Mistral Small 4 — 119B Parameters Yet Faster, Plus Forge for Enterprise AI
Mistral AI unveiled Small 4 (119B MoE) and enterprise AI training platform Forge at NVIDIA GTC in March 2026. Check performance, pricing, and open-source details all in one place.
목차 (8)
March 23, 2026 · Trends
Mistral AI announced two things at once at NVIDIA GTC 2026 on March 17.
One is Small 4. Despite the “Small” in its name, it has 119B parameters. The other is Forge — a platform for enterprises to train AI with their own data.
Both point toward the same direction: “letting enterprises use AI directly.” Mistral feels like it’s attacking the market differently from OpenAI and Anthropic.
– Mistral Small 4: 119B parameter MoE model, only 6.5B used for inference
– Apache 2.0 open source — commercial use, modification, and redistribution all allowed
– 256K context window, text + image multimodal support
– Forge: Platform for enterprises to train dedicated AI with their own data
– Both unveiled at NVIDIA GTC on March 17, 2026

What Is Mistral Small 4?
119B Parameters, But Only 6.5B Active
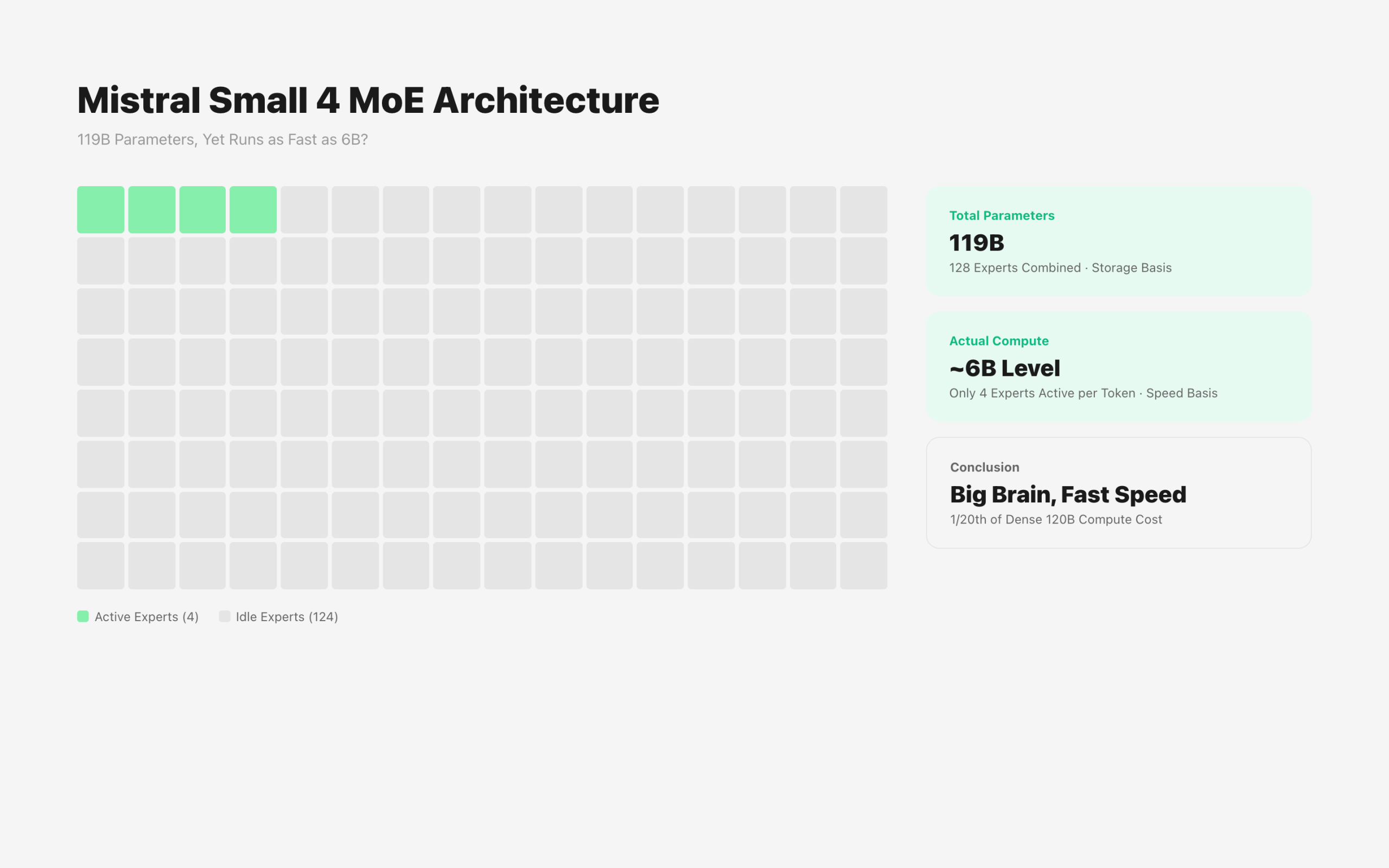
Small 4 uses a MoE (Mixture of Experts) architecture.
Total parameters are 119B, but only 6.5B are actually activated when processing a single token. The rest stay idle.
It selects and uses only 4 out of 128 experts. This is why inference speed stays fast despite the large parameter count.
Compared to the previous Small 3, throughput increased 3x. Latency dropped 40%.
Specs at a Glance
| Spec | Mistral Small 4 |
|---|---|
| Total Parameters | 119B |
| Active Parameters | 6.5B |
| Number of Experts | 128 (4 active per token) |
| Context Window | 256,000 tokens |
| Input Support | Text + Image |
| License | Apache 2.0 (Open Source) |
| Release Date | March 16, 2026 |
Benchmark Scores
| Benchmark | Mistral Small 4 | GPT-OSS 120B |
|---|---|---|
| GPQA Diamond | 71.2% | Similar |
| MMLU-Pro | 78.0% | Similar |
| AA LCR (Long-form Reasoning) | 0.72 | Similar |
| Output Length | 1,600 chars (shorter) | Longer |
Compared to GPT-OSS 120B, it matched or exceeded in every category. Notably, it delivers similar performance with 20-75% shorter output.
Compared to Qwen models, performance is similar, but output length is 3.5-4x shorter than Qwen.
What Does It Excel At?
Small 4 combines three capabilities into one.
First, fast general instruction processing. It inherits the Small series’ traditional strength.
Second, image understanding. Multimodal input is supported by default.
Third, coding. It scored higher than GPT-OSS 120B on LiveCodeBench.
Mistral describes it as “a model that unifies reasoning, vision, and coding.” Previously you needed different models for different tasks — now one model handles it all.
119B parameters but only 6B-level computation — here’s why / GoCodeLab
What Is Mistral Forge?
A Platform for Enterprises to Train AI Directly
Forge is a platform that lets enterprises build dedicated AI models with their own data.
This isn’t the approach of renting pre-built models via API like OpenAI or Anthropic. It’s about training from scratch with your own data, or fine-tuning existing models with company data.
Training Stages Forge Supports
Three stages are supported.
Pre-Training: Train a model from scratch with a company’s large-scale internal data. Create deeply specialized models for specific domains.
Post-Training: Refine an existing model for specific tasks and environments. Costs less time and money than training from scratch.
Reinforcement Learning: Align model behavior with company standards and evaluation metrics.
Agents Run the Training Directly
Forge’s unique aspect is agent support.
Like Mistral’s Vibe coding agent, AI can design and execute training experiments directly. Just give instructions in English and data pipelines, evaluation loops, and reinforcement learning run automatically.
Instead of humans configuring everything, it’s AI training AI.
Reducing Cloud Provider Dependency Is the Goal
Mistral says “enterprises should have strategic autonomy over their AI infrastructure.”
Using OpenAI or Anthropic APIs means being affected by those companies’ policies, pricing, and model changes. Forge aims to reduce that dependency.
It’s a structure where enterprises operate models within their own infrastructure and retain ownership.
How Does It Compare to Other Open-Source Models?
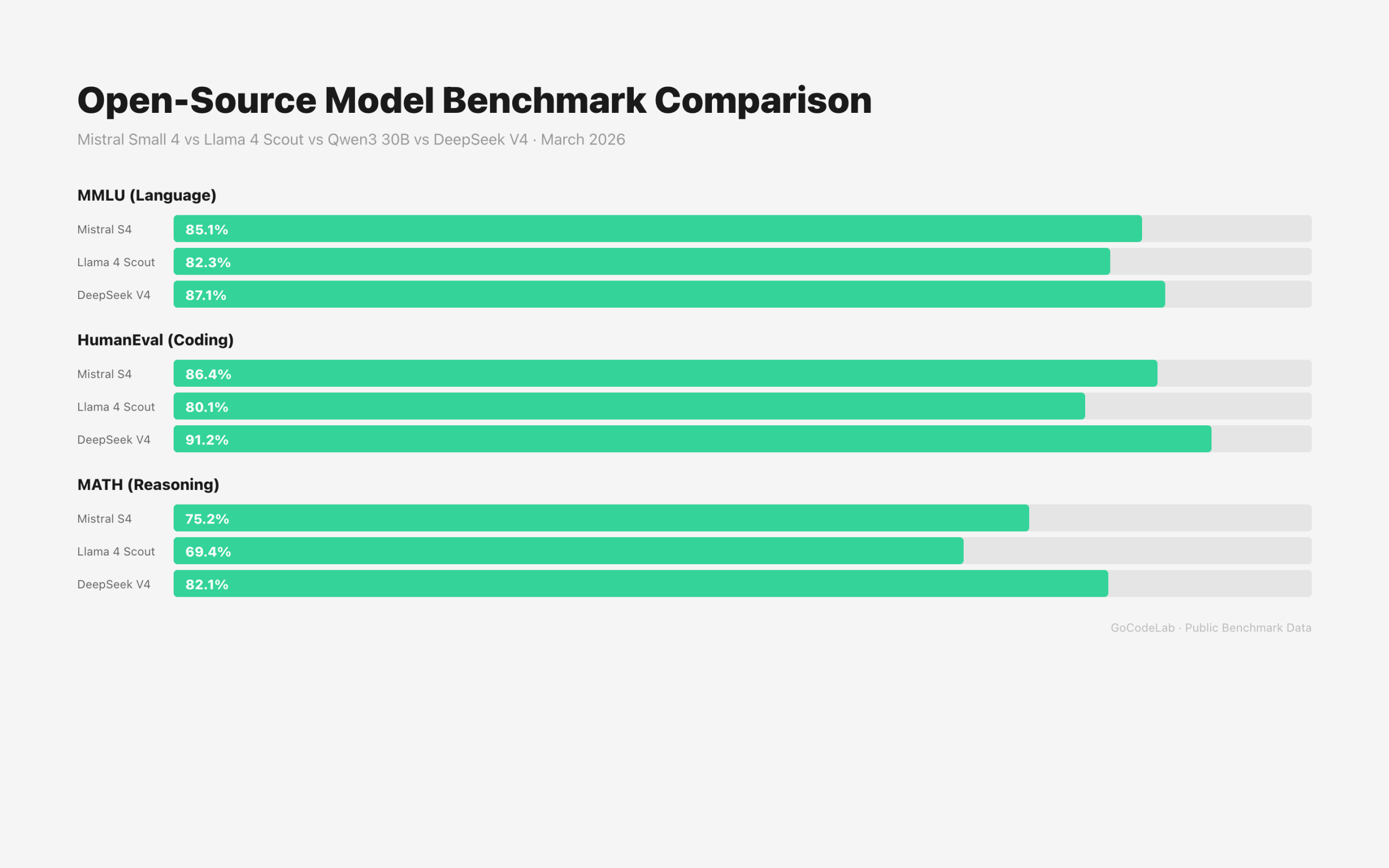
Small 4 isn’t alone in its league. As of March 2026, several open-source models occupy a similar position.
| Model | Total Params | Active Params | Context | License |
|---|---|---|---|---|
| Mistral Small 4 | 119B (MoE) | 6.5B | 256K | Apache 2.0 |
| Llama 4 Scout | 109B (MoE) | 17B | 10M | Llama Permissive |
| Qwen3 30B-A3B | 30B (MoE) | 3B | 128K | Apache 2.0 |
| DeepSeek V4 | 1T (MoE) | 37B | 1M | Open Source |
Mistral Small 4’s differentiator is having the lightest active parameter count at 6.5B. GPU requirements are relatively low. In contrast, Llama 4 Scout’s context window at 10 million tokens is overwhelming. Llama 4 is better for large-scale document processing, but Small 4 leads in fast inference speed and output efficiency.
In summary: want a fast, lightweight general-purpose open source model — go with Small 4. Need ultra-long context — Llama 4. Want to minimize coding costs — Qwen3 or DeepSeek V4.
Why Look at Small 4 + Forge Together
Small 4 is fully open source under the Apache 2.0 license.
You can download and use the model for free. When paired with Forge, you can build company-specific AI based on Small 4.
It’s an alternative that reduces the cost and dependency of using commercial models like GPT or Claude via API.
Industries where external data transfer is sensitive — like healthcare, finance, and legal — are showing particular interest.
Where Can You Use It?
Small 4 is available via API on Mistral AI’s official site (mistral.ai) and NVIDIA NIM.
Since it’s open source, you can also download model weights directly from Hugging Face.
Recommended hardware: 4x NVIDIA HGX H100 or 2x DGX B200. It can also run in on-premises environments.
Forge requires a separate inquiry. It’s an enterprise contract model. Mistral engineers are directly dispatched to customer sites to assist from data preparation onward.
How Much Does Forge Actually Cost?
When you hear “enterprise AI fine-tuning platform,” the first thought is “must be expensive.” Here’s a comparison with OpenAI’s fine-tuning service.
Compared to OpenAI Fine-Tuning
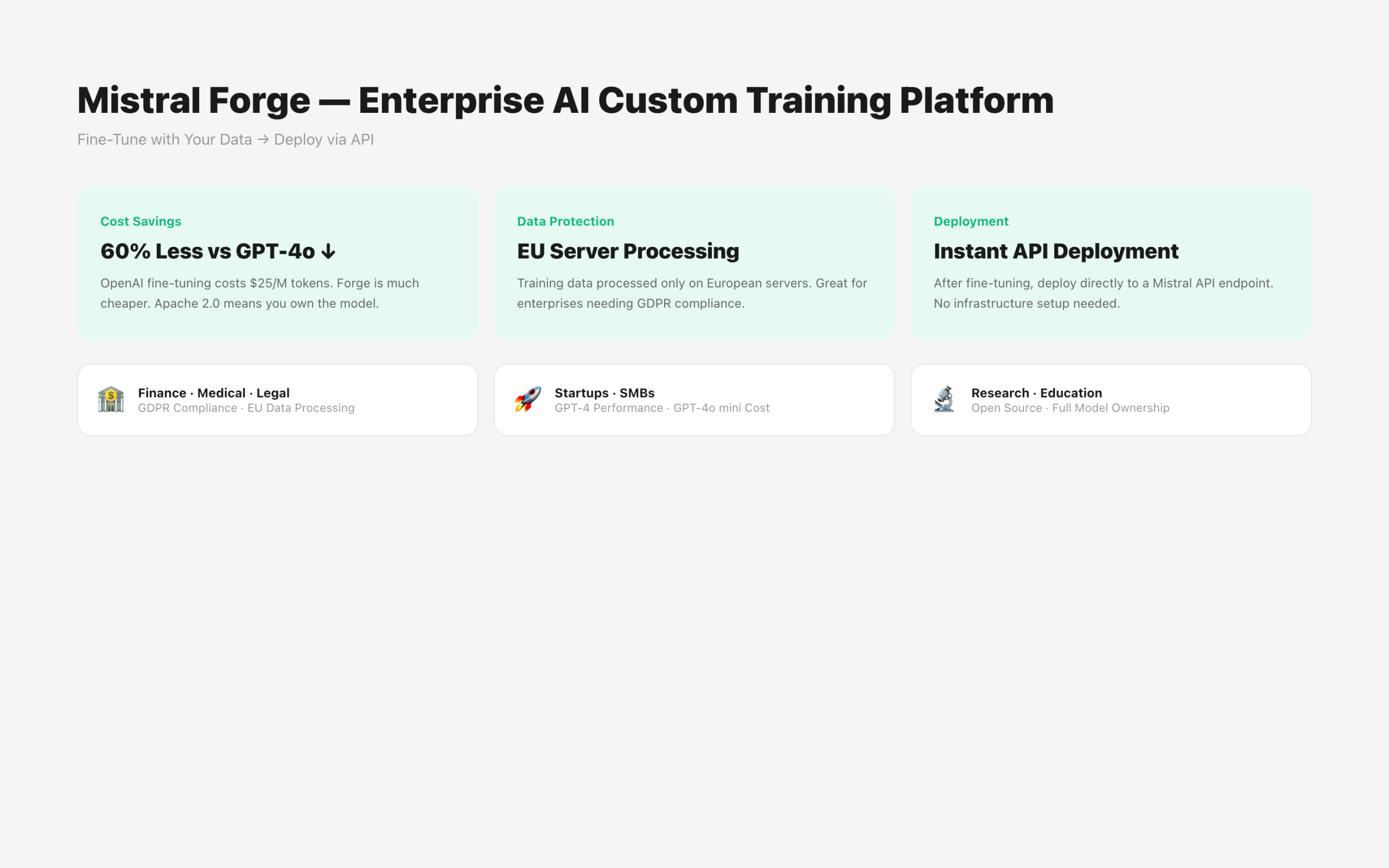
OpenAI GPT-4o fine-tuning costs $25/1M tokens for training and $1.25/1K tokens for inference. Forge’s exact pricing hasn’t been disclosed, but Mistral AI officially stated it’s “approximately 40-60% cheaper than OpenAI fine-tuning.”
Beyond cost, there’s a more important difference. Models fine-tuned through Forge carry the Apache 2.0 license — you own the model. OpenAI fine-tuned models are locked to OpenAI’s servers.
Which Enterprises Is It For?
Finance, Healthcare, Legal: There’s a guarantee that data is processed only on EU servers. Especially advantageous for European companies needing GDPR compliance.
Startups and SMBs: You can build a custom model with GPT-4 level performance at GPT-4o mini level costs. Start with pay-as-you-go, no upfront costs.
Existing OpenAI Customers: Forge is still in closed beta. Access is being granted sequentially after waitlist registration.
Try Mistral Small 4 via API first, then consider Forge when fine-tuning needs arise. The API price is very affordable at $0.10/M input, so you can test extensively first.
FAQ
Q. Is Mistral Small 4 really open source?
Yes. It was released under the Apache 2.0 license. Commercial use, modification, and redistribution are all allowed. You can download the model weights and run them on your own servers.
Q. 119B isn’t small — why call it “Small”?
Mistral’s model naming is relative. Small is the lightweight position compared to Large and Medium. Since active parameters used for actual inference are only 6.5B, it’s “Small” in terms of operational cost and speed.
Q. How is Forge different from fine-tuning?
Fine-tuning adjusts some weights of an existing model with additional data. Forge has a broader scope. It includes training new models from scratch, and integrated management of data pipelines, evaluation, and reinforcement learning.
Q. Can Mistral Small 4 replace GPT-4o?
Performance-wise, it’s definitely competitive. It’s particularly strong in coding and long document summarization. However, unlike OpenAI’s ecosystem (plugins, chatbot UI, etc.), you’ll need to set things up yourself. It’s a better fit for teams that want self-deployment over API usage.
Q. How is the multilingual performance?
Official benchmarks don’t include non-European language categories. Mistral models traditionally excel in European languages, and multilingual performance has been rated lower than GPT or Qwen series for some languages. If non-European language tasks are your primary use case, testing beforehand is recommended.
Wrap-Up
With this announcement, Mistral made its direction crystal clear.
Not “AI you rent via API” — but “AI that enterprises build and own themselves.”
Small 4 is fully open source, and Forge is the tool for enterprises to build their own models from scratch. Combine them, and you get a path to running AI without external dependencies.
Even if you’re not a large company, if you have your own data, this is a trend worth watching.
Want to try Mistral Small 4 yourself? Get an API key at mistral.ai.
This article was written on March 23, 2026. Detailed specs and pricing for Mistral Small 4 and Forge may change after official updates. Check mistral.ai for the latest information.
At GoCodeLab, we try AI tools hands-on and share honest reviews. Subscribe to the blog for more AI news.
Related: NVIDIA NemoClaw — The Enterprise Version of OpenClaw · DeepSeek V4 — Is It Really a GPT-5 Rival? · What Is Agentic AI? — 2026’s Hottest Keyword