DeepSeek가 ChatGPT를 복사했다고요? — OpenAI vs DeepSeek IP 논란 정리
DeepSeek이 ChatGPT 출력을 학습 데이터로 썼다는 의혹이 터졌어요. OpenAI는 미 의회에
On this page (9)
2026년 4월 4일 · AI 소식
2025년 1월, DeepSeek R1이 나오자마자 AI 업계가 술렁였어요. 성능은 꽤 괜찮은데 개발 비용이 기존 대비 극단적으로 낮다는 거였어요. 그런데 곧 다른 종류의 이야기가 나오기 시작했어요. “저 모델, ChatGPT를 베낀 거 아니야?”
OpenAI와 Microsoft가 먼저 의혹을 제기했어요. DeepSeek R1의 훈련 과정에서 ChatGPT의 출력을 학습 데이터로 사용했다는 주장이었어요. 2026년 2월에는 OpenAI가 미 의회 중국특별위원회에 공식 메모까지 제출했어요. 단순한 소문이 아니라 정치적 이슈로 번진 거예요.
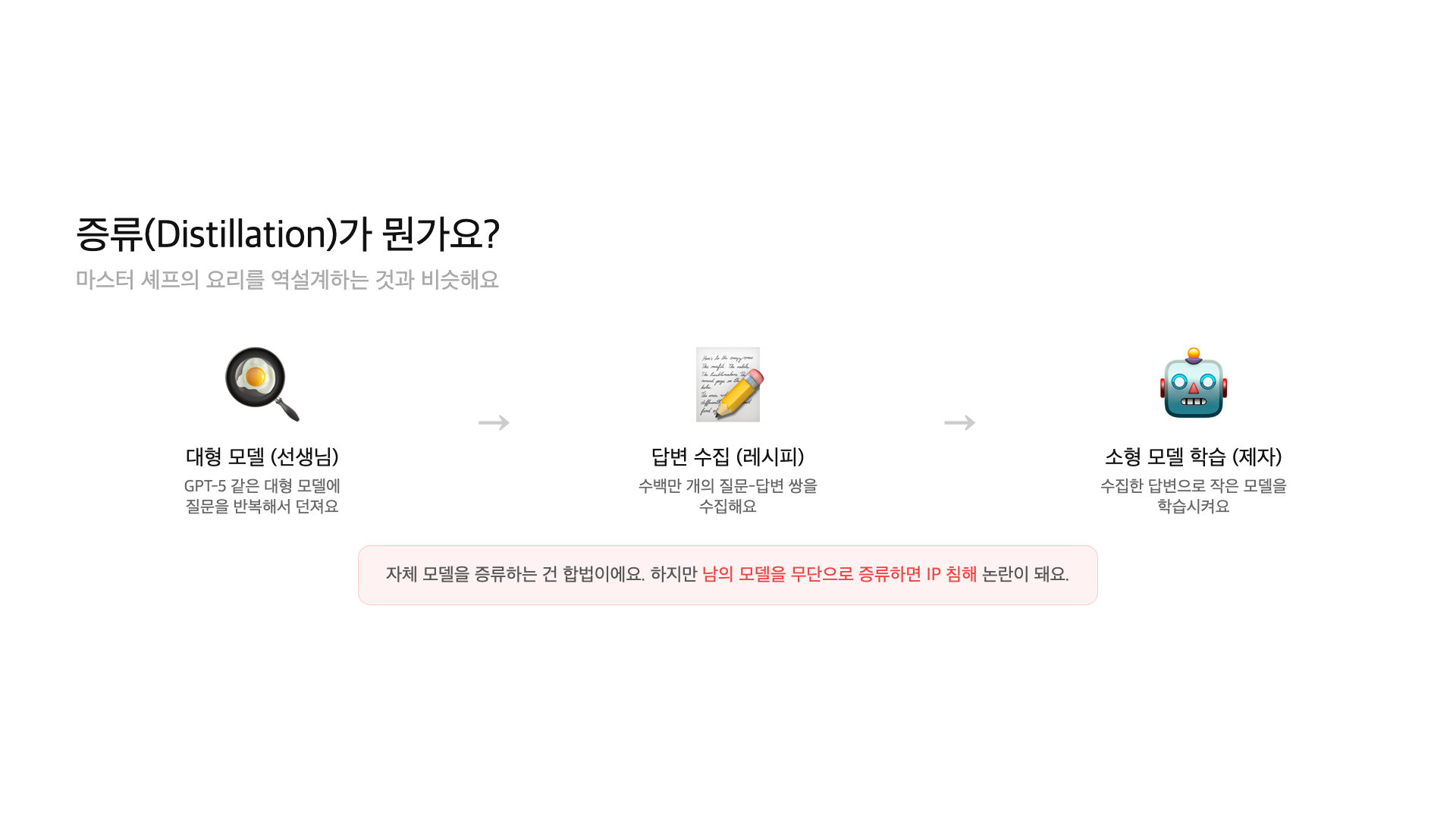
이 논란의 핵심에 있는 기술이 ‘디스틸레이션’이에요. 비유하면 이래요. 유명 셰프 레스토랑에 매일 주문해서 음식을 분석하고, 재료와 조리법을 역설계해서 내 가게 메뉴를 만드는 거예요. 원본 레시피를 직접 훔친 건 아니지만, 결과물을 체계적으로 복제한 거예요.
– 2025년 1월: DeepSeek R1 출시, OpenAI·Microsoft가 ChatGPT 출력 학습 의혹 제기
– 2026년 2월 12일: OpenAI가 미 의회 중국특별위원회에 공식 메모 제출
– 2026년 2월 24일: Anthropic도 DeepSeek·Moonshot AI·MiniMax의 조직적 디스틸레이션 고발
– 핵심 기법 ‘디스틸레이션’: 큰 모델의 출력으로 작은 모델을 훈련시키는 방식

디스틸레이션이 뭔데 문제가 되는 거예요?
디스틸레이션(distillation)은 큰 AI 모델의 출력을 학습 데이터로 써서 작은 모델을 훈련시키는 기법이에요. 마스터 셰프 레스토랑에서 반복 주문하고, 맛·식감·향을 하나하나 기록해서 레시피를 역설계하는 거라고 보면 돼요. 원본 레시피 문서를 훔치지는 않았지만, 결과물을 체계적으로 복제하는 거예요.
기술적으로 보면 이래요. 큰 모델(teacher)에게 수백만 개의 프롬프트를 넣고, 그 응답을 수집해요. 이 응답 데이터를 사용해서 작은 모델(student)을 훈련시키면, 작은 모델이 큰 모델의 행동 패턴을 따라 하게 돼요. 비용 대비 성능이 놀라울 정도로 좋아요.
디스틸레이션 자체는 합법적인 기술이에요. OpenAI도 GPT-4의 지식을 GPT-4o mini에 디스틸레이션해요. Google도 Gemini에서 Gemma로 지식을 이전해요. 문제는 ‘남의 모델’을 허가 없이 디스틸레이션하는 거예요. 여기서 법적 경계가 모호해져요.
DeepSeek R1, 무슨 일이 있었나요?
2025년 1월, 중국 AI 스타트업 DeepSeek이 R1 모델을 공개했어요. MIT 라이선스 오픈소스로 풀린 이 모델은 추론 능력에서 GPT-4 수준에 근접했어요. 그런데 개발 비용이 기존 대형 모델 대비 극단적으로 낮았어요. 업계에서 “어떻게?”라는 질문이 바로 나왔어요.
OpenAI와 Microsoft가 내부 조사를 시작했어요. 두 회사의 주장에 따르면, DeepSeek 직원들이 ChatGPT 접근 제한을 우회하는 코드를 개발했어요. 난독화된 서드파티 라우터를 통해 모델 출력을 대량 수집했다는 거예요. 이렇게 모은 출력 데이터로 자사 모델을 디스틸레이션했다는 게 핵심 의혹이에요.
DeepSeek 측은 부인했어요. 독자적인 훈련 데이터와 방법론으로 개발했다는 입장이에요. 양쪽 주장 모두 독립적으로 검증되지는 않았어요.
OpenAI의 의회 메모 — 어떤 내용이 담겼나요?
2026년 2월 12일, OpenAI가 미 의회 중국특별위원회에 메모를 제출했어요. 단순한 기업 간 분쟁이 아니라 국가 안보 차원에서 다뤄야 한다는 프레임이었어요.
메모의 핵심 주장은 세 가지예요. 첫째, DeepSeek 직원들이 API 접근 제한을 우회하는 전용 코드를 개발했어요. 둘째, 난독화된 서드파티 라우터를 이용해 대량 스크래핑을 했어요. 셋째, 수집한 출력을 디스틸레이션용 훈련 데이터로 사용했어요.
AI 기술 유출은 단순한 저작권 문제가 아니에요. 미국 정부 입장에서는 수십억 달러를 투자한 AI 기술이 우회적으로 유출되는 안보 이슈예요. 2025년 6월에 이미 중국 AI 시스템을 연방 기관에서 차단하는 초당적 법안이 발의된 상태였어요.
OpenAI가 이 메모를 의회에 보낸 시점도 중요해요. DeepSeek R1이 나온 지 1년이 넘은 시점이에요. 왜 이제서야? 미중 AI 경쟁이 격화되면서, 기술 보호를 정치적 이슈로 만드는 전략이라는 분석도 있어요.
Anthropic도 나섰어요 — 문제가 커지는 이유
2026년 2월 24일, Anthropic(Claude를 만드는 회사)도 공식 성명을 냈어요. DeepSeek뿐 아니라 Moonshot AI, MiniMax까지 세 개 중국 AI 회사가 자사 모델에 대해 조직적 디스틸레이션 캠페인을 벌였다고 고발했어요.
Anthropic이 참전한 게 중요한 이유가 있어요. OpenAI 한 곳의 주장이면 기업 간 다툼으로 볼 수 있어요. 그런데 서로 경쟁하는 두 미국 AI 기업이 같은 패턴을 보고했다면, 단발성이 아니라 구조적인 문제일 가능성이 높아지는 거예요.
Moonshot AI는 Kimi 챗봇으로 알려져 있고, MiniMax는 Hailuo AI로 유명한 회사예요. 세 회사 모두 중국 기반이에요. 미국 측에서는 이걸 개별 기업의 일탈이 아니라 체계적 패턴으로 보고 있어요.
디스틸레이션 탐지가 기술적으로 가능한지도 쟁점이에요. 모델 출력에 워터마크를 심거나, 특정 프롬프트에 대해 고유한 패턴을 삽입하는 방식이 연구되고 있어요. OpenAI는 이런 탐지 기술을 이미 개발 중이라고 밝힌 바 있어요. 하지만 워터마크가 디스틸레이션 과정에서 살아남는지는 아직 검증이 필요해요.
법적으로 어떻게 될까요?
솔직히, 아직 아무것도 확정된 게 없어요. 디스틸레이션이 불법인지 판단할 법적 판례가 없어요. 기존 저작권법이나 영업비밀 보호법으로 다룰 수 있는지도 논란이에요.
현재 상황을 정리하면 이래요. API 이용약관 위반은 비교적 명확해요. ChatGPT나 Claude API 약관에는 출력을 경쟁 모델 훈련에 쓸 수 없다고 적혀 있어요. 그런데 이건 계약 위반이지, 형사 범죄는 아니에요. 국제 소송으로 가면 집행도 어려워요.
Output Restrictions:
“경쟁 모델 개발·훈련에 API 출력을 사용하는 것을 금지”
“접근 제한을 우회하는 자동화된 수집 금지”
“위반 시 서비스 접근 차단 및 법적 조치”
// 단, 이건 계약 위반이지 형사 범죄는 아님
// 국제 소송 집행은 또 다른 문제
2025년 6월에 발의된 초당적 법안도 주목할 부분이에요. 중국 AI 시스템을 미국 연방 기관에서 사용 금지하는 내용이에요. 직접적으로 디스틸레이션을 다루는 법은 아니지만, 중국 AI 기술에 대한 미국 정부의 경계심이 법제화되고 있다는 신호예요.
AI 업계는 이미 디스틸레이션을 쓰고 있어요
논란의 핵심이 여기에 있어요. 디스틸레이션은 AI 업계에서 표준적으로 쓰이는 기법이에요. 새로운 것도, 특별한 것도 아니에요.
OpenAI는 GPT-4의 지식을 GPT-4o mini에 디스틸레이션해요. Google은 Gemini 시리즈에서 Gemma 시리즈로 지식을 이전해요. Meta도 Llama 시리즈에서 같은 기법을 써요. 자기 모델을 디스틸레이션하는 건 아무 문제 없어요.
경계가 모호해지는 건 ‘타사 모델 출력을 수집해서 훈련에 사용하는 행위’예요. API를 정상적으로 사용하고, 그 결과물을 참고하는 건 합법이에요. 그런데 접근 제한을 우회하고, 체계적으로 대량 수집해서 훈련에 쓰면 이야기가 달라져요. 어디까지가 ‘정당한 사용’이고 어디서부터 ‘약탈’인지, 아직 업계 합의도 법적 기준도 없어요.
비유로 돌아가볼게요. 레스토랑에서 밥 먹고 “이거 맛있다, 비슷하게 만들어봐야지”라고 하는 건 자유예요. 그런데 매일 100인분씩 주문해서 식품 연구소에 보내 성분 분석을 시키고, 그 결과로 프랜차이즈를 차리면? 레스토랑 주인은 분명 다르게 느낄 거예요. AI 디스틸레이션 논란이 정확히 이 지점에 있어요.
일반 사용자한테 무슨 의미가 있을까요?
단기적으로는 크게 영향 없어요. ChatGPT를 쓰든, DeepSeek을 쓰든 서비스 자체가 바뀌지는 않아요. 그런데 장기적으로는 몇 가지 변화가 올 수 있어요.
첫째, API 이용약관이 강화될 가능성이 높아요. 이미 OpenAI는 의심스러운 대량 요청을 모니터링하는 시스템을 강화했어요. 정상적인 개발자에게도 레이트 리밋이 더 빡빡해질 수 있어요.
둘째, 지역 제한이 확대될 수 있어요. 미국 정부가 중국 AI 서비스의 국내 사용을 제한하는 방향으로 가고 있어요. 이미 연방 기관 차단 법안이 발의됐고, 민간으로 확대될 수도 있어요.
셋째, 오픈소스 AI 생태계에도 영향이 있을 수 있어요. 디스틸레이션 논란이 커지면, 모델 공개 시 출력 사용 제한을 거는 추세가 강화될 거예요. 이미 일부 모델은 라이선스에 “경쟁 모델 훈련 금지” 조항을 넣고 있어요.

넷째, AI 업계의 투명성 요구가 높아질 수 있어요. 모델이 어떤 데이터로 훈련됐는지 공개하라는 압력이 커지고 있어요. EU의 AI Act는 이미 고위험 AI 시스템에 대해 훈련 데이터 문서화를 요구하고 있어요. 디스틸레이션 논란은 이런 규제 움직임에 힘을 실어줄 수 있어요.
FAQ
Q. 디스틸레이션이 정확히 뭔가요?
큰 AI 모델의 출력을 학습 데이터로 써서 작은 모델을 훈련시키는 기법이에요. 마스터 셰프한테 반복 주문해서 맛을 분석하고 레시피를 역설계하는 것과 비슷해요.
Q. DeepSeek이 실제로 ChatGPT를 복사한 건가요?
아직 확정된 건 아니에요. OpenAI가 미 의회에 의혹을 제기했고, DeepSeek은 독자적 훈련이라고 반박하고 있어요. 독립적으로 검증된 증거는 공개되지 않았어요.
Q. 디스틸레이션은 불법인가요?
법적으로 회색지대예요. 자사 모델을 디스틸레이션하는 건 합법이에요. 타사 모델을 허가 없이 디스틸레이션하는 게 불법인지는 아직 판례가 없어요. API 이용약관 위반은 맞을 수 있지만, 형사 범죄는 아니에요.
Q. Anthropic은 왜 나선 건가요?
DeepSeek뿐 아니라 Moonshot AI, MiniMax까지 세 회사가 조직적으로 디스틸레이션을 했다고 고발했어요. OpenAI 혼자만의 주장이 아니라, 업계 공통 피해라는 걸 보여주기 위해서예요.
Q. 일반 사용자한테 어떤 영향이 있나요?
단기적으로는 없어요. 장기적으로는 API 이용약관 강화, 중국 AI 서비스 사용 제한, 오픈소스 라이선스 조건 변화 등이 올 수 있어요.
마무리
DeepSeek vs OpenAI 디스틸레이션 논란은 단순한 기업 간 다툼이 아니에요. AI 모델의 ‘출력’이 지식재산에 해당하는지, 디스틸레이션의 법적 경계는 어디인지, 미중 AI 경쟁에서 기술 보호를 어떻게 할 건지 — 여러 층위의 질문이 한꺼번에 터진 사건이에요.
확실한 건 하나 있어요. 이 논란이 쉽게 끝나지는 않을 거예요. 법적 판례도 없고, 업계 합의도 없고, 국제 협약은 더더욱 없어요. AI가 빠르게 발전하는 만큼, 규칙 만드는 속도도 따라가야 하는 시점이에요.
이 글은 2026년 4월 4일에 작성됐어요. OpenAI의 미 의회 메모(2026.2.12)와 Anthropic의 공식 성명(2026.2.24), 각 회사 공식 발표를 기반으로 해요. 법적 판단이 확정된 사안은 아니며, 양측 주장이 독립적으로 검증되지 않았어요.
GoCodeLab에서는 AI 소식을 직접 확인하고 솔직하게 알려드려요. 다른 AI 소식이 궁금하면 블로그를 구독해주세요.