AI Trends8 min
Claude Sonnet 4.6 Complete Review — Better Than Opus, Really?
Claude Sonnet 4.6 launched in February 2026. At one-fifth the price of Opus, it ranked #1 in real-world office evaluations, with coding just 1.2%p behind. 1M context, Extended Thinking, and 70% developer preference in Claude Code.
March 13, 2026 · AI Trend Analysis
Claude Sonnet 4.6 launched on February 17. It’s one-fifth the price of Opus 4.6. Yet in some evaluations, it outperformed Opus. That was surprising at first — you’d think the more expensive model would always be better. But looking at the benchmark numbers one by one, it turned out to be quite interesting.Quick Summary
What Is Sonnet 4.6?
Anthropic released two new models in early 2026: Opus 4.6 (February 5) and Sonnet 4.6 (February 17). Opus is Anthropic’s top-tier model. It’s also the most expensive. Sonnet is the mid-tier model — fast and affordable. Normally you’d think “the expensive Opus must be better.” This time, things were different. According to Anthropic’s official description, Sonnet 4.6 received full upgrades across coding, computer use, long-context reasoning, agentic planning, knowledge work, and design. It was designated as the default model for Free and Pro plans.Performance Differences by Benchmarks
Office Tasks: Sonnet Takes #1
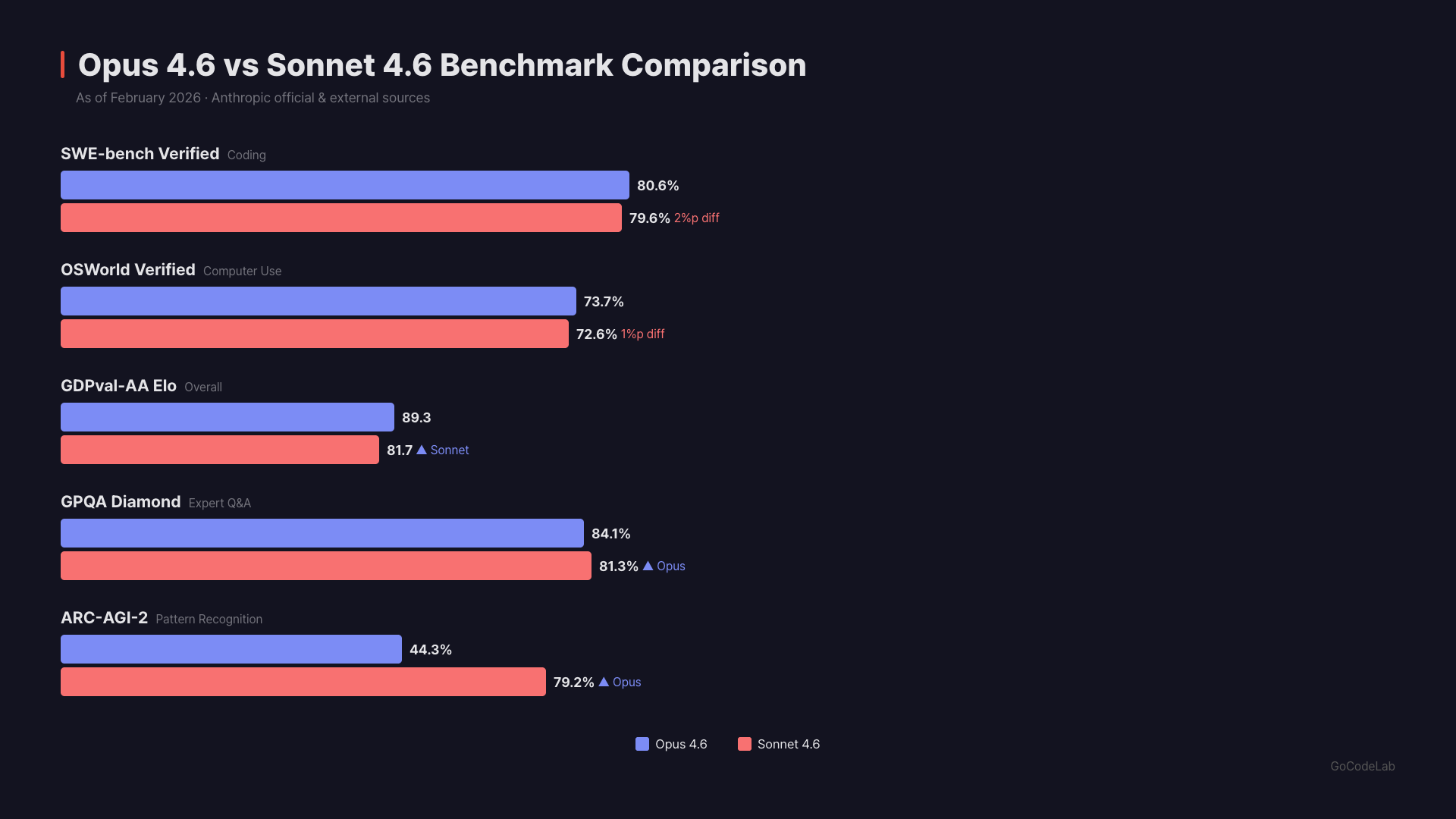
There’s an evaluation called GDPval-AA Elo. It’s a benchmark testing expert-level real-world office tasks — things like email writing, document organization, and report writing. Sonnet 4.6 scored 1,633 points, taking the overall #1 spot. Higher than Opus 4.6 (1,606 points). Higher than Gemini 3.1 Pro too. This means for general office tasks, Sonnet could actually be the better choice.Coding: Essentially Tied
On SWE-bench Verified, Opus 4.6 scored 80.8% and Sonnet 4.6 scored 79.6%. That’s only a 1.2%p difference. The smallest gap between Opus and Sonnet in Anthropic’s history. Computer use ability (OSWorld-Verified) is also nearly identical — Opus 72.7%, Sonnet 72.5%. When this feature first launched in October 2024, it was at 14.9%. In a year and a half, it climbed to 72.5%.Scientific Reasoning: Opus Clearly Leads
There’s a graduate-level science benchmark called GPQA Diamond. Opus 4.6 scored 91.3%, while Sonnet 4.6 scored 74.1%. That’s a 17%p gap — the largest difference between the two models.Advanced Reasoning: Opus Wins
On ARC-AGI-2 (pure logical reasoning), Opus scored 75.2% vs. Sonnet’s 58.3%. On Humanity’s Last Exam, Opus scored 26.3% vs. Sonnet’s 19.1%. When complex expert knowledge or multi-step reasoning is needed, Opus is more reliable.| Metric | Opus 4.6 | Sonnet 4.6 | Gap |
|---|---|---|---|
| Release Date | Feb 5 | Feb 17 | — |
| SWE-bench (Coding) | 80.8% | 79.6% | 1.2%p |
| OSWorld (Computer Use) | 72.7% | 72.5% | 0.2%p |
| GDPval-AA Elo (Office) | 1,606 | 1,633 | Sonnet leads |
| GPQA Diamond (Science) | 91.3% | 74.1% | 17.2%p |
| ARC-AGI-2 (Reasoning) | 75.2% | 58.3% | 16.9%p |
| Humanity’s Last Exam | 26.3% | 19.1% | 7.2%p |
| API Price (Input/Output) | $15 / $75 | $3 / $15 | 5x difference |
New Features
1M Token Context Window
Sonnet 4.6 supports a 1M token context window. It started in beta and later became generally available (GA). One million tokens is roughly the equivalent of 7-8 books. You can feed in entire long documents for analysis or have it read through a large codebase at once. According to Anthropic, accuracy is maintained across the full 1M window. Long-context retrieval performance has been improving with each generation.Extended Thinking
Sonnet 4.6 supports Extended Thinking. When it encounters a difficult problem, it thinks internally for longer before responding. Adaptive Thinking is also supported. Claude automatically adjusts its thinking time based on the difficulty of the request. Simple questions get immediate answers; complex problems get deeper thought.Prompt Caching
Reusing the same prompt can save up to 90% in costs. Cache read tokens cost 10% of the base input price. A 5-minute cache write costs 1.25x, and a 1-hour cache write costs 2x. For businesses with heavy API usage, that’s meaningful savings.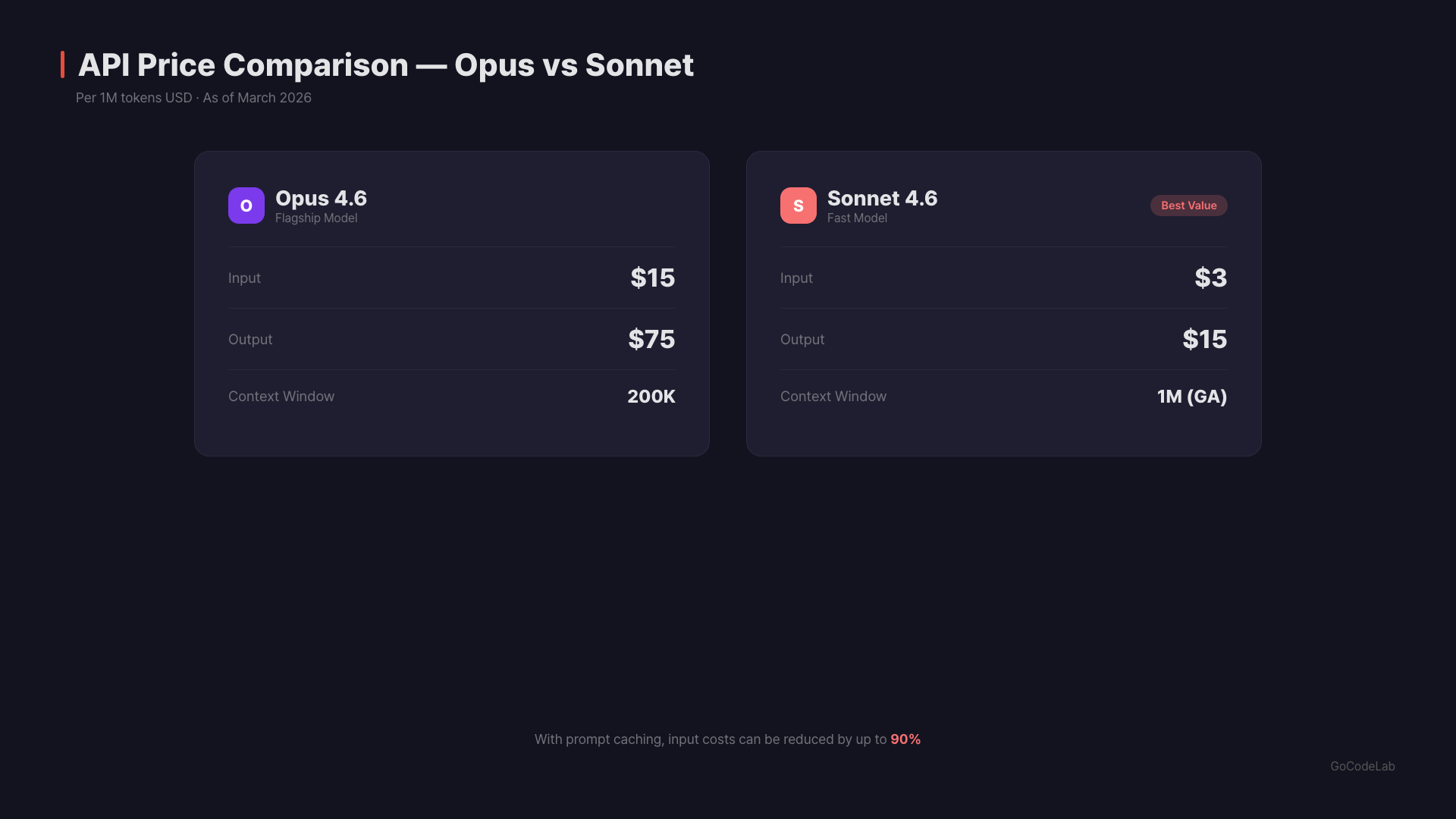
Safety Improvements
Sonnet 4.6’s safety evaluation results are noteworthy. Prompt injection defense has improved significantly compared to previous models. It’s reportedly on par with Opus 4.6. The safety research team described the model as “warm and honest, exhibiting strong safety behavior with no signs of serious misalignment.”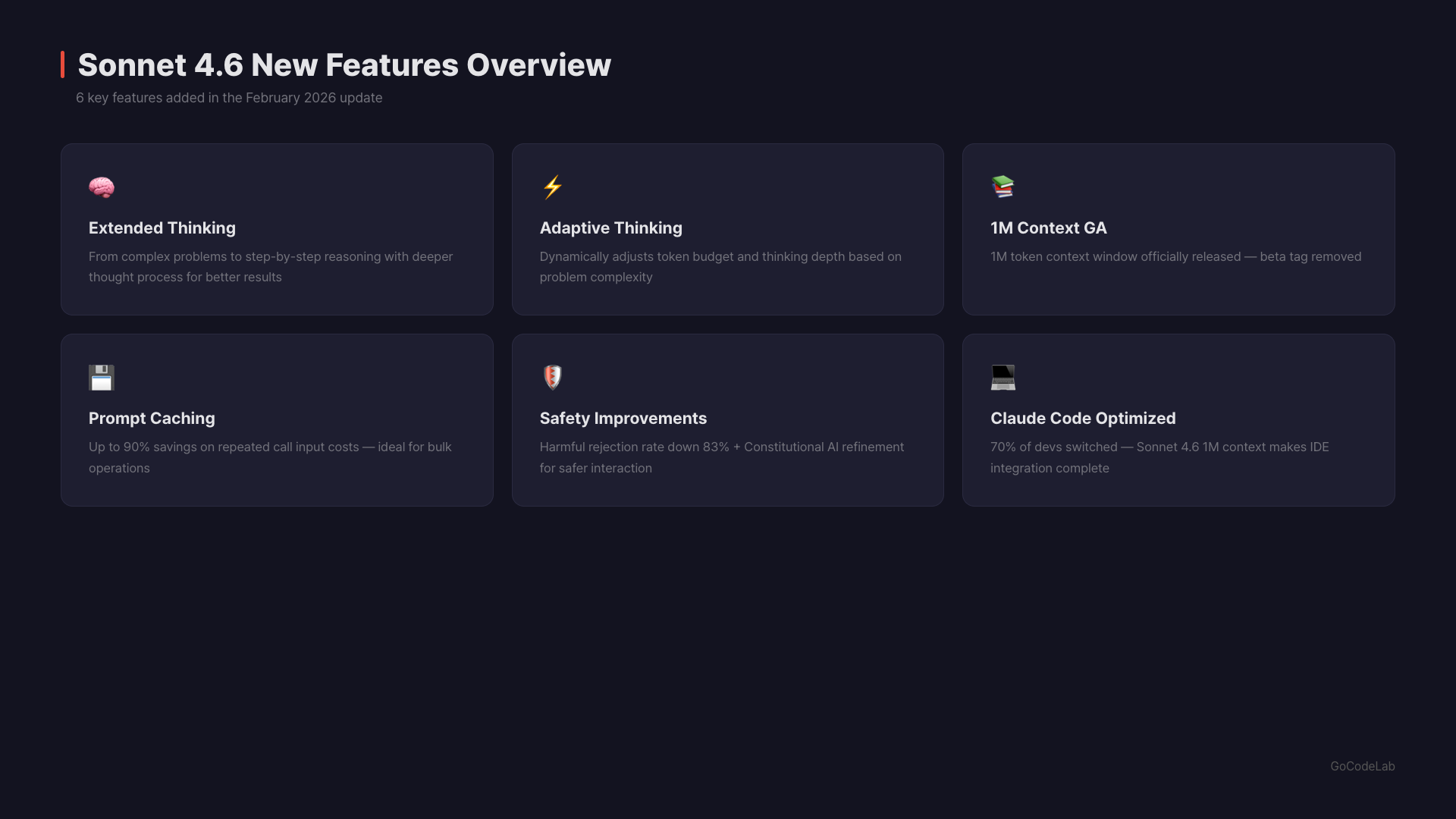
Developer Response in Claude Code
The Claude Code test results are impressive. Early users preferred Sonnet 4.6 over the previous Sonnet 4.5 in 70% of cases. Even compared to Opus 4.5 — the top model as of November 2025 — Sonnet 4.6 was chosen 59% of the time. Developers specifically highlighted two improvements: it reads context more thoroughly before modifying code, and it consolidates shared logic instead of duplicating it. These two things make a big difference in actual coding work. Not creating duplicate code everywhere is a pretty significant change.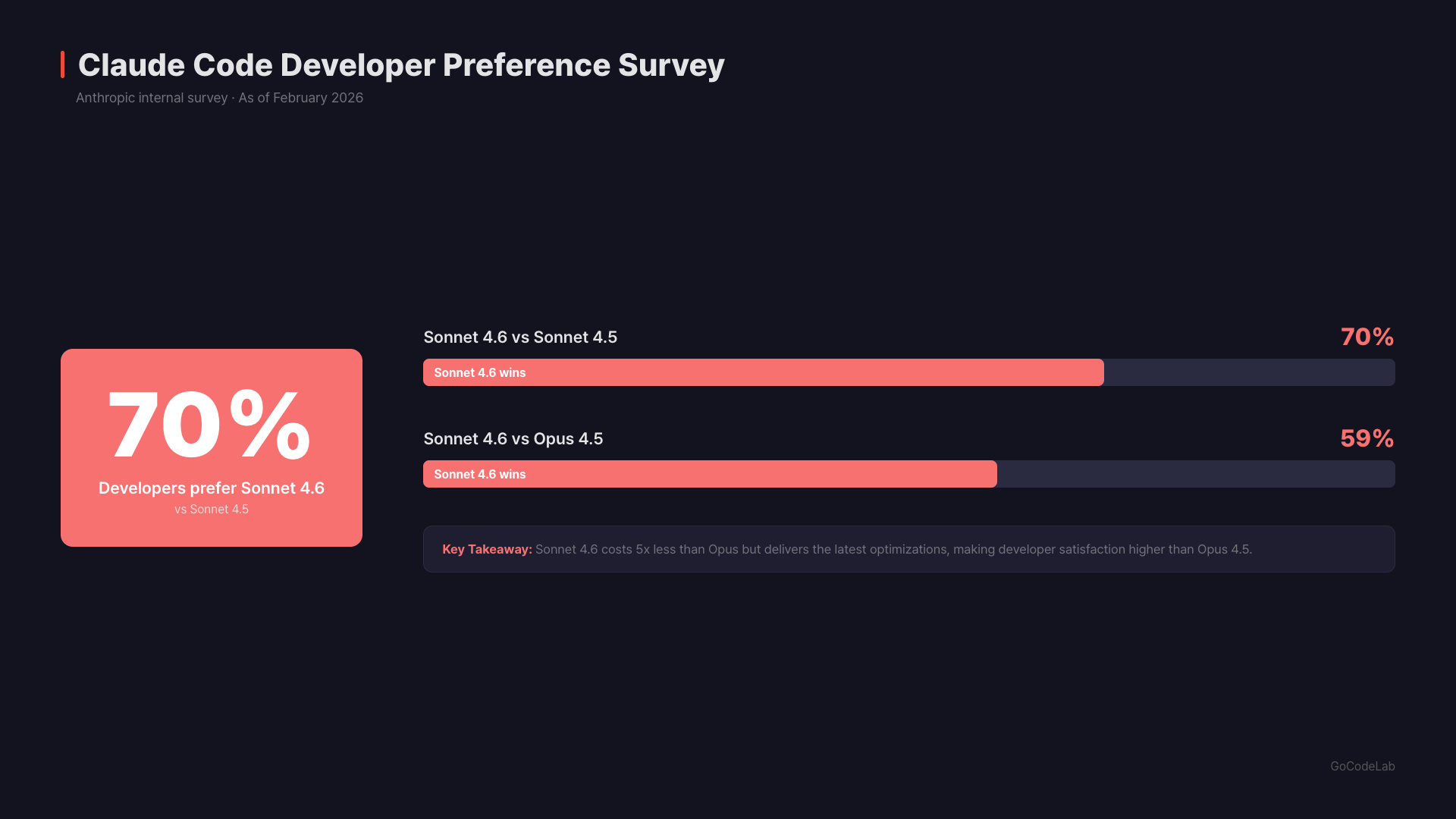
What’s It Like in Practice?
From hands-on experience, Sonnet 4.6 is noticeably faster than the previous version. The response speed was perceptibly improved. For general writing, emails, and summarization, Sonnet 4.6 was more than sufficient. Honestly, it was hard to tell it apart from Opus. For complex coding problems and multi-step reasoning chains, Opus still felt slightly more stable. But the gap wasn’t as big as it used to be. I also tried computer use. It showed human-level capability on tasks like navigating spreadsheets and filling out multi-step web forms. It handled switching between multiple browser tabs well too.Who Benefits Most from This Change?
Enterprise API users are the biggest beneficiaries. You can get nearly Opus-level performance in coding and office tasks at one-fifth the price. Combined with prompt caching, the cost savings are substantial. General users get access to both models with a Claude Pro subscription. Sonnet 4.6 is the default model even on the Free plan. Just pick whichever fits your needs. Developers should use Sonnet 4.6 as the default in Claude Code for efficiency. The coding performance gap is only 1.2%p. Save Opus for when you really need complex architecture design. Vertex AI / Azure users can plug it in right away. Sonnet 4.6 is officially supported on Google Vertex AI Model Garden and Microsoft Azure Foundry. One thing to note: the Agent Teams feature is exclusive to Opus 4.6. This feature lets multiple Claude instances work on a project simultaneously. If you need that, you’ll have to use Opus.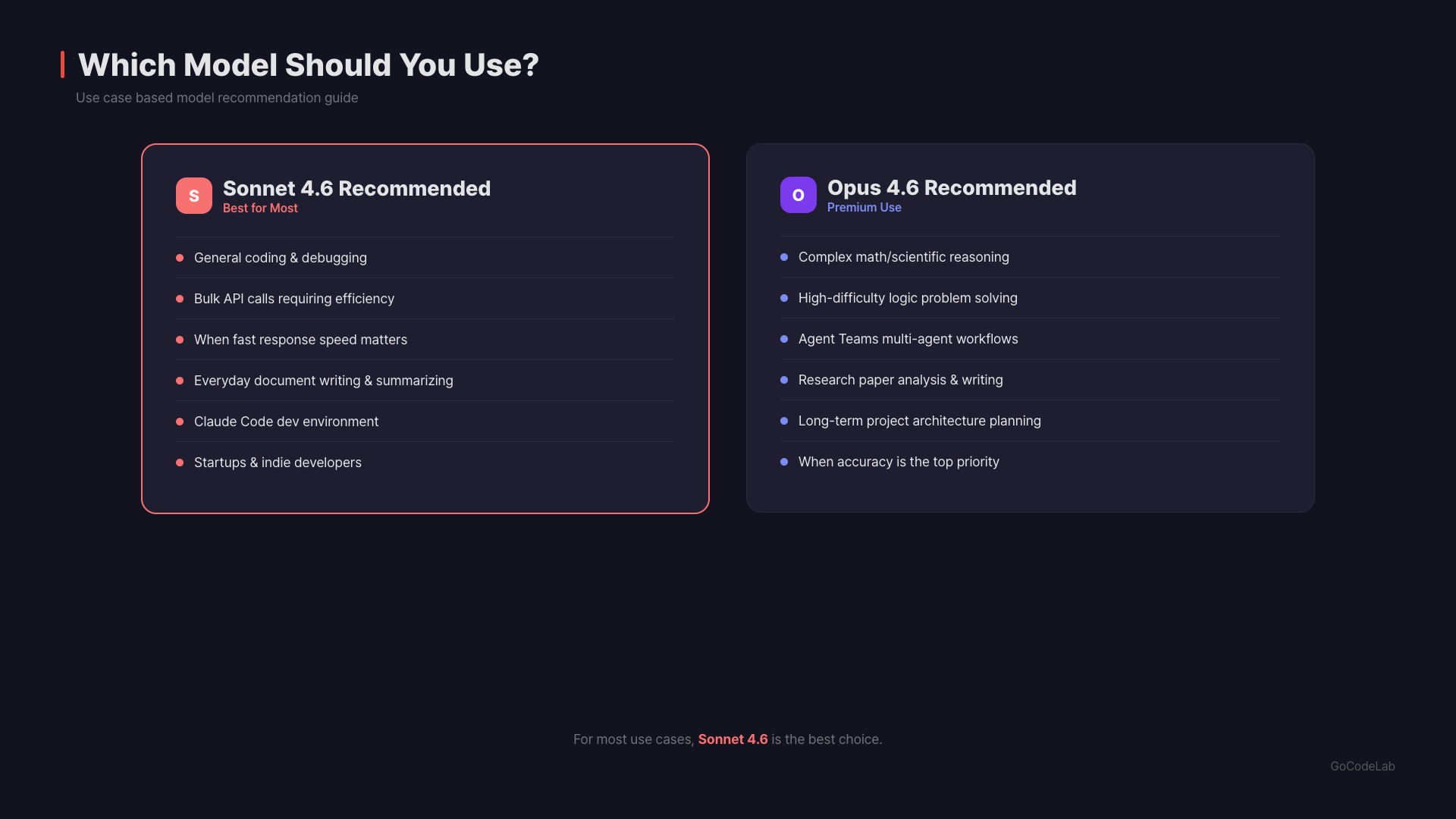
FAQ
Q. Is Sonnet 4.6 always better than Opus 4.6?
No. Sonnet leads in office task evaluations, but Opus leads by 17%p in scientific reasoning (GPQA Diamond). Opus is more reliable for advanced reasoning and specialized knowledge tasks. It depends on the nature of the work.Q. Can I use Sonnet 4.6 for free?
It’s the default model on Claude.ai’s Free plan. With a Pro subscription ($20/month), you get much higher usage limits and access to Opus as well.Q. Can I use Sonnet 4.6 in Claude Code?
Yes. It’s supported as the default model in Claude Code. In early developer testing, it was preferred over the previous Sonnet 4.5 70% of the time. It reportedly reads code context better and reduces logic duplication.Q. Is the 1M token context actually useful?
It’s useful when analyzing large codebases at once or summarizing entire long documents. According to Anthropic, accuracy is maintained across the full 1M window. That said, more token usage means higher costs, so using it with prompt caching is recommended.Q. How does it compare to Gemini 3.1 Pro?
On GDPval-AA, Sonnet 4.6 ranks higher than Gemini 3.1 Pro. However, in pure reasoning (ARC-AGI-2), Gemini 3.1 Pro scores 77.1% — higher than Claude Opus (75.2%). Gemini also has a larger 2M token context window. The best choice depends on the use case.Q. How big is the API price difference?
Sonnet 4.6 costs $3 input / $15 output per 1M tokens. Opus 4.6 costs $15 input / $75 output. That’s a 5x difference. With prompt caching, Sonnet’s cache reads drop to $0.30/1M tokens. For enterprises with heavy usage, this could mean tens of thousands of dollars in annual savings.Q. How do I use Extended Thinking?
Turn on Adaptive Thinking in the API and Claude decides automatically. Simple questions get immediate answers; complex problems get deeper thought. You can also manually set the Extended Thinking duration.Wrap-Up
Sonnet 4.6 has firmly shaken the notion that “expensive means better.” It’s #1 overall in office tasks. Only 1.2%p behind Opus in coding. Essentially tied in computer use. Plus it supports 1M context, Extended Thinking, and prompt caching. Of course, Opus clearly leads in scientific reasoning and advanced logic. A 17%p gap can’t be ignored. The Agent Teams feature is also Opus-exclusive. Ultimately, Sonnet 4.6 is the right choice for most tasks. Opus has become the tool you bring out only when you truly need complex reasoning.Try Claude Sonnet 4.6 yourself and see if it fits your workflow.
Official Sources
This article was written on March 13, 2026. Benchmark numbers are based on Anthropic’s official announcements. Actual experience may vary depending on your use case.
At GoCodeLab, we test AI tools hands-on and share honest reviews. Subscribe to the blog for more AI news.
Related posts: Gemini vs Claude vs ChatGPT Comparison · GPT-5.4 Key Changes · DeepSeek V4 Launch Review