Claude Opus 4.7 Launch — Beats GPT-5.4, Admits It Loses to Mythos
Anthropic shipped Claude Opus 4.7 on April 16, 2026. Beat GPT-5.4 on SWE-bench Pro (64.3% vs 57.7%), admitted publicly that it trails the unreleased Mythos Preview. Benchmarks, pricing, context window changes.
On this page (9)
April 2026 · AI Trends
On April 16, 2026, Anthropic released Claude Opus 4.7. The launch came with one line that stood out: "We are below Mythos." Anthropic openly admitted its publicly released model sits behind an internal preview model.
On SWE-bench Pro, Opus 4.7 hit 64.3%, outpacing GPT-5.4 (57.7%) and Gemini 3.1 Pro (54.2%). SWE-bench Verified landed at 87.6% against Gemini's 80.6%. But against Anthropic's own unreleased Mythos Preview, the numbers are lower. That kind of honest positioning is rare in the current AI launch playbook.
This post walks through the benchmark numbers, pricing structure, and the Mythos gap. Useful if you want to absorb the release quickly. If you're already running Claude in production, pricing and batch structure are unchanged — you can swap the model name today.
· Release: April 16, 2026 — Claude Platform · AWS Bedrock · Google Vertex AI · Microsoft Foundry (simultaneous)
· SWE-bench Pro: 64.3% (GPT-5.4 57.7% · Gemini 3.1 Pro 54.2%)
· SWE-bench Verified: 87.6% (Gemini 80.6%)
· Context window: 1,000,000 tokens — this release drops the long-context premium
· Pricing: $5 input / $25 output per 1M tokens (same as 4.6)
· Batch API 50% discount + prompt caching up to 90%
· Tool error rate: ~1/3 of 4.6 · 3x image resolution · multi-agent orchestration improved
· Mythos gap: publicly admitted — "Opus 4.7 is not a downsized Mythos"
· New tokenizer: up to 35% more tokens on the same text — watch your real bill
Launch recap — Opus 4.7 in three numbers
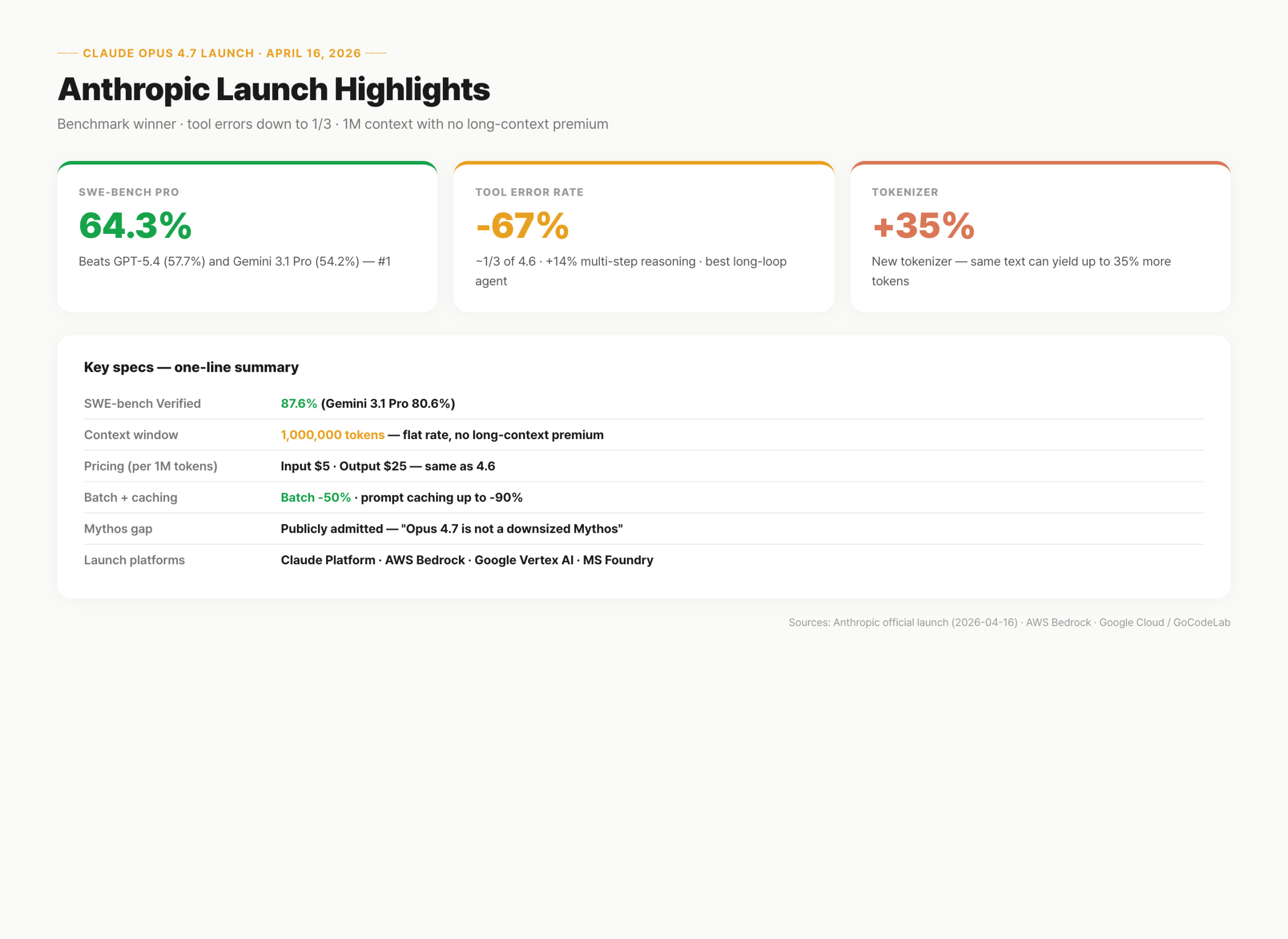
The launch boils down to three figures: SWE-bench Pro at 64.3% (first place), tool errors down to about one-third of 4.6, and a 1M token context with no long-context premium across the full range. Anthropic leaned on all three repeatedly in the announcement.
Opus 4.7 is an incremental refinement of Opus 4.6. Tool stability, agentic coordination, and agent-loop completion were the targets. Not a new architecture. API surface is unchanged — swap the model name and existing prompts still behave.
What's unusual is the Mythos comparison right in the launch deck. Naming your own unreleased model as a benchmark reference inside your release is off-script for AI launches.
Beating GPT-5.4 on SWE-bench Pro
SWE-bench Pro measures end-to-end resolution of real GitHub issues. Think of it as grading on a stack of real-world tickets. Opus 4.7 scored 64.3%. GPT-5.4 sat at 57.7%, Gemini 3.1 Pro at 54.2%. Opus 4.7 takes first with a 6.6-point lead.
SWE-bench Verified runs in the same direction: Opus 4.7 at 87.6%, Gemini 3.1 Pro at 80.6%. The multilingual variant moved from 4.6's 77.8% to 80.5%. On GDPVal-AA (Elo-based knowledge work) Opus scored 1,753, ahead of GPT-5.4's 1,674 and Gemini's 1,314.
But rankings flip by domain. BrowseComp (web research) is led by GPT-5.4 Pro at 89.3%. Opus 4.7 actually slid from 4.6's 83.7% down to 79.3%. Anthropic published that number directly. No sugar-coating the mixed result.
Why admit losing to Mythos
Claude Mythos Preview is an internal model distributed under Project Glasswing. AWS, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, Microsoft, NVIDIA — nine major firms — plus roughly 40 additional organizations received limited, defensive-security-only access. Anthropic added $100M in usage credits and $4M in donations to the Linux Foundation and Apache Software Foundation.
General release is refused for a reason. Mythos autonomously discovered and exploited a 17-year-old FreeBSD remote-code-execution vulnerability (CVE-2026-4747). According to Anthropic, it found thousands of zero-day vulnerabilities across major operating systems and browsers in just a few weeks. Shipping it would cause more damage than good.
In the Opus 4.7 announcement, Anthropic explicitly stated Opus 4.7 "is not a downsized Mythos." Different lineages, not intentionally throttled. Mythos sits above in raw capability, but Opus is the model that can safely ship. This transparency is uncommon: OpenAI and Google generally launch their top model. "We have something stronger internally but won't ship it for safety reasons" is a trust-first positioning move.
Mythos Preview: Glasswing's nine primary firms (AWS · Apple · Google · Microsoft and others) plus ~40 organizations
Autonomous offensive capability: FreeBSD CVE-2026-4747 (17-year-old RCE) discovered and exploited — thousands of zero-days
Opus 4.7: the shippable frontier — "not a downsized Mythos" per Anthropic
Further reading: Claude Mythos System Card Analysis — GoCodeLab
Pricing — same rates, new tokenizer
Sticker: $5 input / $25 output per 1M tokens. Identical to Opus 4.6. Batch API still cuts 50%. Prompt caching stacks up to 90% off. GPT-5.4 and Gemini 3.1 Pro do not offer a batch discount.
Batch API is asynchronous request bundling — imagine opening every lane of a checkout counter at once. Good for document analysis, code review pipelines, bulk test generation. Not for interactive flows.
The catch is the new tokenizer. Opus 4.7 uses a different tokenizer than earlier Opus versions. Anecdotally, the same text can tokenize to up to 35% more tokens. Same per-token price, bigger actual invoice. Before cutting over production traffic, measure with representative prompts.
Context window — flat rate across 1M
Context window is 1,000,000 tokens. This release puts it in the official spec for the first time. It matches GPT-5.4 (1,050,000) and Gemini 3.1 Pro (1,000,000). Context window is your desk — bigger desk, more code you can spread at once.
What's actually new is the flat rate. Prior Opus versions tacked on a long-context premium at higher token counts. 4.7 keeps a single price across the full 1M. GPT-5.4 doubles past 272K, Gemini 3.1 Pro doubles past 200K.
Most workloads don't fill a million tokens. You need that range only when scanning hundreds of thousands of lines of legacy code in one go. For everyday usage, all three models are plenty. But long-context-heavy pipelines land cheaper on Opus because of the missing premium.
Tool error rate and agent stability
Tool error rate is the silent killer of agent pipelines. A bad API call or malformed output stops the whole chain. Per Anthropic, Opus 4.7's tool error rate is roughly one-third of 4.6. Multi-step agentic reasoning improved by 14%.
For single calls, you won't notice. At 10+ steps, errors compound. Overnight autonomous pipelines fail on a single step. Opus's stability edge is the core reason Anthropic frames this as the "agent release."
Also: image handling at 3x higher resolution. Matters for workflows heavy on visuals — screenshot-based QA, PDF analysis, UI testing. Multi-agent coordination got durability improvements for multi-hour orchestration scenarios.
Competitive landscape — GPT & Gemini response
No official reply from OpenAI or Google yet. GPT-5.5 is rumored for next month; Gemini 3.2 Pro is on the 2026 roadmap. The benchmark race continues into the next quarter.
Developer reactions are split. The batch API discount and removal of long-context premium may matter more than the benchmark lead in actual production ops. Mixing models by use case is already a common pattern.
Anthropic's public Mythos framing is a long-game move. Trust capital compounds over time. Being second to market on benchmarks today, but first in enterprise trust a year from now — that's the bet the launch positions for.
What developers will notice
For existing Claude users, agent-loop stability is the most visible improvement. Mid-run failures in 10+ step tool calls dropped noticeably. Cursor, Cline, and similar IDE integrations report the same trend.
API users just swap names. Change `claude-opus-4-6` to `claude-opus-4-7` and you're done. No schema changes. Existing prompts usually behave identically. AWS Bedrock, Google Cloud Vertex AI, and Microsoft Foundry all shipped simultaneously, so cloud partner users can flip the switch the same day.
For vibe coders on Claude.ai, Opus 4.7 is now the default inside the Max plan. Nothing to configure. Max limits apply as before; Pro limits stay capped.
const response = await anthropic.messages.create({
model: 'claude-opus-4-7', // was 'claude-opus-4-6'
max_tokens: 4096,
messages: [{ role: 'user', content: prompt }],
});
Sticker price is unchanged, but the new tokenizer can raise real bills. Up to 35% more tokens on identical text per external analyses. Measure a few representative prompts for token count before you flip production.
FAQ
Q. Which benchmarks did Claude Opus 4.7 beat GPT-5.4 on?
SWE-bench Pro at 64.3% (GPT-5.4 at 57.7%), SWE-bench Verified at 87.6% (Gemini at 80.6%), and GDPVal-AA at 1,753 (GPT-5.4 at 1,674). Note: BrowseComp is GPT-5.4 Pro at 89.3%, with Opus slipping from 83.7% to 79.3% — Anthropic admitted the drop publicly.
Q. Why admit trailing Mythos?
Mythos Preview is restricted under Project Glasswing — nine primary firms plus ~40 organizations. It autonomously finds and exploits zero-days, so Anthropic won't release it publicly. Opus 4.7 is positioned as the strongest shippable model, and the transparency is a trust play.
Q. What's the context window?
1,000,000 tokens. Specified officially in this release. The full 1M range runs at a flat rate — no long-context premium. Compare with GPT-5.4 (2x past 272K) and Gemini 3.1 Pro (2x past 200K).
Q. Pricing and batch discount?
$5 input / $25 output per 1M tokens. Same as Opus 4.6. Batch API keeps the 50% discount. Prompt caching up to 90%. Caveat: the new tokenizer may split the same text into up to 35% more tokens, so real bills can rise even at the same sticker.
Q. When can I use it?
April 16, 2026 onward. Available on Claude Platform, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. Cursor, Cline, Zed and similar IDEs added support within 24 hours. Existing API users just change the model name.
Opus 4.7 isn't a shock launch. It's the release that tightens agent reliability and pricing structure while nudging benchmark scores up. In production terms, that's the more useful kind of update. Swap the model name, measure, and move on.
The Mythos callout is the interesting signal. Saying out loud "we aren't shipping the strongest model we have" is a stake in the ground: safety and deployment responsibility sit at the center of the business. Long term, that's the kind of positioning that decides enterprise adoption.
· Anthropic — Introducing Claude Opus 4.7
· Anthropic — Claude Opus model page
· Anthropic API Docs — What's new in Claude Opus 4.7
· Anthropic Pricing
· AWS — Claude Opus 4.7 on Amazon Bedrock
· Claude Mythos System Card Analysis — GoCodeLab
Based on Anthropic's official announcement (2026-04-16) and public materials from Amazon Bedrock and Google Cloud Vertex AI. Numbers and pricing may change.
Claude, Claude Opus, and Claude Mythos are registered trademarks of Anthropic.