요. 작업 유형에 따라 모델을 골라서 쓰는 게 2026년 AI 활용법의 핵심이에요.
직접 써본 소감
빠르다는 건 진짜예요. 긴 텍스트를 생성할 때 GPT나 Claude 계열 모델과 체감 차이가 느껴졌어요.
4-에이전트 토론 구조는 복잡한 수학 문제나 코딩 과제에서 꽤 좋은 결과를 냈어요. 단일 모델과 달리 여러 각도에서 검토하는 느낌이 있었어요. 특히 Lucas의 반론이 포함된 결과물은 편향이 적었어요.
좀 아쉬웠던 건 응답의 일관성이에요. 같은 질문을 여러 번 던졌을 때, Grok 4.20이 GPT-5.4보다 결과가 들쭉날쭉한 경향이 있었어요. 4개 에이전트의 토론 결과가 매번 조금씩 달라지는 거예요. 아직 베타라서 그런 면이 있어요.
TTFT 8.93초는 체감상 꽤 길어요. “빠르다”면서 첫 응답이 느리다는 게 처음엔 혼란스러웠어요. 에이전트들이 먼저 토론하는 시간이라고 생각하면 이해가 돼요.
결론적으로 Grok 4.20은 속도, 비용, 비환각률에서 확실한 장점이 있어요. 범용 지능에서는 GPT-5.4, 코딩에서는 Claude Sonnet 4.6이 앞서지만, Grok만의 자리는 분명해요.
FAQ
Q. Grok 4.20은 무료로 쓸 수 있나요?
X(트위터) 프리미엄 구독자는 일부 무료로 접근할 수 있어요. API로 쓰려면 입력 $2/M, 출력 $6/M 과금이 있어요. 정확한 무료 사용량은 xAI 공식 사이트에서 확인하는 게 정확해요.
Q. Grok 4.20이 한국어를 잘 하나요?
영어 대비 한국어 성능은 아직 GPT-5.4나 Claude보다 떨어지는 편이에요. 한국어 문서를 주로 다룬다면 GPT나 Claude가 더 안정적이에요.
Q. 4-에이전트와 16-에이전트 Heavy 모드는 뭐가 달라요?
기본은 4개 에이전트(Grok, Harper, Benjamin, Lucas)가 협업해요. 더 어려운 문제에서는 Heavy 모드로 16개 에이전트까지 확장돼요. Heavy 모드는 응답 시간이 더 길어지지만 정확도가 올라가요.
Q. reasoning과 non-reasoning 버전은 어떻게 다른가요?
reasoning 버전은 복잡한 추론이 필요한 작업에 적합해요. non-reasoning 버전은 단순한 질답이나 분류 작업에서 더 빠르고 저렴해요. API에서 reasoning 파라미터로 전환할 수 있어요.
Q. AA-Omniscience 비환각률 1위가 의미하는 게 뭔가요?
AA-Omniscience는 42개 분야 6,000개 질문으로 AI의 사실 정확성을 측정하는 벤치마크예요. Grok 4.20이 78%로 1위라는 건, 테스트된 모든 AI 모델 중에서 사실을 가장 정확하게 답한다는 뜻이에요. 단, 22%는 여전히 틀릴 수 있어요.
Q. GPT-5.4, Claude Sonnet 4.6, Grok 4.20 중 뭘 써야 하나요?
하나만 고를 필요 없어요. 범용 업무는 GPT-5.4, 코딩은 Claude Sonnet 4.6, 속도가 중요하거나 실시간 X 데이터가 필요하면 Grok 4.20이 좋아요. 작업에 따라 모델을 바꿔가며 쓰는 게 가장 현실적이에요.
Q. 지금 Grok 4.20을 써야 할까요, 정식 출시를 기다려야 할까요?
속도가 중요하거나 X 실시간 데이터가 필요하다면 지금도 쓸 만해요. xAI가 Q2에 정식 버전을 준비하고 있다는 얘기가 있어요. 개인적으로 병행해서 쓰면서 발전 속도를 지켜보는 게 현실적인 방법이에요.
마무리
Grok 4.20 Beta 0309는 AI 모델 설계의 새로운 접근법을 보여줬어요. 단일 모델이 아니라 4개 에이전트가 토론하는 구조는 환각 감소와 코딩 성능에서 실제로 효과가 있었어요.
속도, 비용, 비환각률에서는 확실한 장점이 있고, 범용 지능에서는 아직 GPT-5.4나 Gemini 3.1 Pro에 못 미쳐요. 하지만 매주 업데이트되고 있고, Q2 정식 출시를 앞두고 있어서 앞으로의 발전이 기대돼요.
2026년 AI 시장은 “하나의 최고 모델”이 아니라, 작업에 맞는 모델을 골라 쓰는 시대가 됐어요. Grok 4.20은 그 선택지 중 확실히 의미 있는 하나예요.
Grok 4.20, GPT-5.4, Claude Sonnet 4.6 비교가 도움이 됐다면 GoCodeLab 블로그를 구독해주세요. 새로운 모델이 나올 때마다 직접 써보고 비교해드릴게요.
이 글은 2026년 3월 15일에 작성됐어요. AI 모델은 빠르게 업데이트되므로, 읽는 시점에 따라 수치나 기능이 달라질 수 있어요.
GoCodeLab에서는 AI 도구를 직접 써보고 솔직하게 알려드려요. 다른 AI 소식이 궁금하면 블로그를 구독해주세요.
관련 글: DeepSeek V4 출시 리뷰 · GPT-5.4 Thinking 업데이트 정리 · Claude Sonnet 4.6 완벽 정리