Gemma 4 나왔어요 — Google이 진짜 오픈소스(Apache 2.0)로 바꾼 이유
Gemma 4 나왔어요 — Google이 진짜 오픈소스(Apache 2.0)로 바꾼 이유
2026년 4월 4일 · AI 소식
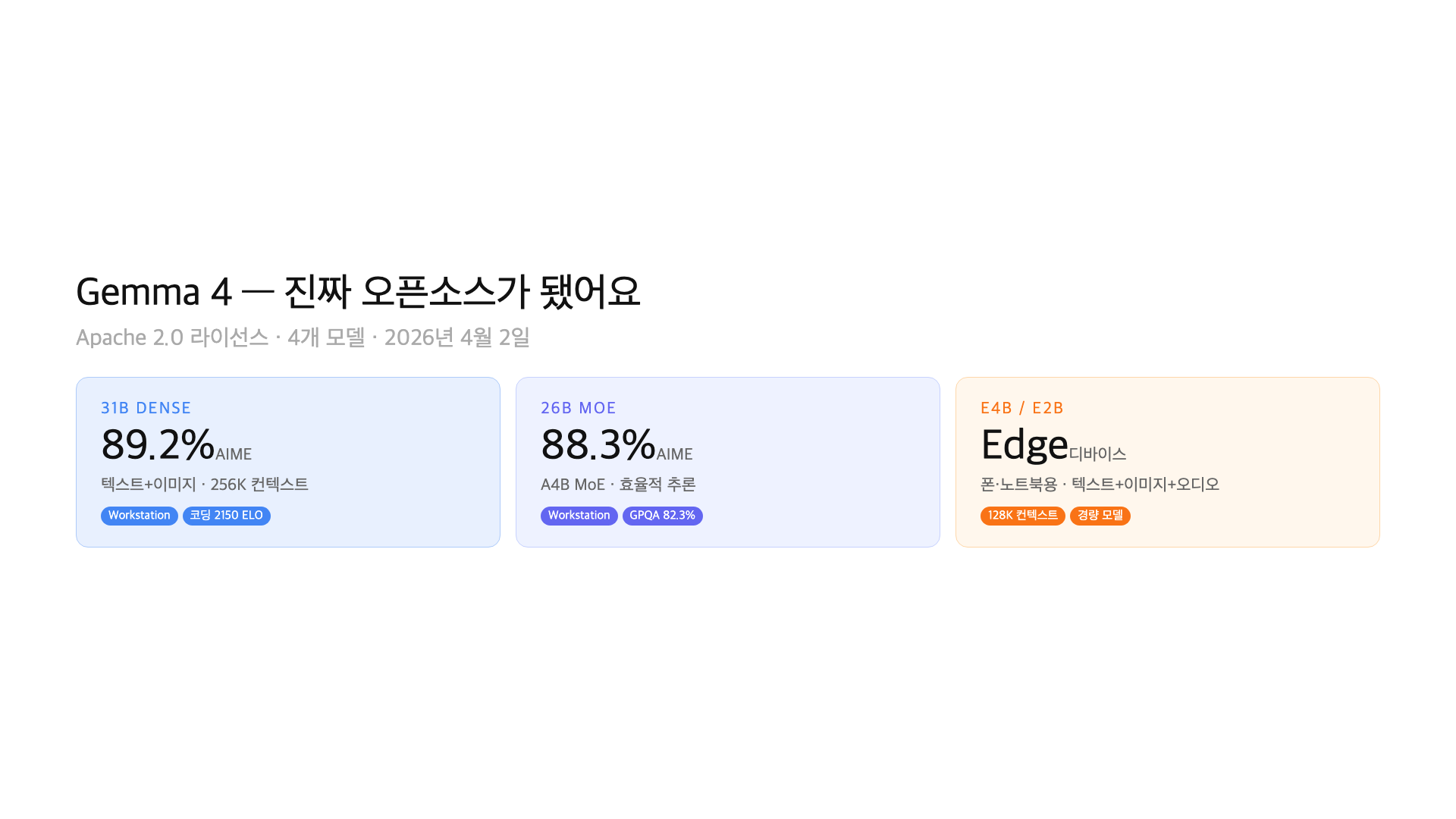
4월 2일, Google이 Gemma 4 모델 4종을 공개했어요. 31B Dense, 26B MoE, E4B, E2B — 서버용부터 노트북용까지 한 번에 나왔어요. 그런데 모델보다 더 큰 뉴스가 있어요. 라이선스가 Apache 2.0으로 바뀌었어요.
이전 Gemma 시리즈는 “Gemma Terms of Use”라는 커스텀 라이선스를 썼어요. 월간 활성 사용자(MAU) 제한도 있었고, 사용 조건도 복잡했어요. Apache 2.0은 그런 제한이 전혀 없어요. 상업적 사용, 수정, 재배포 전부 자유예요. Google이 오픈소스 생태계에서 한 발 물러나던 태도를 완전히 바꾼 거예요.
성능도 크게 올라왔어요. 31B 모델은 AIME 89.2%, GPQA Diamond 84.3%를 기록했어요. 같은 크기 오픈소스 모델 중 최상위 수준이에요. 하나씩 정리해볼게요.
– 모델 4종: 31B Dense + 26B MoE (서버/워크스테이션) + E4B + E2B (엣지/노트북)
– 라이선스: Apache 2.0 (MAU 제한 없음, 상업적 사용 완전 자유)
– 31B 벤치마크: AIME 89.2%, LiveCodeBench 80.0%, GPQA Diamond 84.3%
– 사용처: HuggingFace, Ollama, Google AI Studio에서 바로 이용 가능
Apache 2.0으로 바뀐 이유
Gemma 1부터 3까지는 “Gemma Terms of Use”라는 자체 라이선스를 썼어요. 겉으로는 오픈소스처럼 보이지만, 실제로는 제한이 있었어요. 대표적으로 MAU(월간 활성 사용자) 제한이 있었고, 특정 용도에서 사용이 제한됐어요.
Apache 2.0은 OSI(Open Source Initiative)가 공식 인정한 오픈소스 라이선스예요. 상업적 사용에 제한이 없어요. MAU 한도도 없어요. 수정해서 다시 배포해도 되고, 자기 제품에 넣어서 돈을 벌어도 돼요. Llama의 “Llama License”보다도 자유로운 조건이에요.
Google이 왜 바꿨을까요? 오픈소스 생태계에서 Llama(Meta), Qwen(Alibaba), Mistral에게 밀리고 있었거든요. 커스텀 라이선스 때문에 기업들이 Gemma를 꺼렸어요. “법무팀 검토가 필요하다”는 말이 나오면, 개발자들은 다른 모델을 골라요. Apache 2.0은 그 장벽을 없앤 거예요.

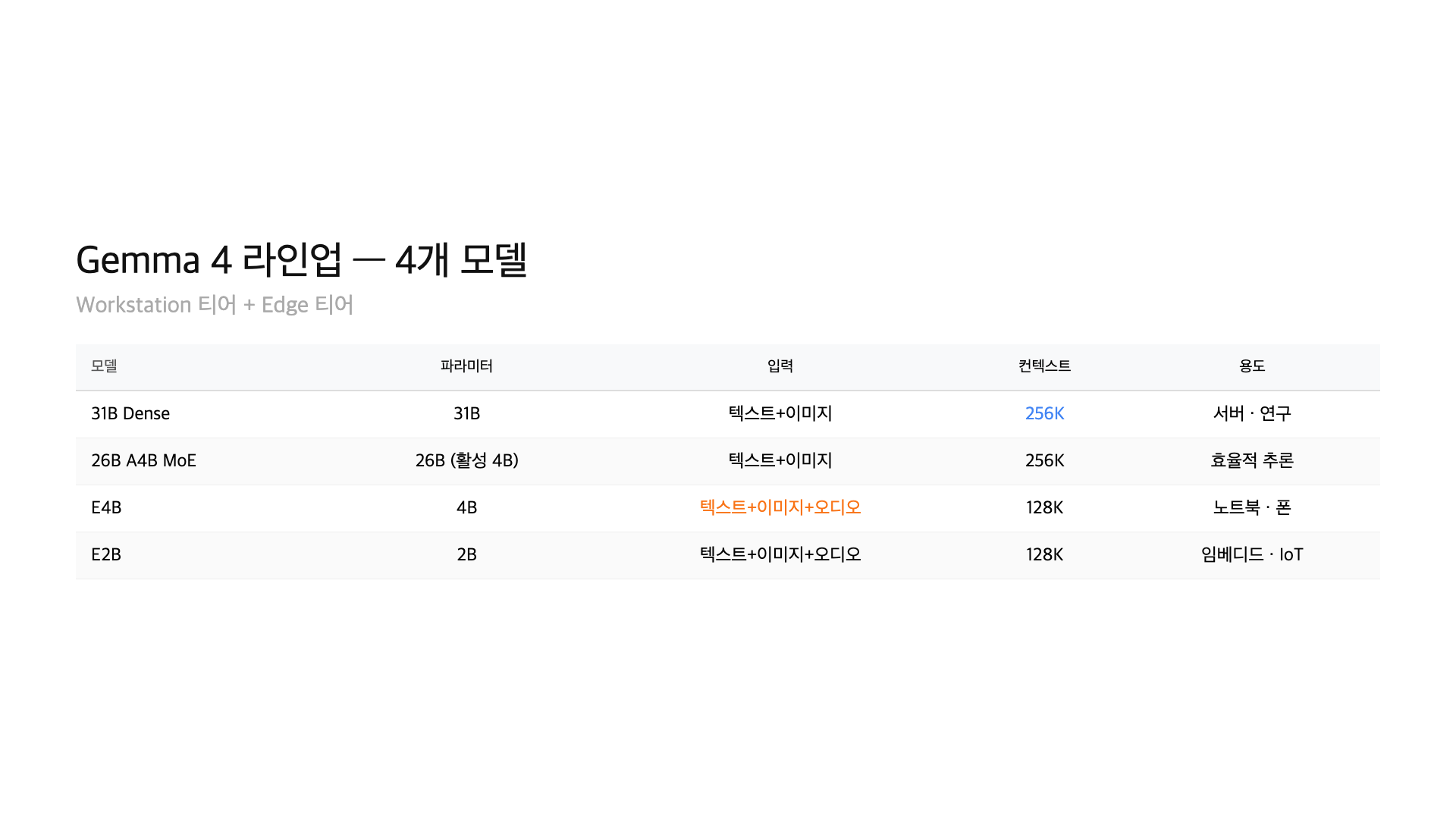
모델 4종 한눈에 보기
| 모델 | 파라미터 | 구조 | 컨텍스트 | 모달리티 | 용도 |
|---|---|---|---|---|---|
| 31B Dense | 31B | Dense | 256K | 텍스트+이미지 | 서버/워크스테이션 |
| 26B MoE | 26B (활성 3.8B) | MoE (A4B) | 256K | 텍스트+이미지 | 워크스테이션 |
| E4B | 4B | Dense | 128K | 텍스트+이미지+오디오 | 엣지/노트북 |
| E2B | 2B | Dense | 128K | 텍스트+이미지+오디오 | 엣지/모바일 |
큰 모델(31B, 26B)은 텍스트와 이미지를 처리해요. 작은 모델(E4B, E2B)은 오디오까지 지원해요. 재밌는 조합이에요. 엣지 디바이스에서 음성 입력까지 로컬로 처리하겠다는 의도가 보여요.
모든 모델이 Gemini 3 연구에서 파생됐어요. Google이 Gemini로 쌓은 연구 결과를 경량화해서 오픈소스로 풀어낸 거예요.
31B Dense — 서버용 최강자
31B Dense는 Gemma 4 라인업에서 가장 큰 모델이에요. 256K 컨텍스트 윈도우를 지원하고, 텍스트와 이미지 멀티모달 입력이 가능해요.
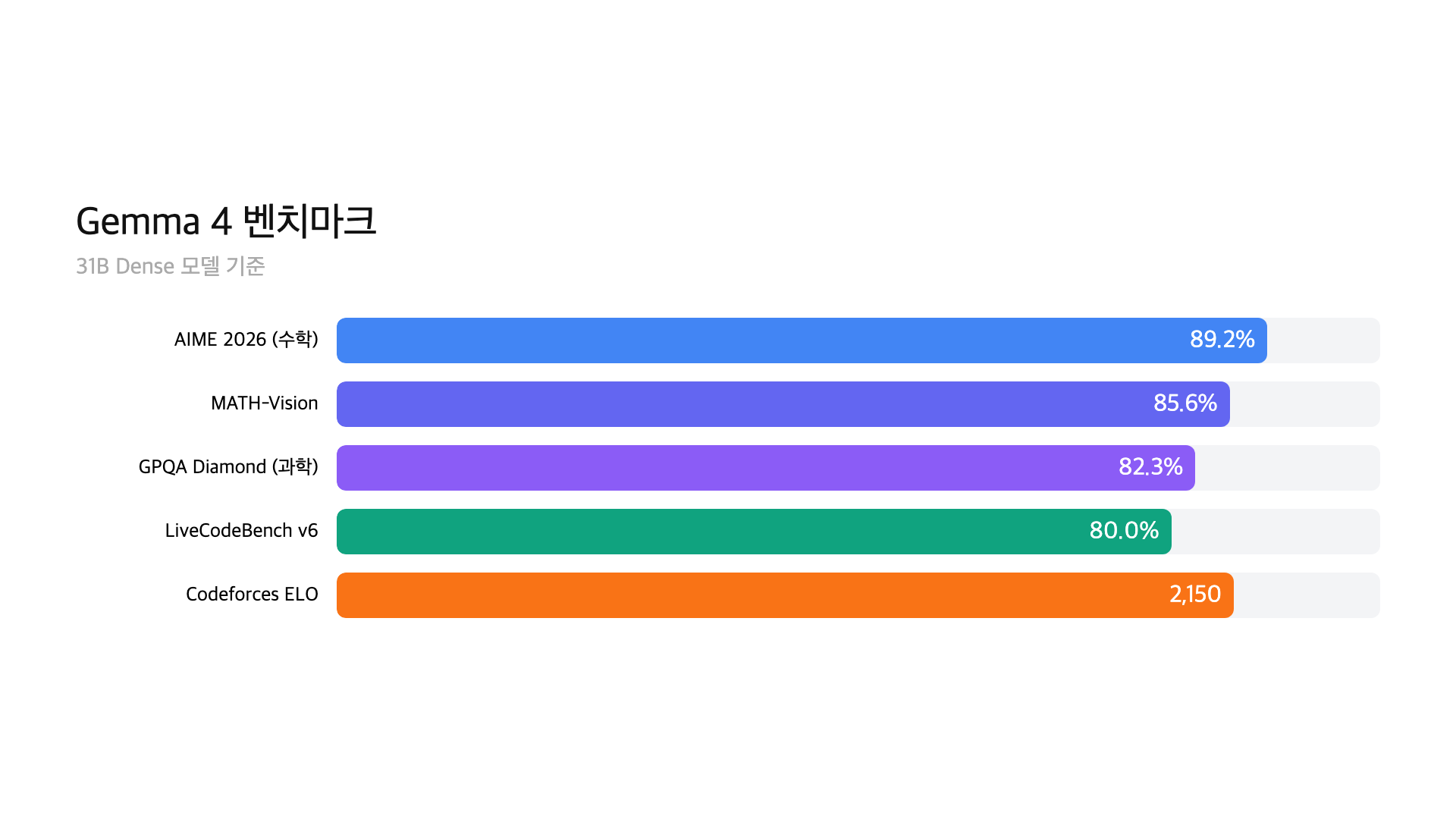
벤치마크 성능이 눈에 띄어요. AIME(수학 경시대회 문제)에서 89.2%, LiveCodeBench(코딩)에서 80.0%, GPQA Diamond(대학원 수준 과학)에서 84.3%를 기록했어요. Codeforces Elo는 2150이에요. 같은 크기 오픈소스 모델 중에서는 최상위 수준이에요.
이 정도면 1년 전 GPT-4 수준에 근접해요. 오픈소스 31B 모델이 이 성능을 내는 게 2026년 현실이에요. 서버에서 API 비용 없이 자체 AI를 운영하고 싶은 기업에게 강력한 선택지가 된 거예요.
26B MoE — 3.8B만 활성화돼요
MoE는 Mixture of Experts의 약자예요. 비유하면, 전문가 12명이 앉아 있는 사무실이에요. 질문이 들어오면 관련된 전문가 2~3명만 일어나서 답해요. 나머지는 가만히 있어요. 전체 인력은 12명이지만, 매번 일하는 건 2~3명이에요.
26B MoE 모델이 정확히 이 방식이에요. 전체 파라미터는 26B인데, 한 번에 활성화되는 파라미터는 3.8B뿐이에요. 그래서 속도가 빠르고, 메모리도 적게 써요. 실질적으로 4B 수준의 리소스로 26B 수준의 성능을 내는 거예요.
성능도 거의 31B Dense에 근접해요. AIME 88.3%, GPQA Diamond 82.3%예요. 31B와 1~2% 차이밖에 안 나요. 메모리가 제한된 워크스테이션이나 Mac에서 돌리려면, 이 모델이 가성비 면에서 가장 매력적이에요.
E4B와 E2B — 노트북에서 돌아가는 AI
E4B와 E2B는 엣지(Edge) 디바이스용 모델이에요. 노트북, 태블릿, 심지어 스마트폰에서도 돌아가도록 설계됐어요. “E”가 Edge를 뜻해요.
두 모델의 특징은 텍스트, 이미지, 오디오 세 가지 모달리티를 모두 지원한다는 거예요. 큰 모델(31B, 26B)은 텍스트와 이미지만 처리하는데, 작은 모델이 오히려 오디오까지 처리해요. 엣지 디바이스에서 음성 명령을 로컬로 처리하려는 Google의 의도가 반영된 거예요.
E4B는 Ollama 기준 약 9.6GB, E2B는 약 7.2GB예요. M1 16GB Mac이면 E4B를 무리 없이 돌릴 수 있어요. E2B는 8GB Mac에서도 돌아가요. 컨텍스트 윈도우는 128K로, 큰 모델의 256K보다 짧지만 대부분의 용도에는 충분해요.
벤치마크 비교 — 경쟁 모델과 얼마나 차이 나요?
| 벤치마크 | Gemma 4 31B | Gemma 4 26B MoE | Qwen 3.5 32B | Llama 4 Scout |
|---|---|---|---|---|
| AIME 2025 | 89.2% | 88.3% | 85.1% | 78.0% |
| LiveCodeBench | 80.0% | 76.5% | 74.2% | 70.8% |
| GPQA Diamond | 84.3% | 82.3% | 79.8% | 74.5% |
| Codeforces Elo | 2150 | 2020 | 1950 | 1800 |
31B Dense가 모든 벤치마크에서 1위예요. 26B MoE는 1~4% 뒤처지지만, 활성 파라미터가 3.8B밖에 안 되는 걸 감안하면 놀라운 수치예요. Qwen 3.5 32B보다 높고, Llama 4 Scout보다는 크게 앞서요.
단, 이건 같은 크기 오픈소스 모델끼리의 비교예요. Claude Opus 4.6이나 GPT-5.4 같은 대형 상용 모델과는 여전히 격차가 있어요. 그래도 오픈소스 31B가 이 성능을 내는 건 1년 전만 해도 상상하기 어려웠어요.
어디에서 쓸 수 있어요?
세 곳에서 바로 이용할 수 있어요. HuggingFace에서 모델 가중치를 다운로드할 수 있고, Ollama에서 한 줄 명령어로 로컬 실행이 가능해요. Google AI Studio에서는 브라우저에서 바로 테스트해볼 수 있어요.
ollama run gemma4 # E4B (기본, 9.6GB)
ollama run gemma4:e2b # E2B (7.2GB)
ollama run gemma4:26b # 26B MoE (18GB)
ollama run gemma4:31b # 31B Dense (20GB)
Apache 2.0 라이선스라서 기업에서 사전 법무 검토 없이 바로 도입할 수 있어요. 이전 Gemma Terms of Use 때는 “MAU 제한이 있나?”, “상업 사용이 가능한가?” 확인부터 해야 했는데, 이제 그런 과정이 필요 없어요.
파인튜닝도 가능해요. LoRA 기반 경량 파인튜닝이 주로 쓰이고, Apache 2.0이니까 파인튜닝된 모델을 재배포하는 것도 자유예요.
FAQ
Q. Gemma 4와 Gemini 3의 관계가 뭔가요?
Gemma 4는 Gemini 3 연구에서 파생된 오픈소스 모델이에요. Gemini 3는 Google의 상용 API 모델이고, Gemma 4는 그 연구 결과를 경량화해서 누구나 로컬에서 돌릴 수 있게 만든 거예요.
Q. Apache 2.0 라이선스가 왜 중요한가요?
상업적 사용에 제한이 없어요. 이전 Gemma Terms of Use는 MAU 제한이 있었고 법무 검토가 필요했어요. Apache 2.0은 수정, 재배포, 상업 서비스 전부 자유예요. Llama License보다도 조건이 좋아요.
Q. MoE 모델이 뭔가요?
Mixture of Experts(전문가 혼합)예요. 전문가 12명이 있는 사무실에서 질문마다 관련 전문가 2~3명만 응답하는 방식이에요. 전체 파라미터는 26B이지만 활성화되는 건 3.8B라서, 적은 메모리로 큰 모델 수준의 성능을 내요.
Q. 내 Mac에서 Gemma 4를 돌릴 수 있나요?
Ollama를 통해 가능해요. E2B는 8GB Mac, E4B는 16GB Mac, 26B MoE는 18GB 이상이 필요해요. 31B Dense는 64GB 이상을 추천해요. 자세한 설치법은 Gemma 4 로컬 실행 튜토리얼 글을 참고하세요.
Q. Gemma 4가 GPT-5나 Claude보다 나은가요?
같은 크기 오픈소스 중에서는 최상위예요. 하지만 GPT-5.4나 Claude Opus 4.6 같은 대형 상용 모델과는 여전히 성능 격차가 있어요. 다만 비용이 0원이라는 점에서, 용도에 따라 충분한 선택이 될 수 있어요.
마무리
Gemma 4의 핵심은 두 가지예요. 첫째, Apache 2.0으로 바뀌면서 진짜 오픈소스가 됐어요. 기업이 법무 검토 없이 바로 도입할 수 있게 된 건 생태계에 큰 변화예요. 둘째, 26B MoE가 3.8B 활성 파라미터로 31B에 근접한 성능을 내요. Mac에서 돌릴 수 있는 모델이 이 수준이 된 거예요.
오픈소스 AI 모델의 선택지가 계속 넓어지고 있어요. Llama, Qwen, Mistral에 이어 Gemma까지, 용도와 환경에 맞는 모델을 고를 수 있는 시대가 됐어요. Mac에서 직접 돌려보고 싶다면, Ollama 설치 튜토리얼도 확인해보세요.
이 글은 2026년 4월 4일에 작성됐어요. Google 공식 발표(2026년 4월 2일)와 HuggingFace 모델 카드를 기반으로 해요. 벤치마크 수치는 Google 자체 측정 결과이며, 독립 검증 결과와 다를 수 있어요.
GoCodeLab에서는 AI 모델을 직접 써보고 솔직하게 알려드려요. 다른 AI 소식이 궁금하면 블로그를 구독해주세요.