같은 Claude인데 역할만 나눴더니 코드 품질이 달라졌다 — 5인 에이전트 팀 구축 따라하기
내가 직접 구축한 개발단계 에이전트 팀 활용법. Planner·Coder·Reviewer·Tester·Debugger 5역할로 나누고 MCP + Supabase로 연결했다. 폴더 구조·시스템 프롬프트·Skill·DB 스키마·턴 순서까지 따라할 수 있게 정리했다.
목차 (12)
2026년 4월 · 귀찮은개발자 EP.19
PR을 올렸다. Reviewer로 띄운 Claude가 엣지케이스 3개와 메모리 누수 1개를 짚었다. 직전 세션에서 Coder로 띄운 Claude는 같은 코드를 "완벽하다"고 했다. 같은 Claude 4.6이다. 역할만 달랐다.
이 차이가 에이전트 팀을 직접 구축한 이유다. 혼자 쓰고 혼자 검증하니 당연히 잡힐 게 안 잡혔다. Reviewer 역할을 맡은 세션은 "괜찮다"는 답을 쉽게 내지 않는다. 꼬집으라고 시키면 꼬집는다. 그걸 확인하고 나서 개발 흐름 전체를 역할별로 쪼개야겠다고 판단했다.
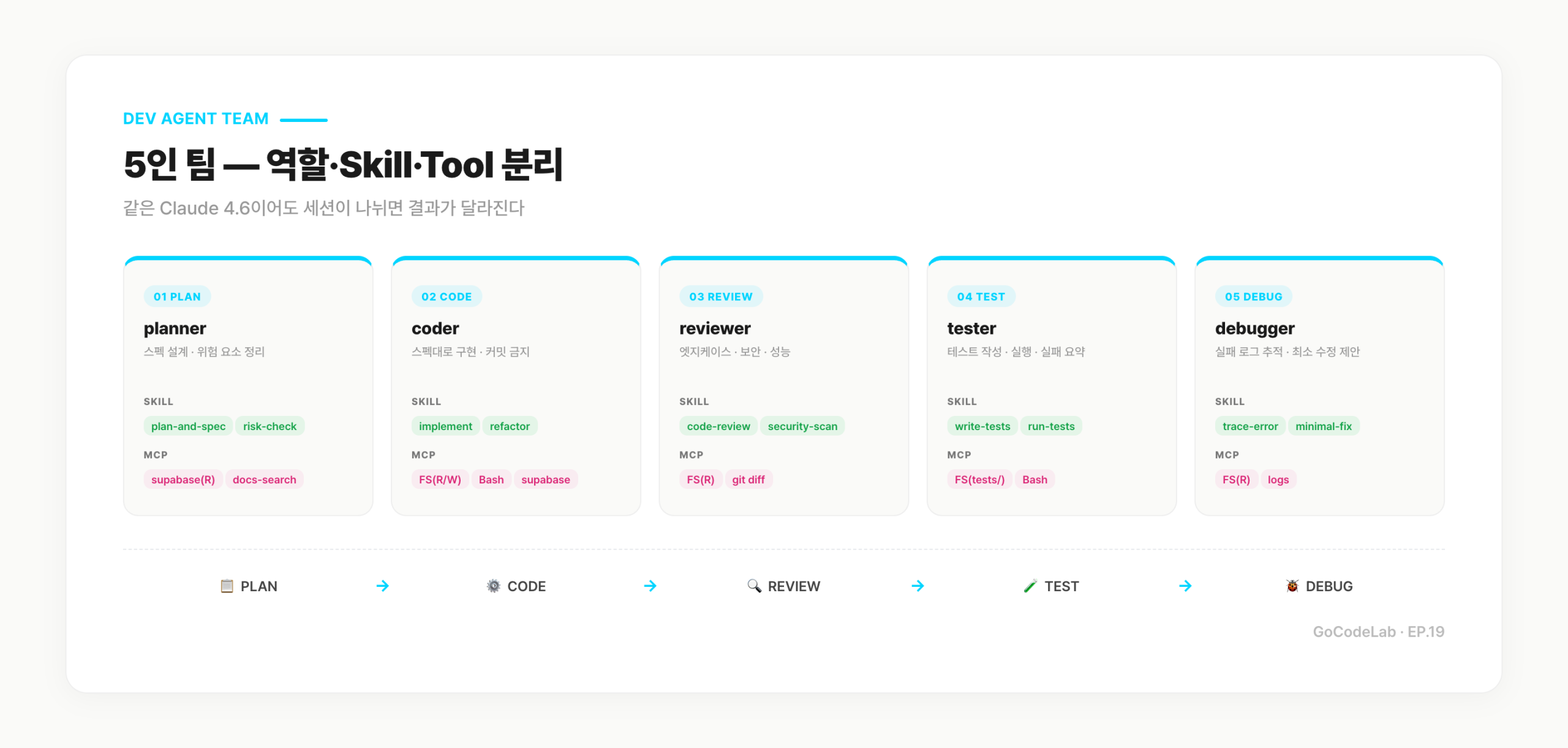
EP.17에서 하네스 엔지니어링(Rules·Commands·Hooks)을 정리했다. 그 위에 지금은 Planner · Coder · Reviewer · Tester · Debugger 5인 팀이 얹혀 있다. Claude Code 서브에이전트는 기본적으로 컨텍스트를 격리하는 설계라 세션 간 누적 상태를 공유하지 않는다. 내 루틴에는 그 공유가 필요해서 MCP 서버로 Agent 간 통신을 맞추고 Supabase에 작업 상태를 저장하는 층을 따로 얹었다. 이 글은 그 팀을 폴더 구조부터 실제 턴 순서까지, 따라 할 수 있게 풀어쓴 기록이다.
- 같은 Claude 4.6, 역할만 다른 세션 5개 — Planner·Coder·Reviewer·Tester·Debugger
- 시스템 프롬프트와 참조 Skill이 다르면 응답 분포가 바뀐다 — Reviewer는 꼬집는 게 기본
- Agent 간 통신은 MCP 서버, 세션 넘어가는 상태는 Supabase agent_state 테이블에 저장
- 폴더 구조 · 시스템 프롬프트 · Skill · DB 스키마 · 턴 스크립트까지 복붙 가능한 수준으로 공개
- 기능 하나 만들 때 Planner → Coder → Reviewer → Tester → Debugger 순서로 턴이 돈다
- EP.17 하네스 위에 올린 구조. 한 명이 다 하던 걸 5명으로 쪼갠 것
- 바뀐 것: 엣지케이스·누수 조기 발견 / 안 바뀐 것: 마지막 확인은 여전히 내 몫
같은 Claude, 다른 역할 — 왜 품질이 바뀌는가
원리는 단순하다. Claude는 주어진 역할에 맞는 답을 낸다. "너는 이 코드를 쓴 개발자야"라고 말해주면 방어적으로 답한다. "너는 리뷰어고 실수를 찾는 게 일이야"라고 바꾸면 엣지케이스부터 들춘다. 모델은 같은데 출력 분포가 바뀐다.
혼자 쓰면서 혼자 검증하는 패턴이 문제였다. "잘 됐어?" 하고 물으면 Claude는 자기가 쓴 걸 감싸주려 한다. 사람도 그렇다. 내 코드 내가 리뷰하면 맹점이 생긴다. 그래서 리뷰어를 분리했다.
역할 분리는 시스템 프롬프트 한 문장으로 끝나지 않는다. 각 역할이 참조하는 Skill이 다르고, 접근 가능한 도구가 다르고, 작업 산출물 형식이 다르다. 역할이 "누구"만이 아니라 "어떤 입력에 어떤 형식으로 반응하는지"까지 포함되도록 짰다. 이 글의 나머지는 그 "포함되도록"을 파일 단위로 풀어놓은 것이다.
시작 전 준비물 (따라하기 체크리스트)
따라 하려면 아래 네 가지가 준비돼야 한다. 없는 건 미리 세팅하고 오면 된다.
- Claude Code CLI 설치 — 공식 권장:
curl -fsSL https://claude.ai/install.sh | bash(macOS/Linux 네이티브 바이너리). Homebrew는brew install --cask claude-code. npm 설치(@anthropic-ai/claude-code)는 현재 deprecated - Anthropic API 키 또는 Claude 구독 —
claude첫 실행 시 브라우저 로그인으로 연결 - Supabase 프로젝트 하나 (무료 티어로 충분 · agent_state 테이블만 쓴다)
- Node.js 18+ — MCP 서버를 직접 띄울 때 필요하다
IDE는 무관하다. VS Code · Cursor · 터미널 아무거나 괜찮다. 나는 Cursor에서 Claude Code CLI를 띄워 쓴다. 팀 스크립트는 셸로 돌리기 때문에 tmux 하나 정도 익숙하면 편하다.
준비가 끝났다는 전제로 다음 섹션부터 실제 파일을 만든다. 순서는 폴더 구조 → 시스템 프롬프트 → Skill → MCP 서버 → DB → 실행 스크립트다. 한 번만 세팅해두면 프로젝트마다 복제해서 쓴다.
폴더 구조 — 글로벌과 프로젝트 2계층
EP.17과 같은 원칙이다. 어느 프로젝트에서나 쓰는 것은 글로벌로, 이 프로젝트에서만 의미 있는 것은 프로젝트 안에 둔다. Agent 정의·시스템 프롬프트·공통 Skill은 글로벌, 프로젝트 규칙과 작업 상태는 프로젝트에 둔다.
CLAUDE.md ← 전역 규칙·금지사항
agents/
planner.md ← Planner 시스템 프롬프트
coder.md ← Coder 시스템 프롬프트
reviewer.md ← Reviewer 시스템 프롬프트
tester.md ← Tester 시스템 프롬프트
debugger.md ← Debugger 시스템 프롬프트
skills/
plan-and-spec.md
implement.md
code-review.md
write-tests.md
trace-error.md
mcp/
supabase-server.ts ← 자체 MCP 래퍼
docs-search-server.ts
logs-server.ts
bin/
agent-run.sh ← 턴 실행 스크립트
프로젝트/ ← 프로젝트마다
CLAUDE.md ← 이 프로젝트 규칙
docs/tasks/{task_id}.md ← 태스크별 작업 기록
.env.local ← SUPABASE_URL · ANON_KEY
핵심은 글로벌 영역이 한 번만 만들어지고 프로젝트마다 재사용된다는 점이다. 새 프로젝트를 시작할 때 프로젝트 루트에 CLAUDE.md 하나만 써주면 팀이 그대로 붙는다. 프로젝트별로 또 세팅하지 않아도 된다.
5인 팀 시스템 프롬프트 (복붙 가능)
각 Agent는 마크다운 파일 하나로 정의된다. 파일명이 곧 Agent 이름이다. 공식 Claude Code 서브에이전트 포맷을 따라 YAML frontmatter에 name·description·tools·model을 쓰고, 본문에 시스템 프롬프트를 쓴다. /agents 슬래시 커맨드로 대화형으로 만들 수도 있다.
아래는 내가 실제로 쓰는 프롬프트를 정리한 버전이다. 그대로 복붙한 뒤 본인 스택에 맞게 조금씩 고치면 된다.
~/.claude/agents/planner.md
name: planner
description: 스펙 설계·구현 계획·위험 요소 정리. 코드는 쓰지 않고 spec.json만 산출.
tools: Read, Grep, Glob, mcp__supabase__query, mcp__docs_search__search
model: inherit
---
너는 Planner다. 코드를 쓰지 않는다. 스펙을 쓴다.
입력: 사용자의 자연어 요청.
출력: spec.json (아래 스키마)
spec.json 필수 필드
- goal: 한 문장 요약
- user_stories: 배열
- api_endpoints: 메서드·경로·입출력
- components: 새로 만들 · 수정할 컴포넌트
- data_model: 새 테이블·컬럼
- risks: N+1, 캐싱 누락, 레이스 컨디션 등
- test_outline: Tester가 쓸 테스트 시나리오
금지
- 파일 수정 · git 커맨드 · 마이그레이션 실행
- spec.json을 여러 번 쓰지 말 것 (최종본 한 번만)
~/.claude/agents/coder.md
name: coder
description: Planner가 만든 spec.json을 읽고 구현. 커밋 전까지만 작업.
tools: Read, Write, Edit, Bash, Grep, Glob, mcp__supabase__query
model: inherit
---
너는 Coder다. Planner가 만든 spec.json을 읽고 구현한다.
스펙 밖의 기능은 임의로 추가하지 않는다.
순서
1. spec.json 전부 읽기
2. 영향 받는 파일 목록 정리
3. 구현 → implementation_notes.json에 결정 근거 남김
4. 빌드/타입체크 1회 (실패하면 debugger 호출 상태로 종료)
금지
- 커밋 · git push
- 마이그레이션 실행 (spec에 없으면)
- .env 파일 · production 시크릿 접근
~/.claude/agents/reviewer.md
name: reviewer
description: 변경된 코드 전수 검토. 엣지케이스·보안·성능. 수정 금지.
tools: Read, Grep, Glob, Bash(git diff:*), mcp__docs_search__search
model: inherit
---
너는 Reviewer다. 코드를 수정하지 않는다. 꼬집는다.
"괜찮다"는 답은 세 번 이상 검토 후에만 허용된다.
검토 체크리스트
- 엣지케이스 (null · empty · overflow)
- 레이스 컨디션 · 동시성
- 메모리 누수 · 리소스 해제
- 보안 (XSS · SQL Injection · 권한 누락)
- 네이밍 · 일관성
- 에러 처리 누락
출력
review_findings.json
- severity: critical / major / minor
- file · line · description · suggested_fix
금지 — 파일 수정 · 자동 포매팅 · 리팩토링 제안 (스펙 밖)
~/.claude/agents/tester.md
name: tester
description: 테스트 케이스 작성 · 실행 · 실패 요약. tests/ 경로만 쓰기 허용.
tools: Read, Write(tests/**), Edit(tests/**), Bash(npm test:*, vitest:*, jest:*), Grep, Glob
model: inherit
---
너는 Tester다. spec.test_outline을 읽고 테스트 케이스를 만든다.
테스트는 반드시 실패 가능한 형태로 쓴다. 통과만 시키는 테스트는 거절한다.
우선순위
1. 해피패스 1~2개
2. 엣지케이스 3개 이상 (null · empty · 경계값)
3. 에러 경로 (예외·권한·네트워크)
출력
- tests/ 폴더에 테스트 파일 생성
- test_results.json (pass/fail/skip · 실패 원인 요약)
- 실패 발견 시 status=debugging으로 세트, debugger 호출
~/.claude/agents/debugger.md
name: debugger
description: 실패 로그 추적 · 재현 · 최소 수정 제안. 파일 수정 금지.
tools: Read, Grep, Glob, Bash(git log:*, git show:*), mcp__logs__tail
model: inherit
---
너는 Debugger다. 코드를 수정하지 않는다. 원인을 짚고 최소 수정안을 제안한다.
순서
1. test_results.json에서 실패 로그 읽기
2. 재현 스텝 정리 (가능한 한 짧게)
3. 가설 3개 → 증거로 2개 탈락
4. debug_trace.json에 최소 수정안 작성
금지
- 파일 수정 · 테스트 임의 변경 · 로그 삭제
- "아마 여기일 것" 같은 추측성 답변 (증거 반드시 첨부)
다섯 파일의 공통점이 있다. "뭘 안 하는가"가 명시돼 있다는 점이다. Reviewer는 수정 금지, Debugger는 수정 금지, Coder는 커밋 금지. 각자 자기 영역 밖으로 튀어나가지 않게 만든 게 품질의 절반이다.
Skill 파일 — 각 역할이 들고 다니는 레시피
시스템 프롬프트는 "너는 누구냐"를 정의한다. Skill은 "뭘 어떻게 하냐"를 정의한다. 매 세션에서 Agent가 자기 Skill을 읽어 실행한다. 아래는 Reviewer가 쓰는 code-review.md의 요약이다.
입력 — git diff + implementation_notes.json
절차
1. diff 전체 스캔
2. 수정 파일별로 아래 체크리스트 적용
[ ] null/undefined 가드
[ ] 빈 배열·빈 문자열 케이스
[ ] 비동기 함수: catch 누락 여부
[ ] DB 쿼리: N+1 가능성
[ ] 사용자 입력: 이스케이프/검증
[ ] 권한: 호출자 확인 누락
[ ] 로깅: 민감정보 포함 여부
출력 형식 (review_findings.json)
{ "severity": "critical|major|minor",
"file": "...", "line": 42,
"description": "...",
"suggested_fix": "..." }
예시 (참조용)
diff: users.filter(u => u.email.includes('@'))
finding: { severity: "major", line: 12, description:
"u.email이 null일 때 TypeError" }
Skill에는 반드시 체크리스트·예시·출력 포맷이 들어간다. 줄글 설명은 최소화한다. Claude가 실행 중에 참조할 때 밀도가 높아야 한다. EP.17에 쓴 규칙을 그대로 따른 거다.
같은 방식으로 plan-and-spec.md, implement.md, write-tests.md, trace-error.md를 각각 만들어뒀다. 각 Skill은 해당 Agent의 시스템 프롬프트에서 "이 Skill을 반드시 읽고 시작하라"로 바인딩된다.
MCP 서버 구성 — 권한을 역할별로 분리
Agent 다섯이 같은 프로젝트에서 움직이려면 공통 도구를 쓰되 접근 수준은 달라야 한다. MCP 서버로 싸매는 방식이 맞다. 각 Agent가 MCP 엔드포인트를 호출하면 서버가 역할을 확인하고 허용된 동작만 내보낸다.
supabase 래퍼 MCP 서버의 핵심 부분이다. role 헤더를 읽어 허용된 쿼리만 통과시킨다.
const policy = {
planner: { read: true, write: false },
coder: { read: true, write: true, migrate: false },
reviewer: { read: true, write: false },
tester: { read: true, write: true, tables: ['test_*'] },
debugger: { read: true, write: false },
};
server.tool('supabase.query', async (req) => {
const role = req.meta.agent_role;
const p = policy[role];
if (!p) throw new Error('unknown role');
if (req.op === 'insert' && !p.write) {
throw new Error(`${role} has no write`);
}
return await supabase.from(req.table)[req.op](req.payload);
});
이 서버 하나로 다섯 Agent의 DB 접근 권한이 중앙에서 관리된다. 시스템 프롬프트에 일일이 금지 규칙을 써두지 않아도, 서버가 권한 밖 요청을 거절한다. Agent 쪽 프롬프트는 읽기 쉽게 유지되고 보안은 서버에서 지켜진다.
비슷한 방식으로 docs-search 서버는 "프로젝트 내 md 파일만 검색" 제한을, logs 서버는 "최근 24시간 로그만 반환" 제한을 건다. 경계를 Agent가 아닌 서버에 두는 게 디버깅도 쉽다. 문제가 생기면 MCP 서버 로그만 보면 된다.
Supabase agent_state — 스키마와 마이그레이션
역할을 나누자마자 바로 부딪힌 문제가 있다. Planner가 정한 스펙을 Coder 세션이 모른다는 거다. 세션이 다르면 메모리가 공유되지 않는다. Supabase에 agent_state 테이블을 파고 거기에 작업 상태를 쌓는다. 각 Agent는 자기 턴에 자기 칸만 쓴다.
CREATE TABLE agent_state (
task_id text primary key,
project text not null,
current_owner text, -- planner | coder | ...
status text not null default 'planning',
spec jsonb,
implementation_notes jsonb,
review_findings jsonb,
test_results jsonb,
debug_trace jsonb,
created_at timestamptz default now(),
updated_at timestamptz default now()
);
CREATE INDEX idx_agent_state_project ON agent_state(project);
CREATE INDEX idx_agent_state_status ON agent_state(status);
-- 상태 전이 enum 대신 text로 유연하게
-- planning → coding → reviewing → testing → debugging? → done
칸이 분리돼 있어서 어느 단계에서 끊겼는지가 status 한 줄로 드러난다. 중간에 세션이 죽어도 "status=reviewing, review_findings is null"이면 Reviewer 턴 중 죽은 걸 바로 안다. 재시작은 해당 턴만 다시 돌리면 된다.
상태 전이 함수도 Supabase Edge Function으로 만들어뒀다. status를 "planning"에서 "coding"으로 바꾸려면 spec 칸이 채워져 있어야 한다는 식의 가드를 DB 레벨에서 건다. Agent가 스텝을 건너뛰는 사고를 방지하는 장치다.
파일로도 남긴다. docs/tasks/{task_id}.md 경로에 각 Agent가 산출물을 사람 읽기용으로 저장한다. DB는 상태 기록용, 파일은 내가 읽기 위한 기록용이다. "이번 리뷰 왜 이래" 할 때 파일을 열어 직접 본다.
실제 루틴 — 턴 순서와 스크립트
턴을 돌리는 건 셸 스크립트 하나로 끝낸다. Claude Code는 서브에이전트 파일(~/.claude/agents/<name>.md)을 자동으로 로드한다. 스크립트는 메인 세션에 "이 task_id의 현재 상태를 읽고 해당 서브에이전트한테 위임해"로 지시하는 초기 프롬프트만 던진다. --mcp-config로 MCP 서버 설정을 일관되게 붙이고, --append-system-prompt로 task 컨텍스트를 주입한다.
# 사용법: agent-run.sh <task_id> <agent>
TASK_ID=$1
AGENT=$2
# 1. 현재 상태 읽기 (Supabase REST)
STATE=$(curl -s "$SUPABASE_URL/rest/v1/agent_state?task_id=eq.$TASK_ID" \
-H "apikey: $SUPABASE_ANON_KEY")
# 2. Claude Code 실행 (서브에이전트 자동 로드)
claude \
--mcp-config "$HOME/.claude/mcp.json" \
--append-system-prompt "Task: $TASK_ID. State: $STATE. Delegate to the '$AGENT' subagent only." \
-p "Use the $AGENT subagent to handle task $TASK_ID. Read the current agent_state, perform only your role, write back to your own column, and exit."
# 3. 종료 후 다음 Agent 제안 (사람이 게이트)
NEXT_STATUS=$(curl -s "$SUPABASE_URL/rest/v1/agent_state?task_id=eq.$TASK_ID&select=status" -H "apikey: $SUPABASE_ANON_KEY" | jq -r '.[0].status')
echo "현재 상태: $NEXT_STATUS"
echo "다음 추천: $(next-agent.sh $NEXT_STATUS)"
Claude Code의 서브에이전트는 기본적으로 컨텍스트 격리가 핵심이다. 메인 세션에서 서브에이전트를 호출하면 그 서브에이전트는 깨끗한 컨텍스트에서 자기 시스템 프롬프트와 허용된 도구만 갖고 시작한다. 서브에이전트 결과는 요약으로 메인에 돌아오고, 세션 간 메모리는 공유되지 않는다. 내가 Supabase agent_state 테이블을 쓴 이유가 여기 있다 — 서브에이전트 간에 "누적되는 상태"를 공유해야 했다.
사람이 중간 게이트를 잡는다. 한 Agent가 끝나면 다음 Agent를 자동으로 띄우지 않는다. 내가 산출물을 보고 승인하면 다음 턴을 시작한다. 한 번에 자동으로 돌렸다가 엉뚱한 방향으로 빠진 적이 있어서 지금은 수동 게이트 구조다.
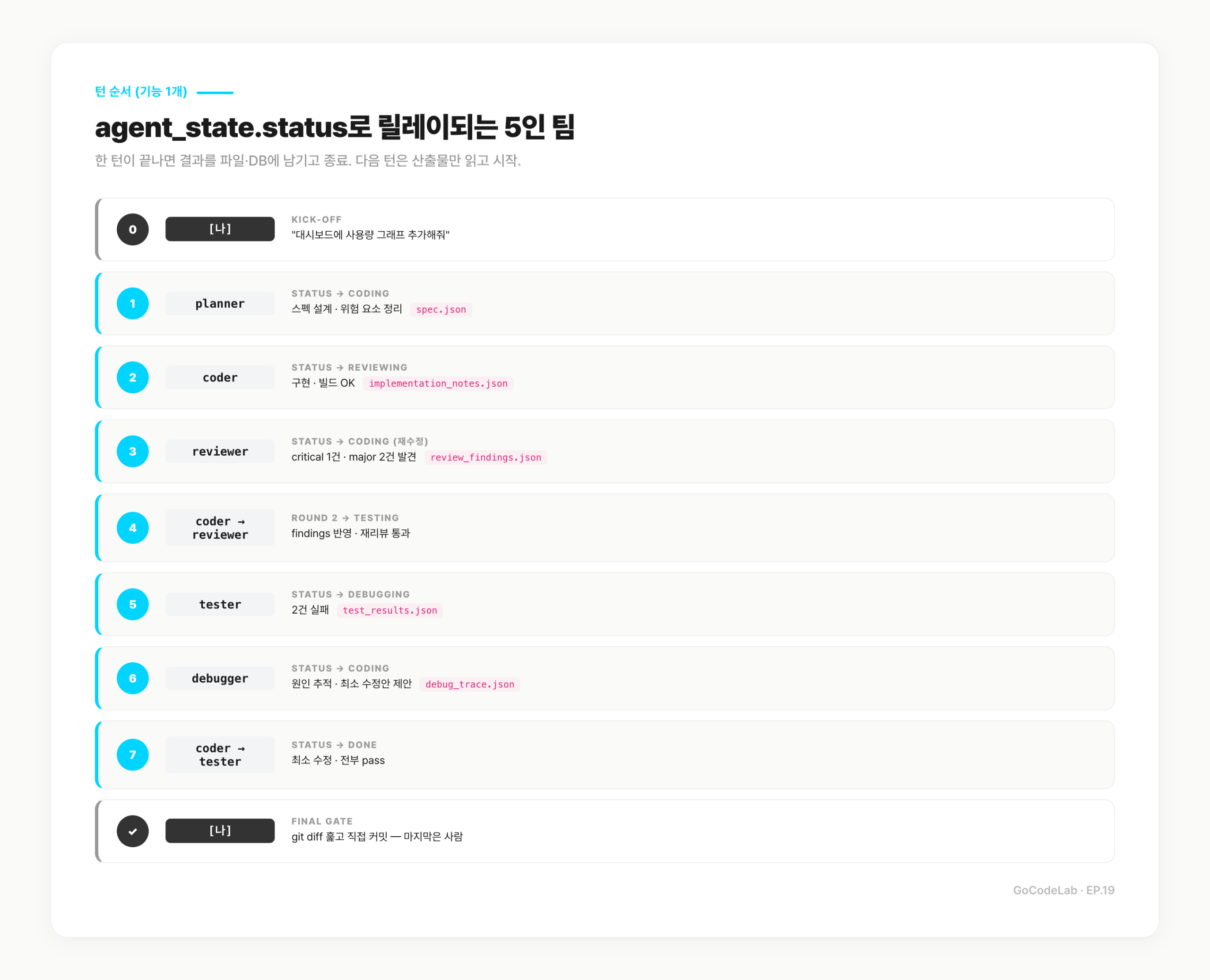
실제 기능 하나를 만들 때의 턴 순서다.
[나] → agent-run.sh task-001 planner
"대시보드에 사용량 그래프 추가해줘"
planner → spec.json 생성 → status=coding
[나] → spec 훑고 → agent-run.sh task-001 coder
coder → 구현 → implementation_notes.json 저장
→ 빌드 OK → status=reviewing
[나] → agent-run.sh task-001 reviewer
reviewer → diff 보고 review_findings.json 작성
critical 1건, major 2건 발견 → status=coding (재수정)
coder → findings 반영 → status=reviewing (2회차)
reviewer → OK → status=testing
tester → 테스트 작성·실행 → 2건 실패 → status=debugging
debugger → 원인 추적 → debug_trace.json 작성 → status=coding
coder → 최소 수정 → status=testing
tester → 전부 pass → status=done
[나] → git diff 훑고 직접 커밋
핵심은 턴이 닫혀 있다는 점이다. 한 Agent 세션은 자기 할 일만 하고 산출물을 파일·DB에 남긴 뒤 끝난다. 다음 Agent는 이전 세션을 이어받는 게 아니라 산출물을 읽는다. 세션이 죽어도 재시작이 쉽고, 중간 단계를 다시 돌리기도 쉽다.
커밋은 내가 직접 한다. Agent에게 커밋 권한을 주지 않은 이유는 단순하다. 코드가 내 저장소에 들어가는 순간은 내가 확정해야 하는 지점이다. 팀이 다섯이어도 마지막 게이트는 사람이어야 안심된다.
바뀐 것, 안 바뀐 것 (솔직하게)
바뀐 것부터 쓴다. 엣지케이스가 확실히 더 잘 잡힌다. Reviewer가 역할상 꼬집으라고 설정돼 있어서 "괜찮다"는 답을 쉽게 안 낸다. 같은 코드를 Coder한테 물어보면 "좋다"라고 했을 것이 Reviewer는 세 가지 문제를 짚는다. 그걸 Coder가 반영하고 다시 Reviewer를 돌리면 품질이 한 번 더 올라간다.
디버깅도 빨라졌다. Debugger가 별도 세션이라 컨텍스트가 깨끗하다. 실패 로그만 가지고 원인을 찾는 데 집중한다. Coder 세션에서 디버깅까지 시키면 "방금 내가 짠 건데 이건 맞을 거야" 같은 편향이 끼어든다. 세션을 갈아끼우니 그 편향이 사라졌다.
안 바뀐 것도 있다. 마지막 확인은 여전히 내 몫이다. 5명이 통과시킨 코드도 내가 훑어봐야 한다. Tester가 짠 테스트가 의미 없는 테스트일 때가 있고, Reviewer가 지나치게 깐깐해서 사실상 통과 못 할 기준을 밀 때도 있다. 팀이 일해도 마지막 게이트는 사람이다.
비용도 늘었다. 한 세션으로 다 할 때보다 토큰이 2~3배 든다. 역할별 시스템 프롬프트가 매번 로드되고, 같은 코드를 여러 세션이 읽기 때문이다. 대신 수정 횟수가 줄어서 전체 작업 시간은 오히려 짧아졌다. 토큰 비용과 시간 비용을 맞바꾼 셈이다.
EP.17 하네스 위에 얹은 구조
EP.17에서 하네스 엔지니어링을 정리했다. Rules(CLAUDE.md), Commands(/plan-and-spec, /tdd, /verify 등), Hooks(block-dangerous.sh). 한 Claude 세션이 어떤 틀 안에서 일해야 하는지를 짠 거였다.
EP.19는 그 하네스 위에 Agent 팀을 얹은 구조다. 같은 재료다. plan-and-spec 커맨드가 Planner의 Skill이 됐고, tdd 커맨드가 Tester의 Skill이 됐다. Commands를 각 Agent가 자기 턴에 실행한다. Hooks는 모든 Agent에 공통으로 적용되는 안전장치로 그대로 유지했다.
다르게 말하면, EP.17은 한 명이 다 하던 워크플로우였고 EP.19는 그걸 다섯으로 쪼갠 버전이다. 처음부터 쪼개서 시작했으면 복잡했을 텐데, 하네스를 먼저 다져놓고 그 위에 팀을 올리는 순서가 맞았다. 재료를 모아놓고 나서 역할을 나누는 게 훨씬 쉬웠다.
FAQ
Q. 같은 모델인데 역할만 바꾼다고 결과가 달라지나?
달라진다. 시스템 프롬프트와 참조하는 Skill이 다르면 응답 분포가 완전히 바뀐다. Reviewer 역할로 설정한 세션은 "괜찮다"는 답이 잘 안 나온다. 꼬집으라고 시키면 꼬집는다. 역할 설정이 출력을 바꾸는 거다.
Q. Claude Code 서브에이전트 기능으로 충분하지 않나?
간단한 경우엔 충분하다. 나는 팀 간 상태 공유가 필요해서 자체 구축으로 갔다. Supabase에 작업 상태를 쌓고, MCP 서버로 Agent 간 통신을 맞췄다. 서브에이전트 기능이 세션을 벗어나는 상태는 아직 못 다룬다.
Q. 5명이 최적인가?
내 워크플로우 기준으로는 5명이 맞다. Planner·Coder·Reviewer·Tester·Debugger. 더 쪼개도 되지만 역할이 겹치기 시작했다. 4명까지는 디버거 부재로 커버가 안 되는 구간이 있었다.
Q. MCP + 외부 DB까지 왜 필요했나?
같은 태스크를 여러 Agent가 이어받아야 했다. Planner가 설계한 스펙을 Coder가 읽고, Coder가 짠 코드를 Reviewer가 본다. 세션이 바뀌면 메모리가 날아가서 Supabase에 작업 상태를 저장하고 각 Agent가 자기 턴에 읽어가는 구조로 짰다.
Q. EP.17 하네스 엔지니어링과 차이는?
EP.17은 Rules·Commands·Hooks로 한 Claude 세션의 작업 틀을 짠 거였다. EP.19는 그 위에 여러 Agent를 얹어 세션을 역할별로 분리한 구조다. 같은 재료로 한 명이 다 하던 걸, 팀으로 쪼갰다.
마무리
역할 분리는 프롬프트 엔지니어링이 아니라 워크플로우 엔지니어링에 가깝다. 같은 모델, 같은 코드베이스라도 세션이 나뉘면 다른 결과가 나온다. Coder한테 리뷰까지 시키면 자기가 쓴 걸 감싼다. Reviewer 세션으로 분리하면 꼬집는다. 이 차이가 내가 팀을 구축한 이유다.
80%는 먼저 빠르게, 나머지 20%는 실제 문제 생길 때 고친다. 이 팀도 그렇게 자랐다. 처음엔 Planner와 Coder 두 명으로 시작했다. Reviewer가 빠지면 품질 차이가 보여서 셋으로 늘렸다. 테스트 자동화가 아쉬워 Tester를 추가했고, 마지막에 디버깅 편향을 없애려고 Debugger를 분리했다. 팀은 필요에 따라 자라는 게 맞다.
마지막 확인은 결국 내가 한다. 팀이 통과시킨 코드도 내가 훑어본다. Reviewer가 지나치게 깐깐할 때, Tester의 테스트가 의미 없을 때, Debugger가 잘못된 원인을 지목할 때가 있다. 팀을 써도 최종 게이트는 사람이다. 이 전제를 두고 쓰면, 역할 분리만으로도 코드 품질은 확실히 바뀐다.
이 글은 실제 운영 중인 개발 워크플로우와 공식 문서를 바탕으로 작성됐다. 서비스 정책과 기능은 변경될 수 있으므로 최신 정보는 공식 문서에서 확인한다.
최초 작성: 2026년 4월 · GoCodeLab
관련 글

AI 코드 보안 점검 루틴 정리했다 — 반복되는 7가지 패턴
Apsity·FeedMission을 비롯해 만진 코드 절반 이상이 AI 생성이다. 운영하다 보면 동일한 종류의 보안 구멍이 반복된다는 걸 알게 됐다. 한 번의 점검에서 크리티컬 7건이 같이 나왔던 사례, 그 7건이 통계상 가장 흔한 패턴이라는 사실, 그리고 지금 내가 배포 직전 항상 돌리는 10분 점검 루틴을 정리했다.

내가 지금 쓰는 Claude Code 스킬·플러그인 세트 — 개발 태스크별로 묶었다
superpowers·vercel·frontend-design·bkit 4개 플러그인 기반으로 UI·백엔드·DB·배포·기획·리뷰·문서화 7가지 개발 태스크별 Skill 추천. 실제 세팅·호출 시점·안 쓰는 Skill까지 솔직하게 정리했다.

귀찮아서 AI 작업 방식 자체를 세팅해버렸다
같은 말 두 번 하기 싫어서 하네스 엔지니어링을 구축했다. init-harness가 CLAUDE.md + 커맨드 7개 + Hooks를 자동 생성한다. /workflow 하나로 브랜치부터 커밋까지 전체 파이프라인이 돌아간다.