무료 AI 받아쓰기 나왔어요 — Cohere Transcribe vs Whisper vs ElevenLabs 정확도 비교
무료 AI 받아쓰기 나왔어요 — Cohere Transcribe vs Whisper vs ElevenLabs 정확도 비교
2026년 4월 1일 · 비교
회의 녹음을 텍스트로 바꿀 때, Whisper 말고 다른 선택지가 생겼어요. 3월 26일, Cohere가 Cohere Transcribe를 공개했는데 Hugging Face 오픈 ASR 리더보드에서 1위를 찍었어요. 2B 파라미터에 무료 API까지, 숫자가 꽤 인상적이에요.
AI 받아쓰기 시장은 이미 OpenAI Whisper가 반쯤 장악한 상태예요. ElevenLabs도 Scribe v2로 도전했고, NVIDIA Canary나 IBM Granite 같은 모델도 경쟁에 뛰어들었어요. 이번엔 기업용 LLM으로 유명했던 Cohere가 STT 영역에 처음 진출했어요. 세 모델이 어떻게 다른지, 어떤 상황에서 뭘 쓰면 좋은지 비교해봤어요.
STT(Speech-to-Text) 모델은 WER(단어 오류율)로 정확도를 따져요. 숫자가 낮을수록 더 정확하게 받아써줘요. 이 기준으로 세 모델을 줄세우면 결과가 꽤 명확하게 나와요.
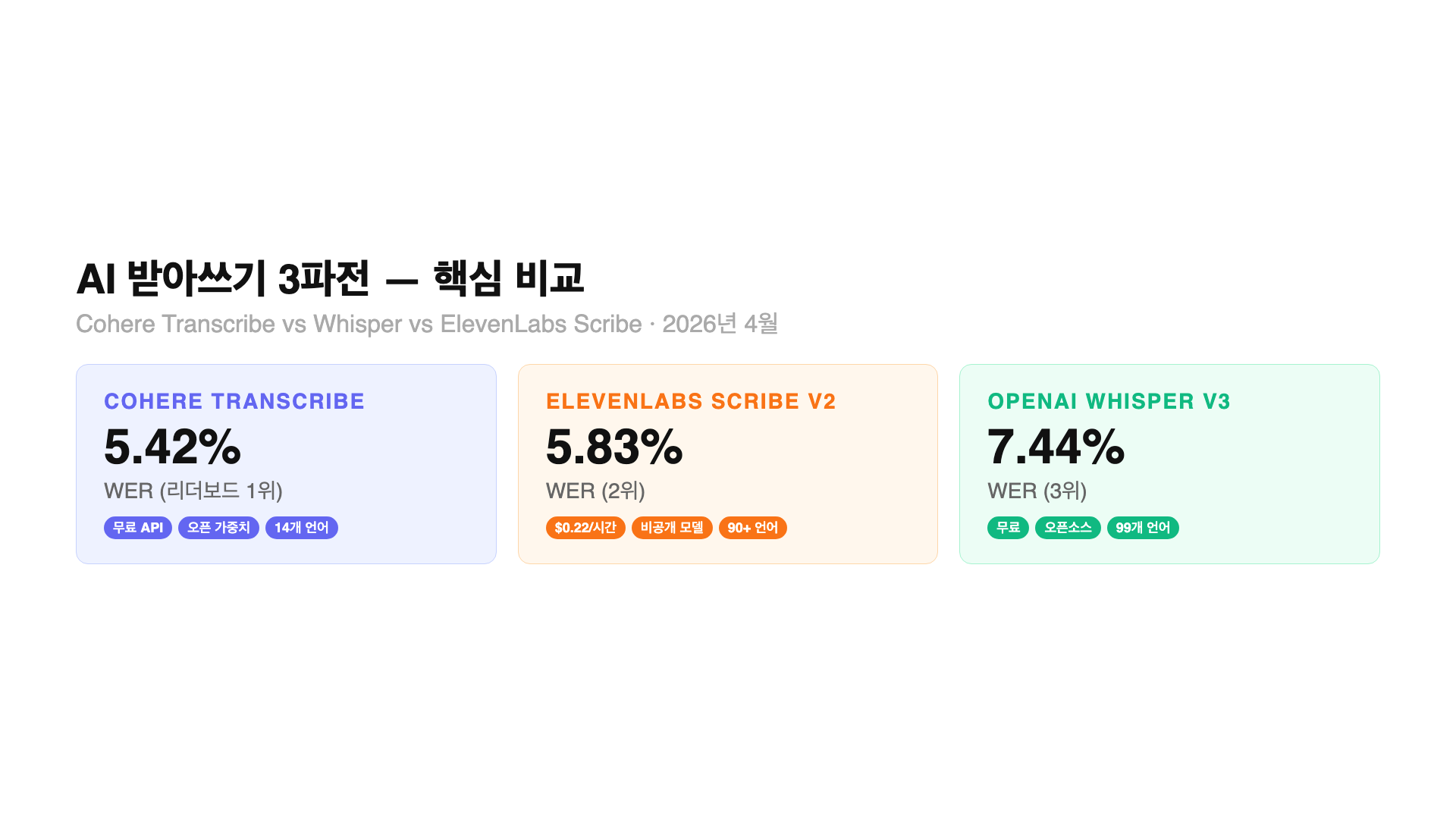
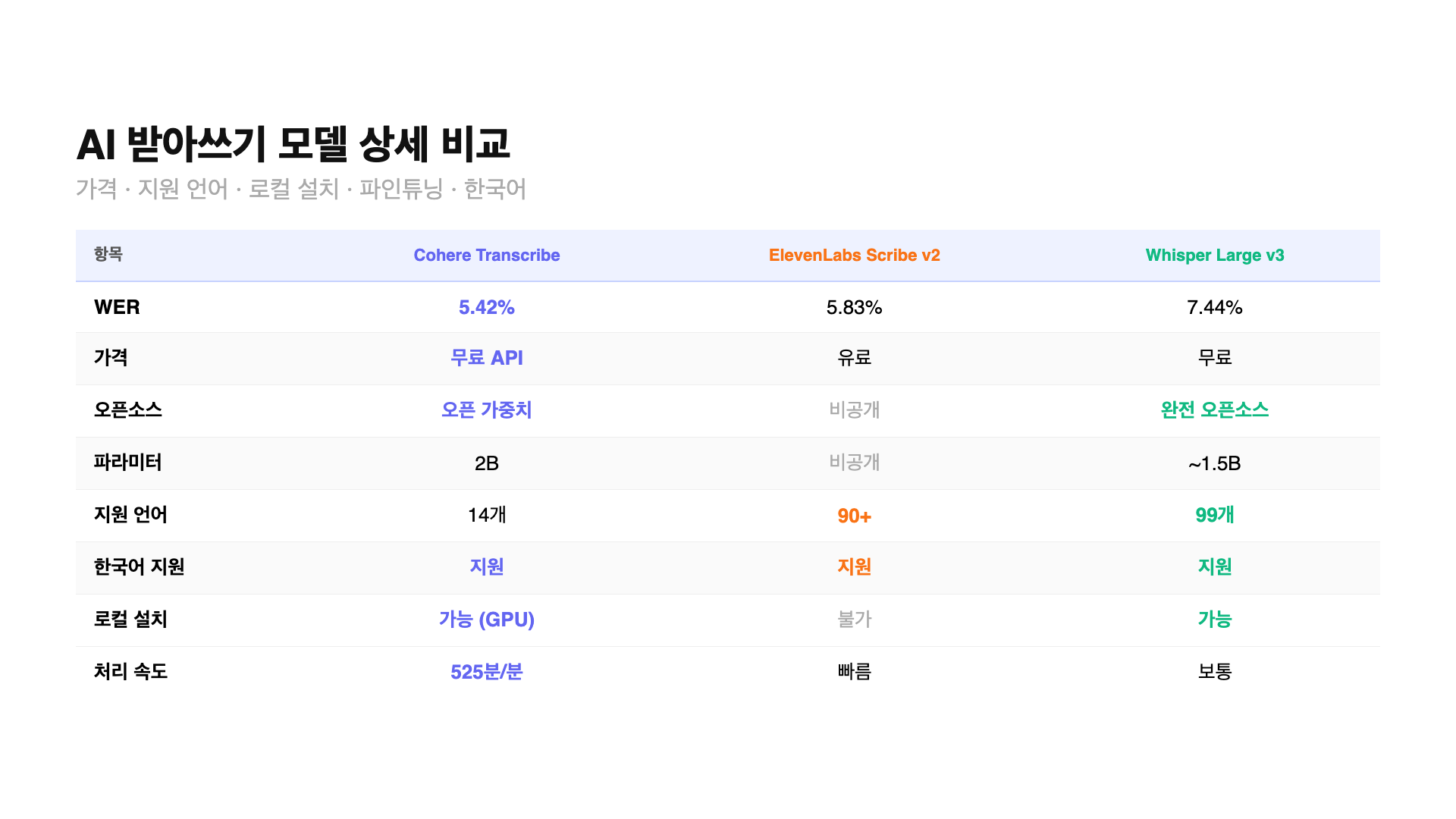
– Cohere Transcribe: WER 5.42%, 무료 오픈소스(Apache 2.0), 14개 언어(한국어 포함), 2B 파라미터
– ElevenLabs Scribe v2: WER 5.83%, 유료($0.22/시간), 90개 이상 언어, 비공개 모델
– OpenAI Whisper Large v3: WER 7.44%, 완전 오픈소스, 99개 언어, 1.55B 파라미터
– 인간 평가에서 Cohere가 영어 기준 Whisper 대비 64%, ElevenLabs 대비 51% 선호됨
– 독일어(44%)·스페인어(48%)·포르투갈어(48%)에서는 Cohere가 오히려 약세
– 한국어 정확도는 세 모델 모두 영어보다 낮음 — Whisper 기준 CER 약 11%
Cohere Transcribe, 어떻게 나온 거예요?
Cohere는 2019년에 설립된 캐나다 토론토 기반 AI 회사예요. Command 시리즈 LLM, 임베딩 모델(Embed), 검색 재순위 모델(Rerank) 등 기업용 텍스트 AI로 알려져 있어요. 2025년에는 연간 반복 매출(ARR)이 2억 4천만 달러를 넘겼고, 2026년 IPO가 예상되는 상황이에요. 이번에 STT 영역으로 처음 들어온 건 기업용 에이전트 플랫폼 North의 기능 확장 맥락에서 나온 거예요.
Transcribe는 Conformer 기반 ASR(Automatic Speech Recognition) 모델이에요. Conformer는 CNN과 Transformer를 결합한 구조로, 음성 인식에서 널리 쓰이는 아키텍처예요. 모델 크기는 2B(20억) 파라미터이고, Whisper Large v3가 1.55B인 걸 감안하면 약 30% 더 큰 규모예요. 오디오를 입력으로 받아 텍스트를 출력하는 전용 모델이라, 텍스트 생성이나 대화 기능은 없어요. 받아쓰기 하나에만 집중하는 구조예요.
모델 가중치는 Hugging Face에 Apache 2.0 라이선스로 공개됐어요. 상업적 사용도 자유롭다는 뜻이에요. API는 Cohere 공식 페이지에서 현재 무료로 쓸 수 있고, 관리형 추론 플랫폼인 Model Vault에서도 이용할 수 있어요. 앞으로 기업용 에이전트 오케스트레이션 플랫폼 North에도 통합될 예정이에요. North는 2025년 8월에 출시된 Cohere의 기업 전용 AI 에이전트 플랫폼으로, 자체 방화벽 뒤에서 AI 에이전트를 운영할 수 있게 해줘요.
로컬 설치도 가능해요. 양자화(INT4 등)를 적용하면 VRAM 8GB 미만으로도 돌릴 수 있어서 RTX 3070 같은 소비자용 GPU에서 구동돼요. Hugging Face에는 WebGPU 데모까지 공개돼 있어서 브라우저에서 바로 테스트해볼 수도 있어요.
WER 수치로 보는 정확도 비교
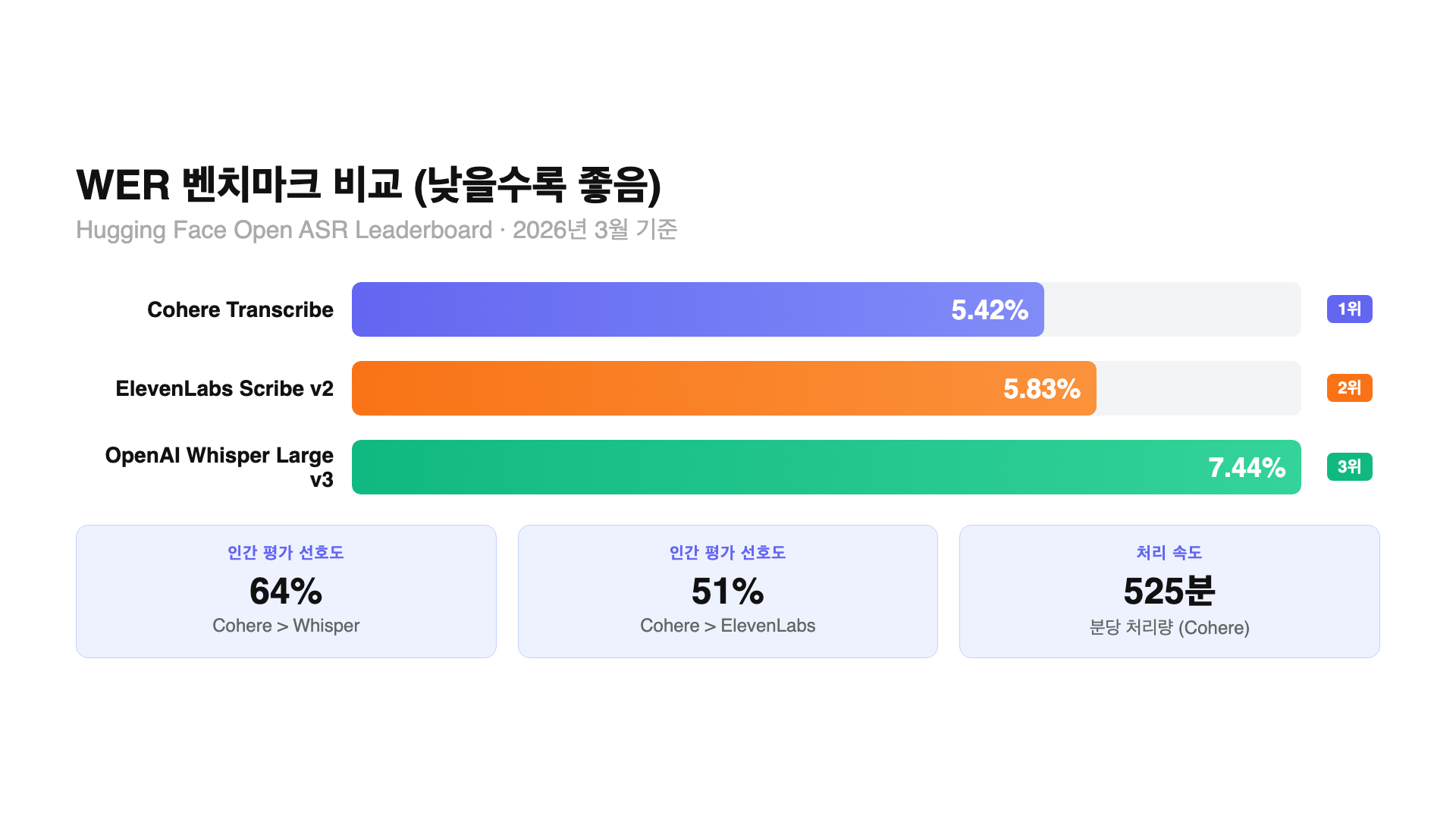
WER(Word Error Rate)은 받아쓰기 모델의 표준 성능 지표예요. 전체 단어 중에서 잘못 인식한 비율을 나타내요. 삽입, 삭제, 치환 오류를 모두 합쳐서 계산해요. 5.42%라면 100단어 중 약 5~6단어 정도가 틀린다는 뜻이에요.
아래 수치는 모두 Hugging Face 오픈 ASR 리더보드 기준(2026년 3월 26일 시점)이에요. 같은 벤치마크 조건에서 측정된 값이라 공정한 비교가 가능해요.
| 모델 | WER (낮을수록 좋음) | 가격 | 오픈소스 | 언어 수 |
|---|---|---|---|---|
| Cohere Transcribe | 5.42% | 무료 API | 오픈 가중치 (Apache 2.0) | 14개 |
| ElevenLabs Scribe v2 | 5.83% | 유료 ($0.22/시간) | 비공개 | 90개 이상 |
| OpenAI Whisper Large v3 | 7.44% | 무료 | 완전 오픈소스 | 99개 |
벤치마크 수치만 보면 Cohere가 앞서요. Cohere와 Whisper의 WER 차이는 약 27%의 상대적 개선이에요. 그런데 WER은 테스트 데이터셋과 언어 구성에 따라 크게 달라질 수 있어요. Cohere의 5.42%는 리더보드 평균값이고, 개별 언어로 들어가면 편차가 심해요.
인간 평가 결과도 있어요. 정확도, 일관성, 사용성을 기준으로 평가자들이 직접 비교했어요. 영어 기준으로 Cohere Transcribe가 Whisper Large v3보다 64%, ElevenLabs Scribe v2보다 51%의 선호도를 얻었어요. IBM Granite 4.0 1B 대비로는 78%까지 올라가요. 평균 승률은 다른 모델 대비 61%예요. 다만 이 수치는 Cohere가 자체적으로 실시한 평가라는 점은 감안해야 해요.
리더보드에는 NVIDIA Canary Qwen 2.5B(WER 5.63%), IBM Granite Speech 3.3 8B(WER 5.85%), Qwen3-ASR-1.7B(WER 5.76%) 같은 다른 강자들도 있어요. Cohere는 이 모델들보다 더 작은 크기(2B)로 더 낮은 WER을 달성한 거예요. 모델 크기 대비 효율이 높다는 뜻이에요.
언어별 성능 — 어디서 강하고, 어디서 약할까요?
Cohere Transcribe가 지원하는 14개 언어는 영어, 프랑스어, 독일어, 이탈리아어, 스페인어, 포르투갈어, 그리스어, 네덜란드어, 폴란드어, 중국어, 일본어, 한국어, 베트남어, 아랍어예요. Whisper의 99개에 비하면 확실히 적지만, 주요 언어는 대부분 커버해요.
문제는 14개 언어 전부에서 1위가 아니라는 점이에요. Cohere가 공식 발표에서 직접 인정한 약점이 있어요. 인간 평가 기준으로 독일어는 44%, 스페인어와 포르투갈어는 각각 48%의 선호도를 기록했어요. 50% 미만이면 경쟁 모델보다 오히려 밀렸다는 뜻이에요. 유럽어 3개 언어에서 다른 모델에 뒤진 셈이에요.
반면에 강한 언어도 확실해요. 일본어에서는 Whisper 대비 66%, Qwen3-ASR 대비 70%의 선호도를 보였어요. 이탈리아어도 60%로 높은 편이에요. 영어와 동아시아 언어(일본어, 한국어, 중국어)에서는 Cohere가 확실히 우위에 있어요.
유럽어(독일어·스페인어·포르투갈어) 중심으로 쓸 계획이라면 Cohere Transcribe보다 Whisper Large v3가 나을 수 있어요. Cohere가 공식적으로 인정한 약점이니까요. 영어나 동아시아 언어 중심이라면 Cohere가 확실히 유리해요.
ElevenLabs Scribe v2는 90개 이상의 언어를 지원해요. 언어 범위만 놓고 보면 Whisper(99개)에 버금가는 수준이에요. 다만 비공개 모델이라 언어별 세부 WER 수치는 공개되지 않았어요. ElevenLabs 자체 벤치마크에서는 FLEURS 다국어 벤치마크 기준 93.5%의 정확도를 달성했다고 발표했어요.
속도와 비용 — 실제로 쓰면 어떨까요?
Cohere는 Transcribe의 처리 속도가 분당 525분 분량이라고 발표했어요. 30분짜리 회의 녹음을 올리면 약 3~4초 안에 텍스트가 나온다는 뜻이에요. 다만 이 수치는 Cohere가 자체적으로 발표한 것이고, 독립적으로 검증된 건 아니에요. 실제 처리 속도는 서버 하드웨어나 배치 설정에 따라 달라질 수 있어요.
비용 구조가 세 모델에서 가장 크게 갈려요. 현재 상황을 정리하면 이래요.
| 모델 | API 비용 | 로컬 설치 | 비고 |
|---|---|---|---|
| Cohere Transcribe | 무료 | 가능 (VRAM 8GB 미만) | 유료 전환 가능성 있음 |
| ElevenLabs Scribe v2 | $0.22/시간 (배치) $0.39/시간 (실시간) |
불가 | 실시간 처리(150ms) 별도 과금 |
| OpenAI Whisper Large v3 | 무료 (자체 호스팅) | 가능 | GPU 비용은 별도 |
Cohere API는 현재 무료예요. Cohere API에 가입하면 Transcribe 엔드포인트를 바로 쓸 수 있어요. 다만 Cohere가 기업용 플랫폼 North에 통합한 후 프리미엄 기능에 대해 유료화할 가능성은 있어요. 지금은 무료 티어가 넉넉하게 열려 있어요.
ElevenLabs는 확실히 유료예요. 배치 처리 기준 시간당 $0.22(약 300원), 실시간 처리는 시간당 $0.39(약 530원)이에요. 소규모로 쓰면 크게 부담은 아니지만, 대량 처리를 하면 비용이 쌓여요. 무료 티어도 있지만 할당량이 제한적이에요.
Whisper는 모델 자체가 완전 오픈소스라 API 비용이 없어요. 대신 직접 서버를 돌리려면 GPU 비용이 들어요. 클라우드 GPU를 빌리거나 로컬 GPU가 필요해요. Groq, Together AI 같은 서드파티 호스팅을 이용하면 저렴하게 API로 쓸 수도 있어요.
비용만 따지면 Cohere가 가장 유리해요. 무료 API에 오픈 가중치까지 제공하니까요. 정확도와 무료를 둘 다 잡은 셈이에요. 다만 무료가 영원할지는 아직 모르니, 지금 여유 있을 때 테스트해보는 게 좋아요.
한국어 지원, 실제로 어떨까요?
Cohere Transcribe가 지원하는 14개 언어 목록에 한국어가 포함돼 있어요. 공식 발표 자료에도 Korean이 명시돼 있어요. 그런데 한국어만 따로 뗀 WER 수치는 공개하지 않았어요. 일본어에서 66~70%의 높은 선호도를 보인 걸 감안하면 한국어도 비슷한 수준일 가능성이 있지만, 추측일 뿐이에요.
Whisper는 99개 언어를 지원하고, 한국어도 초기 버전부터 지원해왔어요. 참고로 한국어 음성 인식에서는 WER 대신 CER(Character Error Rate, 글자 오류율)을 많이 써요. 한국어는 띄어쓰기가 불규칙한 경우가 많아서 단어 단위 비교보다 글자 단위 비교가 더 정확하거든요. Whisper Large v3의 한국어 CER은 KsponSpeech 벤치마크 기준 약 11.13%로 알려져 있어요. 영어(CER 3.91%)와 비교하면 약 3배 높은 오류율이에요.
ElevenLabs Scribe v2는 90개 이상의 언어를 지원해요. 한국어도 포함돼 있어요. 다만 한국어 개별 성능 수치는 별도로 공개되지 않았어요.
세 모델 모두 한국어를 지원하지만, 영어 대비 정확도는 확실히 낮아요. 특히 구어체, 빠른 말투, 영어 단어가 섞인 대화에서는 오류가 더 많이 생겨요. 한국어 기준으로 세 모델의 직접 비교 수치는 아직 없어서, 당장 한국어 성능이 중요하다면 세 모델 모두 직접 테스트해보는 게 가장 정확해요.
한국어 STT에서 주의할 점이 하나 더 있어요. 의료, 법률, 금융 같은 전문 용어가 많은 도메인에서는 범용 STT 모델의 오류율이 더 올라가요. 이런 환경에서는 파인튜닝이 가능한 Whisper나 Cohere Transcribe가 유리해요. ElevenLabs는 모델이 비공개라 파인튜닝이 불가능해요.
상황별 추천 — 어떤 걸 골라야 할까요?
세 모델이 각각 잘 맞는 상황이 달라요. 어떤 맥락에서 쓰느냐에 따라 선택이 바뀌어요.
정확도가 최우선이고 비용 부담 없이 시작하고 싶다면 Cohere Transcribe가 현재 가장 합리적인 선택이에요. 무료 API에 리더보드 1위 수치니까요. 다만 사용 언어가 영어·한국어·일본어·중국어 같은 Cohere가 강한 언어여야 해요. 유럽어 중심이라면 오히려 약세인 점을 기억해야 해요.
99개 언어 중 하나를 써야 하거나, 완전한 로컬 환경에서 오래 검증된 모델이 필요하다면 Whisper Large v3가 안정적이에요. WER은 가장 높지만, 커뮤니티 지원과 파인튜닝 레퍼런스가 가장 풍부해요. Whisper를 기반으로 한 파인튜닝 모델도 수백 개가 있어서, 특정 도메인에 맞춰 성능을 끌어올리기 쉬워요.
팀에서 이미 ElevenLabs를 TTS 용도로 쓰고 있다면 Scribe v2를 함께 쓰는 것도 나쁘지 않아요. 워크플로 통합이 쉽고, 정확도도 Cohere와 큰 차이 없어요. 실시간 처리가 필요하다면 Scribe v2 Realtime(150ms 지연)이 강점이에요. 단, 추가 비용은 감수해야 해요.
– 영어/한국어 중심, 비용 없이 시작: Cohere Transcribe
– 다국어(유럽어 포함), 오래된 커뮤니티 생태계, 파인튜닝: Whisper Large v3
– ElevenLabs TTS 통합 워크플로, 실시간 처리 필요: ElevenLabs Scribe v2
– 기업 보안 환경, 오프라인 필수: Cohere 로컬 설치 또는 Whisper 로컬 설치

실전 활용 — 회의록·자막·콘텐츠 제작
STT 모델이 가장 많이 쓰이는 곳은 회의록 자동화예요. 회의 녹음 파일을 올리면 텍스트가 나오고, 여기에 ChatGPT나 Claude 같은 LLM을 연결해서 요약이나 액션 아이템 추출까지 이어가는 파이프라인이 많이 쓰여요. Cohere Transcribe는 이 용도에서 정확도와 속도를 동시에 잡아요. 무료 API니까 프로토타입 만들어서 바로 테스트해볼 수 있다는 것도 장점이에요.
유튜브 영상 자막 제작도 주요 활용처예요. 영상 파일에서 오디오를 추출하고 STT를 돌린 후 SRT 형식으로 변환하면 자막 파일이 완성돼요. Cohere의 처리 속도(자체 발표 기준 525분/분)가 사실이라면 1시간짜리 영상도 수 초 안에 끝나는 셈이에요. 유튜브 크리에이터에게는 자막 작업 시간을 크게 줄여줄 수 있어요.
팟캐스트 콘텐츠를 텍스트로 전환해서 블로그나 뉴스레터로 재활용하는 경우에도 쓰여요. 최근에는 팟캐스트 에피소드 전체를 STT로 텍스트화한 뒤 LLM으로 요약·편집해서 글로 발행하는 워크플로가 늘어나고 있어요. 이 경우엔 정확도보다 처리 속도가 중요할 수 있는데, Cohere Transcribe는 두 가지 다 괜찮아요.
기업 보안이 중요한 환경이라면 로컬 설치 옵션이 결정적이에요. 외부 API에 민감한 회의 내용을 보내지 않아도 되니까요. Cohere Transcribe는 양자화 시 VRAM 8GB 미만으로 돌릴 수 있어서, 별도 서버 없이도 개발자 PC에서 바로 구동할 수 있어요. Whisper도 마찬가지로 로컬 설치가 가능하고, 더 작은 Whisper 변형(Turbo, Distil)을 쓰면 더 가볍게 돌릴 수 있어요.
콜센터 음성 분석이나 의료 녹취록 변환처럼 대량의 오디오를 정기적으로 처리하는 환경도 있어요. 이런 곳에서는 API 비용이 쌓이기 쉬운데, Cohere의 무료 API는 초기 비용 부담을 크게 줄여줘요. 규모가 커지면 로컬 설치로 전환하는 전략도 가능해요.
FAQ
Q. Cohere Transcribe는 정말 무료예요?
현재는 무료예요. Cohere API에 가입하면 Transcribe 엔드포인트를 무료로 사용할 수 있어요. 모델 가중치도 Hugging Face에 Apache 2.0 라이선스로 공개돼 있어서 직접 로컬에서 돌리는 것도 가능하고, 상업적 사용도 자유예요. 다만 Cohere가 기업용 플랫폼 North에 통합하면서 프리미엄 기능에 대해 유료화할 가능성은 있어요. 무료일 때 테스트해두는 게 좋아요.
Q. Whisper Large v3과 비교하면 얼마나 더 좋아요?
Hugging Face 오픈 ASR 리더보드 기준으로 Cohere가 WER 5.42%, Whisper가 7.44%예요. 약 27% 상대적 개선이에요. 인간 평가에서도 영어 기준 Cohere가 Whisper보다 선호된다는 응답이 64%였어요. 일본어에서는 66%까지 올라가요. 하지만 독일어(44%), 스페인어(48%), 포르투갈어(48%)에서는 오히려 Whisper에 밀려요. “모든 면에서 Whisper보다 낫다”가 아니라 “특정 언어에서 확실히 앞선다”로 이해하는 게 정확해요.
Q. 한국어는 Cohere Transcribe가 가장 좋아요?
한국어만 따로 비교한 공식 수치가 없어서 단정하기 어려워요. 참고로 한국어 음성 인식에서는 WER보다 CER(글자 오류율)을 많이 써요. Whisper Large v3의 한국어 CER은 KsponSpeech 기준 약 11%예요. Cohere는 일본어에서 높은 선호도를 보였으니 한국어도 비슷할 수 있지만 추측이에요. 세 모델 모두 한국어를 지원하니, 직접 같은 오디오로 테스트해보는 게 가장 정확해요.
Q. ElevenLabs Scribe가 더 나은 점은 없어요?
있어요. 먼저 언어 수에서 90개 이상을 지원해서 Cohere(14개)보다 훨씬 넓어요. 실시간 처리에서도 Scribe v2 Realtime은 150ms 지연으로 동작해서, 라이브 자막이나 실시간 통역 같은 용도에 강해요. 이미 ElevenLabs TTS를 쓰는 팀이라면 같은 플랫폼에서 STT까지 처리할 수 있어 관리가 편해요. WER도 5.83%로 Cohere와 큰 차이 없어요. 비용($0.22~$0.39/시간)만 감수할 수 있다면 충분히 좋은 선택이에요.
Q. 오디오 파일 형식 제한이 있어요?
Cohere 공식 문서 기준으로 주요 오디오 형식(MP3, WAV, M4A, FLAC 등)을 지원해요. Whisper도 마찬가지예요. ElevenLabs Scribe도 일반적인 오디오 포맷을 대부분 지원해요. 다만 세부 지원 목록은 각 서비스 공식 문서에서 확인하는 게 정확해요. 처리할 수 없는 형식이라면 ffmpeg으로 WAV나 MP3로 변환 후 업로드하면 돼요.
Q. 처리 속도 525분/분이 정말 맞아요?
Cohere가 공식 발표에서 밝힌 수치예요. 하지만 이 속도는 Cohere의 자체 인프라 기준이고, 독립적으로 검증된 건 아니에요. 실제 처리 속도는 서버 하드웨어, 배치 크기, 오디오 길이, 동시 요청 수에 따라 달라질 수 있어요. 로컬 GPU에서 돌리면 서버 대비 훨씬 느릴 수 있어요. 참고 수치로 보되, 본인 환경에서 직접 측정해보는 게 좋아요.
Q. Conformer 아키텍처가 뭐예요?
Conformer는 Convolution + Transformer를 합친 음성 인식 전용 모델 구조예요. CNN으로 오디오의 지역적 패턴(발음, 음절)을 잡고, Transformer의 어텐션으로 긴 문맥(문장 흐름)을 처리해요. Google이 2020년에 발표한 구조인데, 이후 대부분의 고성능 ASR 모델이 이 구조를 기반으로 만들어지고 있어요. Whisper는 순수 Transformer 구조인데, Cohere는 Conformer를 채택해서 같은 파라미터 수 대비 음성 인식 효율이 더 좋을 수 있어요.
마무리
Cohere Transcribe는 무료에 오픈 가중치(Apache 2.0), 리더보드 1위라는 조합이 꽤 매력적이에요. 영어와 한국어·일본어 중심이라면 지금 바로 테스트해볼 만해요. 다만 독일어·스페인어·포르투갈어에서는 오히려 약하다는 점, 그리고 처리 속도 수치가 아직 독립 검증되지 않았다는 점은 알고 있어야 해요.
Whisper Large v3는 WER이 가장 높지만, 99개 언어 지원과 풍부한 커뮤니티 생태계가 여전히 큰 장점이에요. 파인튜닝 레퍼런스가 수백 개나 있어서 특정 도메인에 맞춤 적용하기 가장 쉬운 모델이에요. “안전한 선택”이 필요하다면 여전히 Whisper예요.
ElevenLabs Scribe v2는 90개 이상 언어 지원, 150ms 실시간 처리, TTS 생태계 통합이 강점이에요. 비용만 감수할 수 있다면 가장 편하게 쓸 수 있는 상업용 서비스예요.
아직 한국어 구어체 성능은 세 모델 모두 영어만큼 좋지는 않아요. 회의록 자동화나 자막 생성에 쓴다면, 결과물을 한 번 검토하는 과정은 아직 필요해요. 다만 STT 시장이 2026년 들어 빠르게 발전하고 있으니, Cohere의 참전은 그 경쟁을 한 단계 더 끌어올렸어요. 앞으로 Whisper나 ElevenLabs가 어떻게 대응할지도 지켜볼 만해요.
AI 받아쓰기가 궁금하다면, Cohere Transcribe API를 무료로 지금 바로 테스트해볼 수 있어요.
이 글은 2026년 4월 1일에 작성됐어요. 수치는 Hugging Face 오픈 ASR 리더보드(2026.3.26 기준)와 각 회사 공식 발표를 기반으로 해요. Cohere Transcribe는 출시 초기 모델이며, 성능과 가격 정책은 추후 바뀔 수 있어요.
GoCodeLab에서는 AI 도구를 직접 써보고 솔직하게 알려드려요. 다른 AI 소식이 궁금하면 블로그를 구독해주세요.
관련 글: ElevenLabs보다 낫다는 무료 음성 AI가 나왔어요 — Mistral Voxtral TTS 비교 · OpenAI가 Sora를 껐어요 — ‘Spud’ 모델에 전부 걸었다고요? · MCP 프로토콜이 9천700만 설치 넘었어요