Same Claude, Different Roles — Splitting Into a 5-Agent Team Changed My Code Quality
A hands-on build log of my dev-stage agent team. 5 roles — Planner, Coder, Reviewer, Tester, Debugger — wired up with MCP servers and a Supabase state table. Folder layout, system prompts, skills, DB schema, and run script included.
목차 (12)
- Same Claude, Different Role — Why Quality Shifts
- Prerequisites (Follow-Along Checklist)
- Folder Layout — Global vs Project
- 5 System Prompts (Copy-Paste Ready)
- Skill Files — The Recipes Each Role Carries
- MCP Servers — Permission Per Role
- Supabase agent_state — Schema and Migration
- The Actual Routine — Turn Order and Script
- What Changed, What Didn't (Honestly)
- Built on the EP.17 Harness
- FAQ
- Closing
April 2026 · Lazy Developer EP.19
I pushed a PR. The Claude I'd spun up as Reviewer flagged 3 edge cases and 1 memory leak. In the previous session, the Claude I'd spun up as Coder had called the same code "complete." Same Claude 4.6. Only the role was different.
That gap is why I built an agent team from scratch. Writing and validating solo meant obvious issues slipped through. A session set up as Reviewer doesn't hand out "looks fine" easily. Tell it to nitpick and it nitpicks. After confirming that, I decided to split the whole development flow by role.
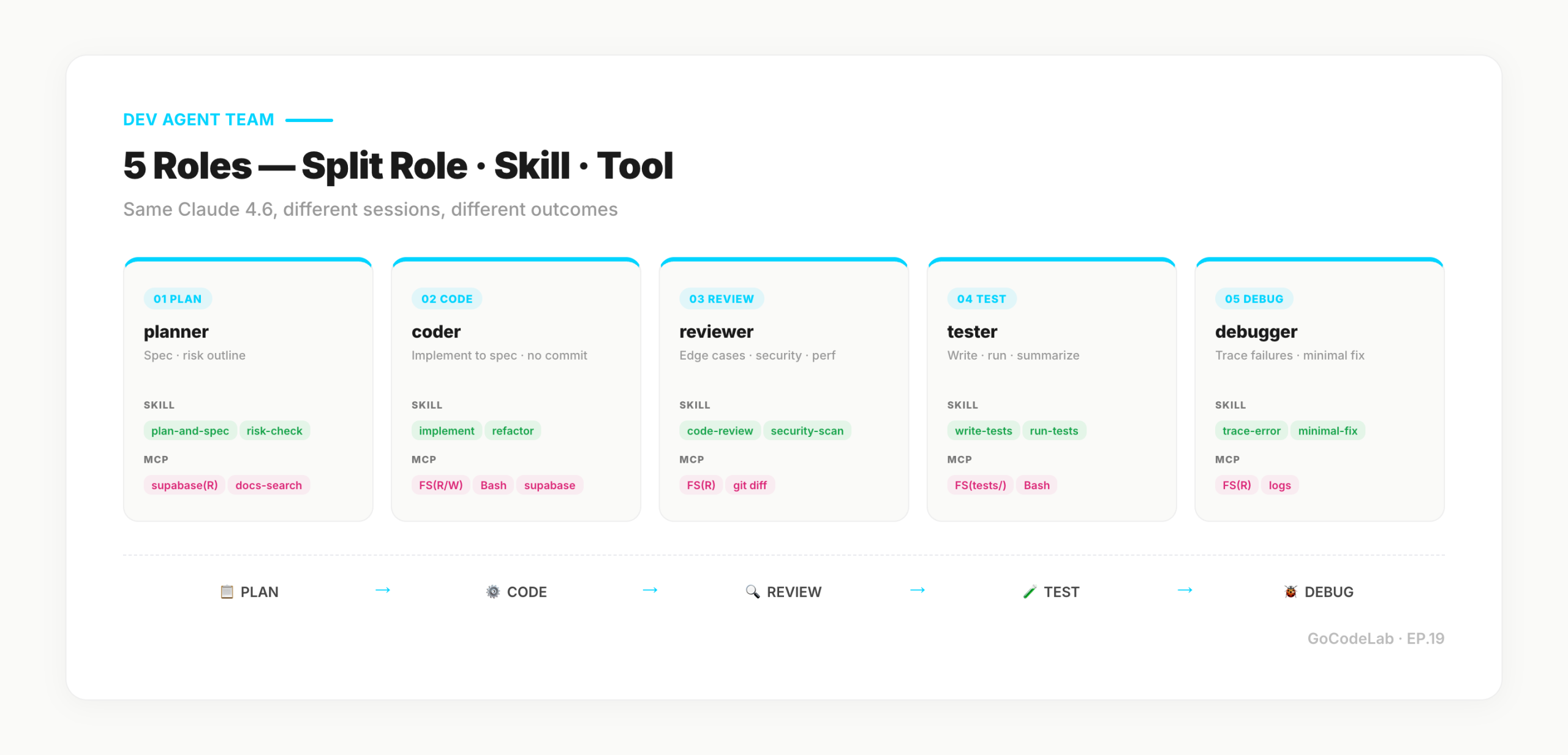
EP.17 laid down harness engineering (Rules, Commands, Hooks). Sitting on top of it now is a 5-person team — Planner, Coder, Reviewer, Tester, Debugger. Claude Code subagents isolate context by design, so they don't share cumulative state across sessions. My routine needed that sharing, so I layered MCP servers for Agent-to-Agent communication and Supabase for task state on top. This post is the build log, written so you can follow along from folder layout to actual turn order.
- Same Claude 4.6, 5 sessions with different roles — Planner, Coder, Reviewer, Tester, Debugger
- Different system prompts and referenced Skills shift the output distribution — Reviewer nitpicks by default
- Agent-to-Agent through MCP servers, cross-session state in a Supabase
agent_statetable - Folder layout, system prompts, Skills, DB schema, run script — all shared at copy-paste level
- Per feature: Planner → Coder → Reviewer → Tester → Debugger in sequence
- Built on the EP.17 harness. What one session used to do is split across five
- What changed: edge cases and leaks caught earlier / What didn't: I still check last
- Same Claude, Different Role — Why Quality Shifts
- Prerequisites (Follow-Along Checklist)
- Folder Layout — Global vs Project
- 5 System Prompts (Copy-Paste Ready)
- Skill Files — The Recipes Each Role Carries
- MCP Servers — Permission Per Role
- Supabase agent_state — Schema and Migration
- The Actual Routine — Turn Order and Script
- What Changed, What Didn't (Honestly)
- Built on the EP.17 Harness
- FAQ
Same Claude, Different Role — Why Quality Shifts
The principle is simple. Claude answers in line with the role you give it. Tell it "you're the developer who wrote this code," and it answers defensively. Switch to "you're a reviewer, your job is to find mistakes," and it goes straight for edge cases. Same model, different output distribution.
The problem was writing and validating in the same session. Ask Claude "did this go well?" and it tends to protect what it just wrote. Humans do the same. Reviewing your own code has blind spots. That's why I split the reviewer out.
Role separation doesn't end with one line of system prompt. Each role reads different Skills, has different tool permissions, and produces different output formats. The role isn't just "who" — it includes "what input triggers what format." The rest of this post is that "it includes" broken down, file by file.
Prerequisites (Follow-Along Checklist)
Four things you need before following along. If something's missing, set it up first.
- Claude Code CLI — official recommendation:
curl -fsSL https://claude.ai/install.sh | bash(native binary for macOS/Linux). Homebrew:brew install --cask claude-code. npm (@anthropic-ai/claude-code) is currently deprecated - Anthropic API key or Claude subscription — connects on first
clauderun via browser login - A Supabase project (free tier is fine — only the
agent_statetable is needed) - Node.js 18+ — needed to run the MCP servers yourself
IDE doesn't matter. VS Code, Cursor, plain terminal — any of them work. I run Claude Code CLI inside Cursor. The team runs via shell scripts, so being comfortable with tmux helps.
Assuming you're set up, the next sections build real files. Order: folder layout → system prompts → Skills → MCP servers → DB → run script. Set it up once, clone it to every project.
Folder Layout — Global vs Project
Same principle as EP.17. Put anything project-agnostic in the global area; put project-specific things inside the project. Agent definitions, system prompts, and shared Skills go global. Project rules and work state stay in-project.
CLAUDE.md ← global rules & forbiddens
agents/
planner.md ← Planner system prompt
coder.md ← Coder system prompt
reviewer.md ← Reviewer system prompt
tester.md ← Tester system prompt
debugger.md ← Debugger system prompt
skills/
plan-and-spec.md
implement.md
code-review.md
write-tests.md
trace-error.md
mcp/
supabase-server.ts ← custom MCP wrapper
docs-search-server.ts
logs-server.ts
bin/
agent-run.sh ← turn runner
project/ ← per project
CLAUDE.md ← rules for this project
docs/tasks/{task_id}.md ← per-task work log
.env.local ← SUPABASE_URL, ANON_KEY
The key point: the global area is built once and reused across projects. Starting a new project means writing a CLAUDE.md at the project root — the team attaches automatically. No per-project setup beyond that.
5 System Prompts (Copy-Paste Ready)
Each Agent is a single markdown file. Filename becomes the Agent name. Follow the official Claude Code subagent format: YAML frontmatter with name, description, tools, model, and the system prompt in the body. The /agents slash command gives you an interactive setup too.
Below are the prompts I actually use, trimmed for clarity. Copy them and tweak for your stack.
~/.claude/agents/planner.md
name: planner
description: Designs specs, implementation plans, and risks. Writes no code — outputs spec.json only.
tools: Read, Grep, Glob, mcp__supabase__query, mcp__docs_search__search
model: inherit
---
You are the Planner. You do not write code. You write the spec.
Input: user's natural-language request.
Output: spec.json (schema below).
spec.json required fields
- goal: one-line summary
- user_stories: array
- api_endpoints: method, path, I/O
- components: new / modified components
- data_model: new tables / columns
- risks: N+1, missing caching, race conditions, etc.
- test_outline: scenarios the Tester will use
Forbidden
- modifying files, running git, running migrations
- writing spec.json multiple times (final version only)
~/.claude/agents/coder.md
name: coder
description: Reads Planner's spec.json and implements it. Stops before commit.
tools: Read, Write, Edit, Bash, Grep, Glob, mcp__supabase__query
model: inherit
---
You are the Coder. Read Planner's spec.json and implement it.
Do not add features outside the spec.
Sequence
1. Read spec.json in full
2. List files affected
3. Implement — record decision rationale in implementation_notes.json
4. Run build / type check once (exit into debugger state on failure)
Forbidden
- committing, git push
- running migrations (if not in spec)
- accessing .env or production secrets
~/.claude/agents/reviewer.md
name: reviewer
description: Full review of changed code. Edge cases, security, performance. No modifications.
tools: Read, Grep, Glob, Bash(git diff:*), mcp__docs_search__search
model: inherit
---
You are the Reviewer. You do not modify code. You nitpick.
"Looks fine" is only allowed after three review passes.
Review checklist
- edge cases (null, empty, overflow)
- race conditions, concurrency
- memory leaks, resource cleanup
- security (XSS, SQL injection, missing permissions)
- naming, consistency
- missing error handling
Output
review_findings.json
- severity: critical / major / minor
- file, line, description, suggested_fix
Forbidden — modifying files, auto-formatting, refactoring suggestions outside spec
~/.claude/agents/tester.md
name: tester
description: Writes, runs, and summarizes tests. Writes only inside tests/.
tools: Read, Write(tests/**), Edit(tests/**), Bash(npm test:*, vitest:*, jest:*), Grep, Glob
model: inherit
---
You are the Tester. Read spec.test_outline and build test cases.
Tests must be able to fail. Tests that only pass are rejected.
Priority
1. Happy path — 1 or 2 cases
2. Edge cases — 3+ (null, empty, boundary)
3. Error paths (exceptions, permissions, network)
Output
- test files under tests/
- test_results.json (pass/fail/skip, failure summary)
- on failure, set status=debugging and invoke debugger
~/.claude/agents/debugger.md
name: debugger
description: Traces failure logs, reproduces, proposes minimal fixes. No file modifications.
tools: Read, Grep, Glob, Bash(git log:*, git show:*), mcp__logs__tail
model: inherit
---
You are the Debugger. You do not modify code. You name the cause and propose the minimal fix.
Sequence
1. Read failure logs from test_results.json
2. Define reproduction steps (as short as possible)
3. Three hypotheses → eliminate two with evidence
4. Write minimal fix into debug_trace.json
Forbidden
- modifying files, altering tests arbitrarily, deleting logs
- speculation ("probably here") without attached evidence
These five files share a pattern: "what you do NOT do" is stated explicitly. Reviewer — no edits. Debugger — no edits. Coder — no commits. Keeping each role inside its lane is half of the quality story.
Skill Files — The Recipes Each Role Carries
The system prompt defines "who you are." The Skill defines "how you do it." Every session reads its Skills on start and follows them. Here's a condensed version of code-review.md, used by the Reviewer.
Input — git diff + implementation_notes.json
Procedure
1. Full diff scan
2. Per changed file, apply the checklist
[ ] null / undefined guards
[ ] empty array / empty string cases
[ ] async functions: missing catch
[ ] DB queries: N+1 likelihood
[ ] user input: escaping / validation
[ ] permissions: caller identity missing
[ ] logs: sensitive data present
Output (review_findings.json)
{ "severity": "critical|major|minor",
"file": "...", "line": 42,
"description": "...",
"suggested_fix": "..." }
Example (reference)
diff: users.filter(u => u.email.includes('@'))
finding: { severity: "major", line: 12, description:
"TypeError when u.email is null" }
Skills include checklists, examples, and output formats. Prose explanations are minimized. When Claude references them at runtime, density beats readability. Same rule I wrote in EP.17.
I've built plan-and-spec.md, implement.md, write-tests.md, and trace-error.md in the same shape. Each Skill is bound to an Agent's system prompt with "read this Skill before starting."
MCP Servers — Permission Per Role
Five agents working on the same project share tools but need different permission levels. Wrapping them in MCP servers is the right fit. When an Agent hits an MCP endpoint, the server checks the role and serves only the allowed operations.
Here's the core of the supabase wrapper. Reads the role header and filters queries accordingly.
const policy = {
planner: { read: true, write: false },
coder: { read: true, write: true, migrate: false },
reviewer: { read: true, write: false },
tester: { read: true, write: true, tables: ['test_*'] },
debugger: { read: true, write: false },
};
server.tool('supabase.query', async (req) => {
const role = req.meta.agent_role;
const p = policy[role];
if (!p) throw new Error('unknown role');
if (req.op === 'insert' && !p.write) {
throw new Error(`${role} has no write`);
}
return await supabase.from(req.table)[req.op](req.payload);
});
This one server centralizes DB permissions for all five Agents. No need to repeat prohibition rules in every system prompt — the server rejects anything outside role permissions. Agent prompts stay readable; security lives on the server side.
Same pattern for docs-search (restrict to project markdown files) and logs (restrict to last 24 hours). Putting boundaries on the server — not in the Agent — also makes debugging easier. If something goes wrong, check the MCP server log.
Supabase agent_state — Schema and Migration
The moment I split roles, I hit a wall. Coder sessions didn't know about the spec Planner had written. Different sessions don't share memory. So I created an agent_state table in Supabase and write task state there. Each Agent writes only to its own slot.
CREATE TABLE agent_state (
task_id text primary key,
project text not null,
current_owner text, -- planner | coder | ...
status text not null default 'planning',
spec jsonb,
implementation_notes jsonb,
review_findings jsonb,
test_results jsonb,
debug_trace jsonb,
created_at timestamptz default now(),
updated_at timestamptz default now()
);
CREATE INDEX idx_agent_state_project ON agent_state(project);
CREATE INDEX idx_agent_state_status ON agent_state(status);
-- keep status as text for flexibility
-- planning → coding → reviewing → testing → debugging? → done
Columns are split so it's obvious which stage broke. If a session dies mid-turn, "status=reviewing, review_findings is null" immediately tells me the Reviewer turn died. Restart = run that turn again.
State-transition guards live in a Supabase Edge Function. Moving from "planning" to "coding" requires that the spec column is populated — the DB enforces it. Protects against Agents skipping steps.
There's a file trail too. docs/tasks/{task_id}.md holds human-readable output per Agent. DB is the state record, files are the reading record. When I look at output and ask "what happened?" — I open the file.
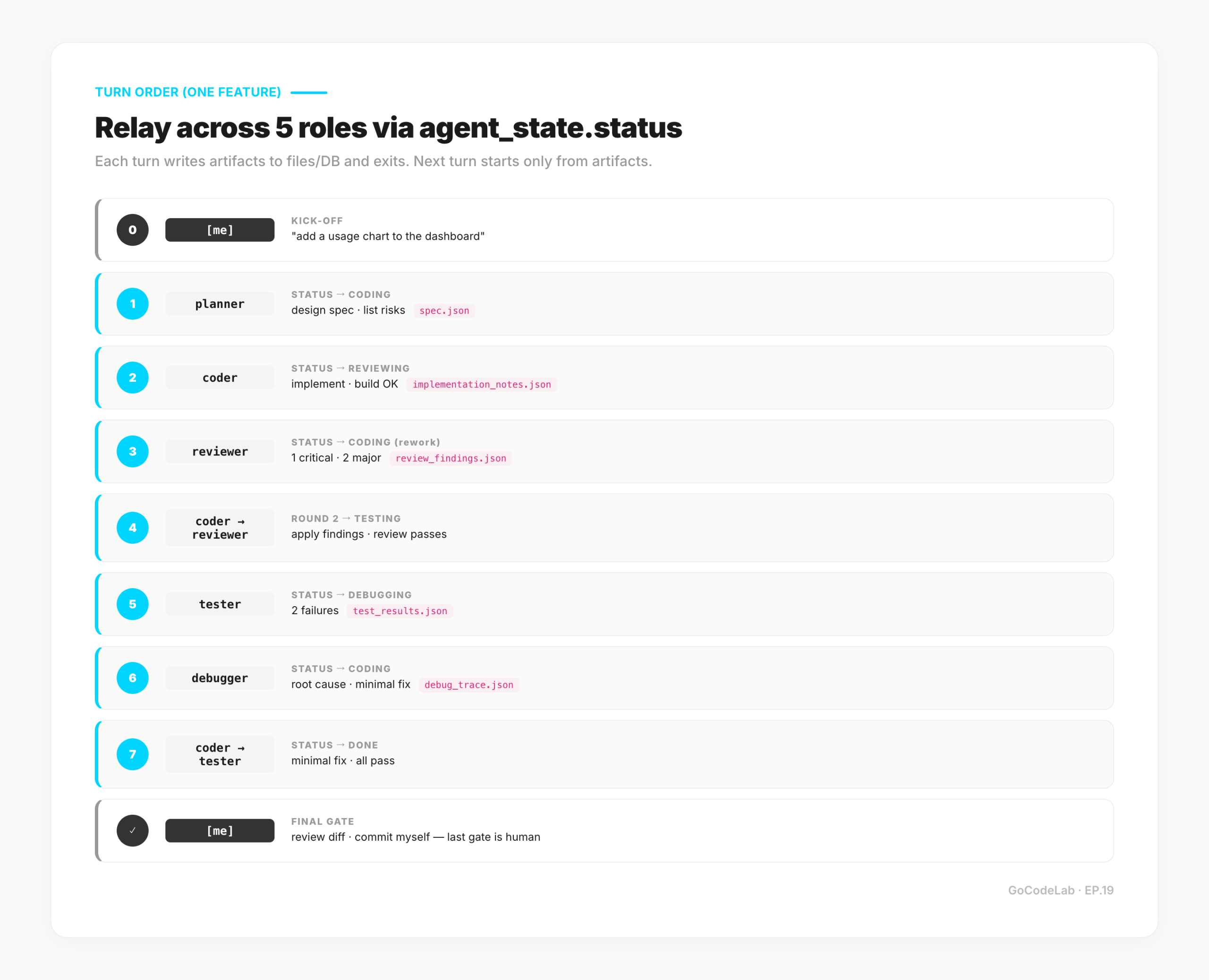
The Actual Routine — Turn Order and Script
Turns are driven by one shell script. Claude Code auto-loads subagent files at ~/.claude/agents/<name>.md. The script just tells the main session "read the current state for this task_id and delegate to that subagent." --mcp-config pins MCP servers, --append-system-prompt injects the task context.
# usage: agent-run.sh <task_id> <agent>
TASK_ID=$1
AGENT=$2
# 1. pull current state (Supabase REST)
STATE=$(curl -s "$SUPABASE_URL/rest/v1/agent_state?task_id=eq.$TASK_ID" \
-H "apikey: $SUPABASE_ANON_KEY")
# 2. launch Claude Code (subagents auto-loaded)
claude \
--mcp-config "$HOME/.claude/mcp.json" \
--append-system-prompt "Task: $TASK_ID. State: $STATE. Delegate to the '$AGENT' subagent only." \
-p "Use the $AGENT subagent to handle task $TASK_ID. Read the current agent_state, perform only your role, write back to your own column, and exit."
# 3. after exit, propose the next Agent (human gates it)
NEXT_STATUS=$(curl -s "$SUPABASE_URL/rest/v1/agent_state?task_id=eq.$TASK_ID&select=status" -H "apikey: $SUPABASE_ANON_KEY" | jq -r '.[0].status')
echo "current status: $NEXT_STATUS"
echo "next suggested: $(next-agent.sh $NEXT_STATUS)"
Claude Code subagents isolate context by design. Calling a subagent from the main session starts it with a clean context, its own system prompt, and only its allowed tools. Results come back as a summary — cross-session memory isn't shared. That's exactly why I introduced the Supabase agent_state table: subagents needed "accumulated state" to pass between each other, and that has to live outside any single session.
A human gates between Agents. I don't auto-launch the next Agent. I read the output, decide to move on, and kick off the next turn. I tried full auto once and it wandered off course — manual gating is the current setup.
Here's the turn trace for a single feature.
[me] → agent-run.sh task-001 planner
"add a usage chart to the dashboard"
planner → spec.json → status=coding
[me] → scan spec → agent-run.sh task-001 coder
coder → implement → implementation_notes.json
→ build OK → status=reviewing
[me] → agent-run.sh task-001 reviewer
reviewer → read diff → review_findings.json
1 critical, 2 major → status=coding (rework)
coder → apply findings → status=reviewing (round 2)
reviewer → OK → status=testing
tester → write & run → 2 failures → status=debugging
debugger → root cause → debug_trace.json → status=coding
coder → minimal fix → status=testing
tester → all pass → status=done
[me] → review diff → commit myself
Key point: turns are closed. A single Agent session does only its job, leaves output in files/DB, and exits. The next Agent doesn't inherit the previous session — it reads artifacts. Sessions can die without affecting restart, and re-running a middle stage is easy.
Commits stay with me. No Agent has commit permissions — the point where code enters my repo is where I want the human in the loop. Team of five, final gate is still me.
What Changed, What Didn't (Honestly)
What changed: edge cases get caught earlier. Reviewer is built to nitpick, so "looks good" doesn't come cheap. Same code Coder called fine, Reviewer finds three problems in. Coder reflects them, Reviewer re-runs, quality climbs another notch.
Debugging sped up. Debugger is a separate session, so the context is clean. It focuses on the failure log without any "I just wrote this, it should be fine" bias from Coder. Swapping sessions killed that bias.
What didn't change: final review is still mine. Five Agents pass the code, I still skim the diff. Tester sometimes writes meaningless tests. Reviewer sometimes demands a bar nothing can pass. Debugger sometimes names the wrong cause. Team or not, the last gate is a human.
Cost went up too. About 2–3x the tokens of a single-session run. Each role loads its own system prompt, and the same code gets read by multiple sessions. On the other hand, rework rounds dropped, so total wall-clock time actually went down. A token-for-time trade.
Built on the EP.17 Harness
EP.17 wired up harness engineering: Rules (CLAUDE.md), Commands (/plan-and-spec, /tdd, /verify, ...), Hooks (block-dangerous.sh). The scaffold a single Claude session works inside.
EP.19 stacks an Agent team on that harness. Same materials. The plan-and-spec command became Planner's Skill. The tdd command became Tester's Skill. Each Agent runs Commands on its turn. Hooks remain a global safety net across all Agents.
Put another way: EP.17 was a single-session workflow. EP.19 is the same workflow split into five. Starting with the split from day one would've been complicated — building the harness first, then placing a team on top, was the right sequence. Gathering materials first and assigning roles afterward is simpler.
FAQ
Q. Can the same model produce different results just by changing the role?
Yes. When the system prompt and referenced skill differ, the output distribution shifts noticeably. A session set up as Reviewer doesn't hand out "looks fine" easily. Ask it to nitpick and it nitpicks. Role setup changes the output.
Q. Aren't Claude Code subagents enough on their own?
For simple cases, yes. I needed cross-session state sharing, so I went custom. Work state persists in Supabase, and Agent-to-Agent communication runs through MCP servers. Subagents are designed to isolate context — they don't carry cumulative state across sessions by design.
Q. Is 5 the right size?
For my workflow, yes. Planner, Coder, Reviewer, Tester, Debugger. I tried splitting further, but roles started overlapping. With only 4, there was a gap — no dedicated debugger.
Q. Why MCP + an external DB?
Multiple agents had to pass the same task forward. The spec Planner wrote had to reach Coder; the code Coder wrote had to reach Reviewer. Sessions don't share memory, so I store task state in Supabase and let each Agent read its slot on its turn.
Q. How does this differ from EP.17 harness engineering?
EP.17 wired up Rules, Commands, and Hooks for a single Claude session. EP.19 stacks multiple Agents on top of that harness so each session carries one role. Same materials — what one session used to do is now split across five.
Closing
Role separation is less prompt engineering than workflow engineering. Same model, same codebase — split the session, and the result shifts. Ask the Coder to review, it shields its own work. Split off a Reviewer session, and it nitpicks. That gap is why I built the team.
80% first, then fix the remaining 20% as real problems show up. This team grew that way. Planner and Coder first. Adding Reviewer showed clearly how quality changed. Test automation was thin, so Tester joined. Debugger got split out last to kill debugging bias. Teams should grow by need.
Final review is still mine. Even after five Agents, I skim the code myself. Reviewer can be too strict, Tester's tests can be meaningless, Debugger can point the wrong way. With a team, the last gate is human. Take that as a given, and role separation alone changes code quality — measurably.
Based on an actually running workflow plus official docs. Services and features can change — check official docs for the latest.
Originally published: April 2026 · GoCodeLab